u1.04.00 Méthodes de lancement de calcul code_aster#
Résumé :
Ce document présente les différentes façons de lancer une étude sur code_aster, telles que AsterStudy, astk, run_aster, run_ctest et run_sbatch.
Toutes les méthodes sont décrites en termes de logique de fonctionnement, leurs avantages et leurs inconvénients. Plus précisément, nous décrivons leurs interfaces graphiques ou leurs approches en ligne de commande, et expliquons comment l’utilisateur peut lancer une étude en fonction de ses besoins.
- Remarque :
Notez que certaines méthodes sont déjà contenues dans d’autres méthodes. Par exemple, AsterStudy utilise la commande run_aster ou run_sbatch. De même, astk utilise la commande de bas niveau as_run pour lancer un calcul. Il n’est pas recommandé d’utiliser as_run directement, c’est pourquoi nous ne donnerons pas de détails sur cette commande ici.
Utilisation de l’interface AsterStudy#
Comment lancer un calcul ?#
De manière très simplifiée, il convient d’abord définir les différents stages à faire dans l’onglet CaseView (via Operations/Add stage). Il existe aussi la possibilité d’importer un cas-test en cliquant Operations/Import Testcase.
Pour des informations plus détaillées, visitez la formation code_aster - salome_meca.
Une fois cette étape accomplie, on va dans l’onglet History View afin de fournir les paramètres de simulation. Finalement, on sélectionne le CurrentCase et on clique sur le bouton Run (voir figure ci-dessous).
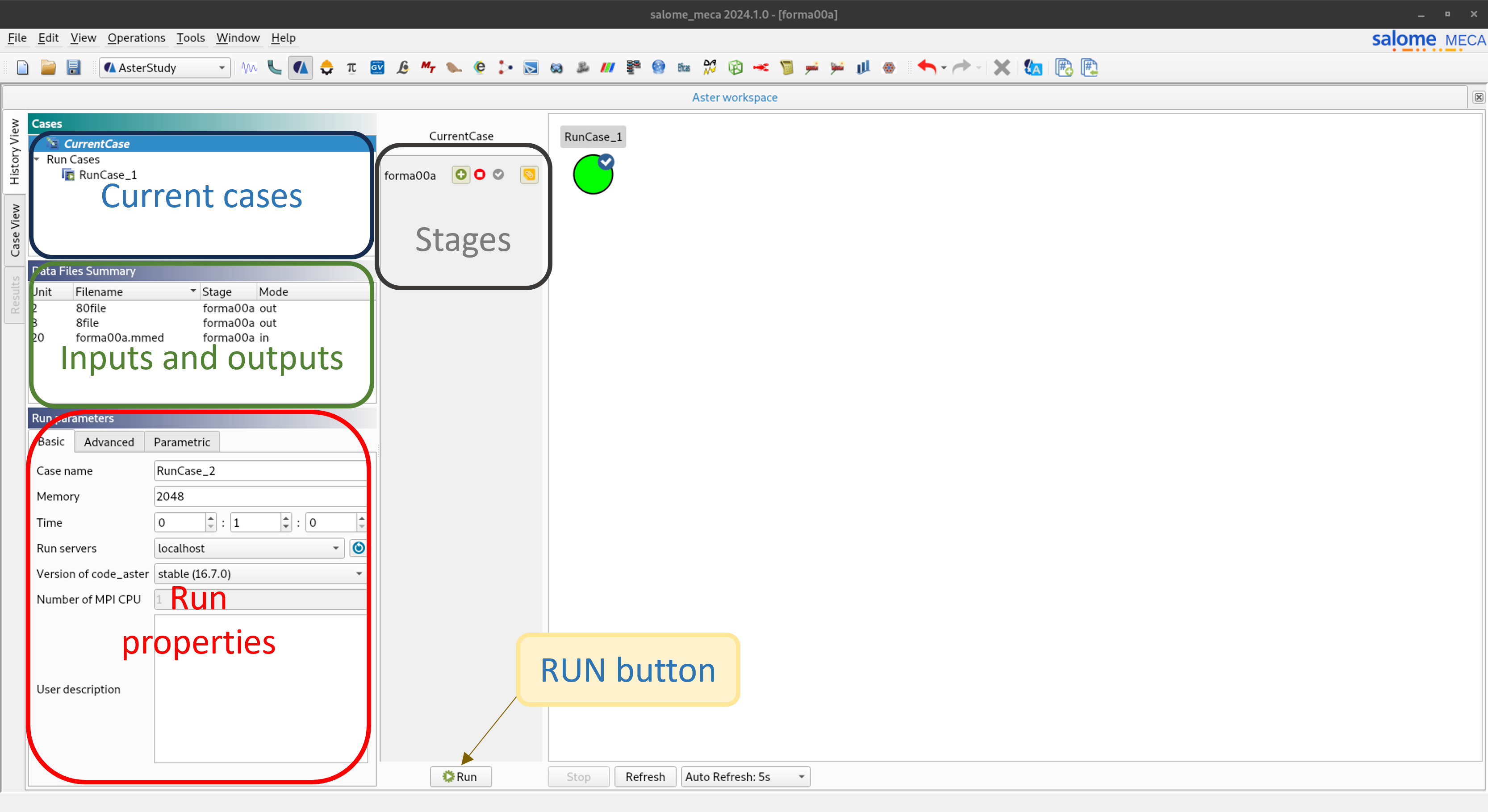
Fig. 1 Fenêtre de History View dans Asterstudy#
- Remarque :
Dans AsterStudy nous avons la possibilité de choisir la machine à exécuter (p.ex. local, cronos, gaia) ainsi que la version code_aster disponible sur chaque machine (p.ex. stable, dev, etc.).
Run properties#
Dans la fenêtre Run properties de l’onglet History View, nous pouvons fournir à salome_meca les paramètres de lancement.
Basic#
Memory : équivalent à memory_limit du fichier export. Mémoire en Mo pour le calcul aster
Time : équivalent à time_limit. Temps du travail soumis
Run servers : le serveur local ou distant disponible
Version of code_aster : les versions installées dans le serveur sélectionné
Number of MPI CPU : équivalent à mpi_nbcpu. Nombre total de processeurs pour le parallélisme MPI.
Advanced#
Parmi les options les plus utilisées :
Run mode : interactif ou console
Number of MPI nodes : équivalent à mpi_nbnoeud. Nombre de noeuds pour le parallélisme MPI
Number of threads : Nombre de threads pour le parallélisme OpenMP.
Récupération des résultats#
En cas de réussite#
Si la simulation se termine sans problème majeur, AsterStudy copiera les différents fichiers de résultats depuis le dossier /tmp et les collera dans l’emplacement donné au préalable. De plus, il créera un dossier de nom <nom du fichier hdf>_Files où l’on pourra trouver les logs, les messages, etc., de chaque RunCase.
En cas d’échec#
Lorsqu’une erreur se produit pendant un calcul, il est possible de récupérer les fichiers de calcul déjà créés (.rmed, .txt, logs, etc.). Sur une machine locale, ce répertoire se trouve normalement à l’emplacement /tmp (ou /local00/tmp/). Sur les serveurs cronos et gaia, l’accès au répertoire est restreint.
Par construction, même en cas d’erreur fatale, AsterStudy copiera les résultats intermédiaires dans le répertoire spécifié par l’utilisateur. Si l’utilisateur souhaite analyser la cause de l’erreur, il peut consulter les logs qui se trouvent dans le répertoire /logs sur l’arborescence de l’étude lancée ou dans le répertoire /tmp.
- Remarque :
Le fichier tmp est situé à /local00/tmp/ parce que c’est le chemin par défaut. Pour le modifier, il faudrait changer le fichier $HOME/.astkrc/config_servers.
Utilisation de l’interface Astk#
Astk est l’interface graphique qui permet d’organiser les calculs code_aster : préparer les données, organiser les fichiers, accéder aux outils de pré et post-traitement, lancer et suivre l’évolution des calculs. Astk permet également de choisir la version de code_aster à utiliser parmi celles disponibles (stable, testing, etc.).
Comment y accéder ?#
Il existe deux façons d’ouvrir Astk :
Dans le conteneur salome_meca, il faut cliquer sur Tools/Plugins/code_aster/Run astk.
En ligne de commande, il faut exécuter dans le terminal de salome :
Astk
- Remarque :
Pour plus d’informations sur l’accès au terminal de salome_meca, consultez Notions générales.
Configuration#
La première fois que l’utilisateur lance l’interface, il dispose d’une configuration par défaut qui a été définie lors de l’installation. La configuration est ensuite stockée dans le répertoire $HOME/.astkrc.
Si l’utilisateur veut revenir à la configuration d’origine, il doit effacer ce répertoire et relancer Astk.
Dans les paragraphes suivants, on ne détaille que le menu Serveurs.
Serveurs#
On accède à la fenêtre serveurs en cliquant sur Configuration/Serveurs.
Le premier bouton permet de passer d’un serveur à un autre et d’ajouter un «Nouveau serveur». Les champs sont :
Nom complet ou adresse IP: il s’agit du nom du serveur sur le réseau ; on peut indiquer son nom complet avec le nom de domaine (par exemple: linux.labo.univ.fr) ou son adresse IP (par exemple: 156.98.254.36).
La case « machine locale » indique qu’Astk ne doit pas utiliser ssh pour contacter cette machine.
État du serveur : on peut mettre sur «off» un serveur temporairement inaccessible.
Login : identifiant avec lequel on se connecte au serveur.
Répertoire HOME : répertoire par défaut lorsque l’on navigue sur cette machine.
Répertoire des services : répertoire où sont installés les services sur ce serveur (indiquer le chemin d’installation, par exemple: /opt/aster), laisser vide pour un serveur de fichiers.
Mode de téléchargement de la configuration: aucun (pour un serveur de fichiers), manuel (il faut cliquer sur le bouton «Télécharger maintenant» pour récupérer la configuration Aster du serveur), automatique (Astk interroge le serveur au démarrage tous les 30 jours).
Dernier téléchargement : date de la dernière mise à jour des informations de configuration.
Terminal : commande pour ouvrir un terminal sur le serveur. Ceci permet d’ouvrir une fenêtre de commandes sur le serveur quand on utilise la bsf.
Editeur : éditeur texte (par exemple, nedit). La procédure d’installation choisit un éditeur parmi (et dans cet ordre): nedit, gedit, xemacs, emacs, xedit, vi.
- Remarque :
A chaque fois que l’on définit une commande à exécuter (terminal, éditeur, etc.), il est conseillé d’indiquer le chemin absolu (depuis la racine) pour éviter que la commande ne soit pas trouvée si la variable $PATH est incorrecte.
Pour les utilisateurs ayant accès aux serveurs EDF R&D, il faudra mettre à jour les informations dans l’onglet Configuration/Serveurs en cliquant sur le bouton Rafraichir maintenant.
Comment faire lancer un calcul ?#
Dans ce paragraphe et les suivants, on décrit de manière générale comment utiliser Astk pour réaliser une étude.
Supposons que l’on veut lancer l’étude du cas-test forma00a dont les éléments à disposition sont :
Le fichier de commande Aster : forma00a.comm
La description de la géométrie réalisée avec Salomé : forma00a.datg
Le maillage construit par Salomé : forma00a.mmed
Le fichier contenant les messages d’exécution : forma00a.mess
Dans l’exemple, tous les fichiers sont placés dans le répertoire $HOME/.
Les fichiers de cet exemple sont disponibles dans le répertoire astest de votre version de code_aster.
- Remarque :
Dans le cas d’une étude avec plusieurs fichiers de commande, tous les fichiers doivent être de type «comm», associés à l’unité logique 1 et c’est l’ordre d’apparition dans le profil qui détermine l’ordre d’exécution.
Création du profil#
On lance l’interface qui s’ouvre sur un profil vierge, ou bien si Astk est déjà lancé, on choisit Fichier/Nouveau dans le menu pour créer un nouveau profil vide.
On se place dans l’onglet ETUDE.
Sélection des fichiers#
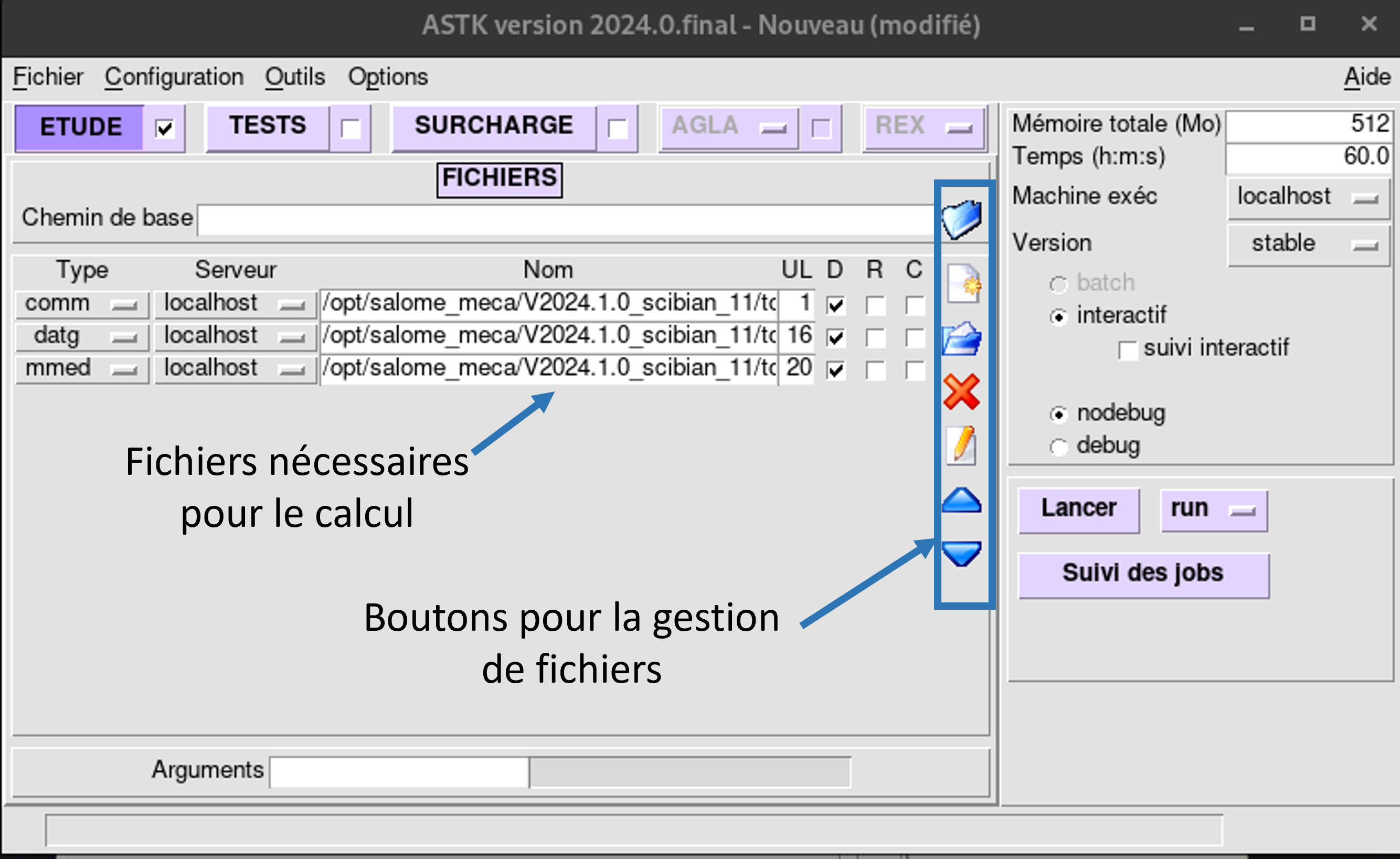
Définition d’un chemin de base
Dans l’onglet ETUDE, on choisit un chemin de base pour simplifier l’accès aux fichiers. On clique sur l’icône  , on choisit le répertoire $HOME/.
, on choisit le répertoire $HOME/.
Ajout de fichiers existants
On ajoute le fichier de commandes en cliquant sur  , la sélection de fichier s’ouvre directement dans le chemin de base que l’on vient de définir. Il ne reste qu’à sélectionner le fichier pour qu’il apparaisse dans la liste.
, la sélection de fichier s’ouvre directement dans le chemin de base que l’on vient de définir. Il ne reste qu’à sélectionner le fichier pour qu’il apparaisse dans la liste.
Ajout de fichiers pas encore existants
Sauf si une exécution a déjà eu lieu, les fichiers résultats n’existent pas encore, on ne peut donc pas les ajouter en parcourant l’arborescence.
en insérant une ligne vide :
en cliquant sur le bouton de nouveau fichier  , une ligne est ajoutée dans la liste. Par exemple, on peut choisir le type «mess» dans la liste pour imprimer les messages lors de l’exécution. Puis, on indique le chemin $HOME/forma00a.mess ou forma00a.mess ou ./forma00a.mess (puisqu’il est possible d’indiquer le nom du fichier en absolu ou relatif par rapport au chemin de base). Finalement, on remplit le numéro d’unité logique (par défaut égal à 6) et on coche la case «R» (résultat) et on décoche «D».
, une ligne est ajoutée dans la liste. Par exemple, on peut choisir le type «mess» dans la liste pour imprimer les messages lors de l’exécution. Puis, on indique le chemin $HOME/forma00a.mess ou forma00a.mess ou ./forma00a.mess (puisqu’il est possible d’indiquer le nom du fichier en absolu ou relatif par rapport au chemin de base). Finalement, on remplit le numéro d’unité logique (par défaut égal à 6) et on coche la case «R» (résultat) et on décoche «D».
avec «Valeur par défaut» :
Cette fonction utilise le nom du profil Astk pour construire les valeurs par défaut. Il faut donc enregistrer le profil, si ce n’est pas encore fait. On choisit Enregistrer sous dans le menu Fichier , on va avec le navigateur dans le répertoire de référence, et dans la ligne Sélection , on écrit par exemple forma00a (l’extension .astk est automatiquement ajoutée). On insère une ligne vide et on choisit le type de fichier «mess», puis on clique avec le bouton droit dans la case du nom de fichier et on choisit «Valeur par défaut»: Astk construit un nom de fichier à partir du chemin de base, du nom de profil (en retirant l’extension) et du type «mess», soit $HOME/forma00a.mess. La case «R» a été cochée, et le numéro d’unité logique fixé à 6.
Supprimer un fichier
Pour supprimer une ligne de la liste des fichiers, il suffit de la sélectionner en cliquant dans la zone où l’on indique le nom du fichier et de cliquer sur l’icône  . Il faut remarquer que seule la référence à ce fichier dans le profil Astk est oubliée, le fichier lui-même n’est pas effacé.
. Il faut remarquer que seule la référence à ce fichier dans le profil Astk est oubliée, le fichier lui-même n’est pas effacé.
Lancement du calcul#
Les fichiers données et résultats sont sélectionnés, on ajuste les paramètres du calcul, et on clique sur le bouton «Lancer».
On prend soin de cocher la case qui se trouve juste à côté de ETUDE pour signaler que l’on souhaite utiliser le contenu de cet onglet, sinon l’interface nous répond «Rien à lancer!».
Si le profil n’a pas encore été enregistré, l’interface demande de choisir un endroit et un nom pour ce profil.
Astk appelle as_run pour exécuter le calcul, et transmet au Suivi des jobs (asjob) le numéro du job (numéro du processus en interactif) et d’autres informations qui vont permettre de suivre l’avancement du calcul. L’état initial du calcul est PEND (en attente), quand le calcul commence, il devient RUN, puis ENDED quand il est terminé (d’autres états sont possibles en batch). Le bouton «Actualiser» appelle le service qui rafraîchit l’état des calculs en cours.
Quand le calcul est terminé, on peut consulter le résultat du job en double-cliquant sur le job, ou par Editer/Fichier output.
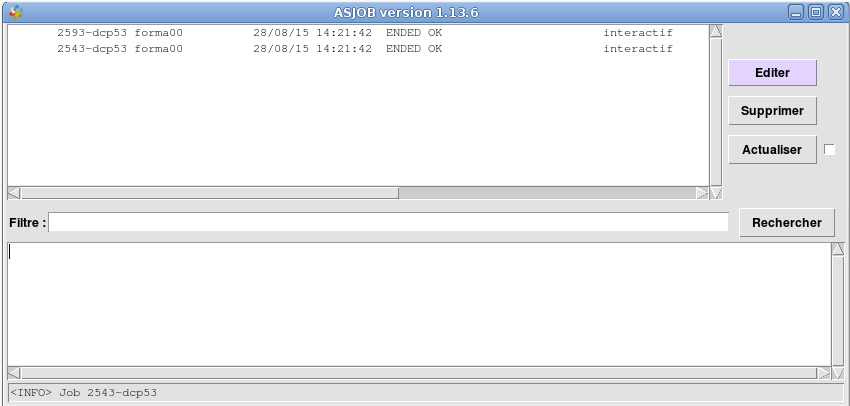
Figure 5.3-1: Fenêtre de suivi des jobs
Consultation des résultats#
On peut consulter les fichiers résultats simplement en double-cliquant sur leur nom, ce qui ouvre un éditeur de texte pour les fichiers «mess» et «resu».
- Remarque :
Le répertoire devant accueillir un fichier résultat n’existe pas, il est automatiquement créé si les permissions sont suffisantes.
Si la copie de fichiers résultats échoue (problème de permissions, de quota, de connexion distante…), ils sont copiés dans un répertoire temporaire sur la machine d’exécution. Une alarme <A>_COPY_RESULTS indique le chemin où il faut aller chercher les résultats.
Récupération des résultats#
En cas de réussite#
Si la simulation se termine sans problème majeur, Astk copiera les différents fichiers de résultats depuis le dossier /tmp et les collera dans l’emplacement indiqué précédemment.
En cas d’échec#
De la même manière que AsterStudy, lorsqu’une erreur se produit pendant un calcul, il est possible de récupérer les fichiers de logs du terminal, qui contiendront des informations supplémentaires (afin d’analyser la cause de l’erreur) selon l’option verbose choisie.
Dans ce cas-là, il existe deux répertoires à tenir en compte : le flasheur et le tmp. Sur une machine locale, le répertoire flasheur se trouve normalement à l’emplacement $HOME/flasheur/, tandis que le répertoire temporaire tmp est situé à /local00/tmp/. Sur les serveurs cronos et gaia, les utilisateurs n’ont accès qu’au répertoire flasheur (situé également à $HOME/flasheur/), l’accès au répertoire tmp étant restreint.
Une distinction importante à noter : les fichiers dans flasheur et tmp peuvent varier en fonction du nombre de nœuds ou de processeurs utilisés. Par exemple, si deux nœuds sont impliqués dans le calcul, les informations dans le répertoire tmp peuvent être dupliquées et moins bien structurées, ce qui peut compliquer leur analyse.
- Remarque :
Le fichier tmp est situé à /local00/tmp/ parce que c’est le chemin par défaut. Pour le modifier il faudrait changer le fichier $HOME/.astkrc/config_servers.
Utilisation des commandes run_aster, run_sbatch et run_ctest#
Contrairement à astk et as_run qui permettent d’adresser différentes versions de code_aster, run_aster et run_sbatch ne lancent que leur propre version. Il y a donc un script run_aster (et run_sbatch) par version.
Utiliser run_aster est la méthode recommandée pour lancer un calcul code_aster sur le serveur local, et run_sbatch est la meilleure option sur les serveurs à distance.
Comment lancer un calcul ?#
Commande run_aster#
Sur le serveur local#
En local, seul run_aster est accessible (run_sbatch n’est pas disponible car il n’y a pas de gestionnaire de batch en général).
Pour lancer les exécutables sur le serveur local, il faut d’abord se placer dans le terminal du conteneur. Une fois dedans, pour lancer l’étude d’un seul calcul, il faut exécuter :
run_aster [options] file[.export|.py]
Ici, run_aster est un alias vers /opt/salome_meca/V<version>/tools/code_aster<version>/bin/run_aster. Il suffit de choisir le script run_aster de la version que l’on souhaite exécuter.
Pour les développeurs, le chemin de l’exécutable sera fréquemment $HOME/dev/codeaster/install/mpi/bin/run_aster.
Il est possible de récupérer les informations du terminal lors de la compilation en faisant :
run_aster [options] file[.export|.py] > path_to_output_file
Si besoin, il est possible d’afficher l’aide de run_aster en faisant :
run_aster --help
Sur les serveurs à distance#
Tout d’abord, il faut se connecter au serveur à distance via ssh :
ssh NNI@ssh.hpc.edf.fr
Sur les serveurs d’EDF R&D, il est obligatoire de lancer les calculs sur les noeuds de calcul en batch (et donc avec run_sbatch) et pas sur la frontale.
- Remarque :
run_aster s’exécute directement, il ne faut donc pas l’utiliser sur la frontale.
Commande run_sbatch#
Cette commande sert à exécuter code_aster sur le serveur à distance. La manière plus simple de faire est la suivante :
run_sbatch --wckey=$SBATCH_WCKEY [options] file[.export|.py]
Ici run_sbatch est un alias pour l’exécutable <SIMUMECA_INSTALL_DIR>/aster/install/<version>/bin/run_sbatch. Il suffit de choisir le script run_sbatch de la version que l’on souhaite exécuter.
Dans ce contexte, la clé $SBATCH_WCKEY est à demander à votre responsable du projet.
Pour en savoir plus sur les autres options de lancement, la commande disponible est :
run_sbatch --help
Une option recommandée est « –dry-run », qui permet de créer et de lire le script de soumission. Cela permet aux utilisateurs de valider les paramètres de calcul avant de le lancer. Voici un extrait de ce qu’on pourrait lire :
#!/bin/bash
#SBATCH --job-name=myfile
# number of nodes
#SBATCH --nodes=1
# number of MPI processes
#SBATCH --ntasks=1
# number of threads per MPI process
#SBATCH --cpus-per-task=1 --threads-per-core=1
# max walltime
#SBATCH --time="01:00:00"
# memory in MB
#SBATCH --mem=11596M
# add `--exclusive` if several nodes, define `--partition=...`
#SBATCH
Commande run_ctest#
Cette commande sert à lancer un ou plusieurs cas-tests.
Sur le serveur local#
Il faut exécuter :
run_ctest --testlist=file[.txt] --resutest=folder [options]
Par similitude, ici run_ctest est un alias pour l’exécutable /opt/salome_meca/V<version>/tools/code_aster<version>/bin/run_ctest (qui peut changer en fonction de la version installée).
Pour les développeurs, le chemin de l’exécutable sera fréquemment $HOME/dev/codeaster/install/mpi/bin/run_ctest.
- Remarque :
En local, la commande run_ctest exécute de manière linéaire le calcul des cas-tests dont le nom est dans le fichier file.txt (un cas-test après l’autre).
Dans un serveur à distance, run_ctest exécute les calculs en parallèle (un job pour chaque cas-test).
Dans cet exemple, le fichier file.txt contient les noms des fichiers export à exécuter. Par exemple :
sdls118a
sdls118b
sdls118c
sdls118d
sdls118e
sdnx100g
Finalement, l’option resutest permet de changer le répertoire des résultats des cas-tests.
Pour plus de détails sur les autres options disponibles, il faut exécuter sur le terminal :
run_ctest --help
Sur les serveurs à distance#
De manière très similaire au cas du serveur local, on exécute run_ctest par cette ligne de commande :
run_ctest --wckey=$SBATCH_WCKEY --testlist=file[.txt] --resutest=folder [options] --sbatch
où on indique la clé WCKEY et l’option sbatch afin de lancer les différents cas-tests dans des jobs différents avec slurm.
Exemple : Utiliser des modules Python dans un fichier export#
Supposons que l’arborescence de notre projet soit :
project
├── mesh_file.mmed
├── command_file.comm
├── export_file.export
├── src
│ ├── __init__.py
│ └── python_file.py
Le fichier export, qui contient les informations pour l’exécution de l’étude, est de la forme :
P actions make_etude
P time_limit 60
P memory_limit 512
P ncpus 1
P mpi_nbcpu 1
P mpi_nbnoeud 1
P version stable
F comm command_file.comm D 1
F mmed mesh_file.mmed D 20
À ce fichier export, il faudrait rajouter une ligne pour indiquer le chemin du dossier à considérer lors du calcul. En fonction du cas, cette ligne peut être :
Quand on utilise run_aster :
R nom chemin_du_src D 0
Quand on utilise astk:
R repe chemin_du_src D 0
La différence entre ces deux cas est due au fait qu’astk, jusqu’à la version 17.2 de code_aster, restreint le type nom pour des fichiers. Le type à utiliser est alors repe. De ce fait, il faut aussi adapter la façon d’appeler les fonctions dans les fichiers du dossier src de notre exemple.
Appel de fonctions avec run_aster#
La façon d’importer dans le fichier command_file.comm les fonctions contenues dans python_file.py est la suivante :
from src.python_file import my_function
En supposant que le fichier python_file.py contient :
def my_function():
pass
Appel de fonctions avec astk#
Il faut noter que quand on importe un dossier avec repe, astk va copier les fichiers du dossier dans un dossier de nom REPE_IN dans le répertoire temporaire. Cette manipulation signifie que les modules Python doivent non plus être importés depuis src, mais depuis REPE_IN.
Dans le fichier de commande, la façon d’importer les fonctions devient :
from REPE_IN.python_file import my_function
- Remarque :
astk ne permet pas d’avoir plus d’un dossier repe. Alors qu’avec run_aster, qui est la solution recommandée, il est possible d’en avoir plusieurs.
Comment y accéder ?#
Il faut d’abord lancer le conteneur salome_meca, puis cliquer sur View/AsterStudy ou directement sur l’icône de l’outil dans la barre d’outils.