r5.01.01 Solveurs modaux et résolution du problème généralisé (GEP)#
Résumé
Que cela soit pour étudier les vibrations d’une structure ou pour rechercher ses modes de flambement, le mécanicien doit souvent résoudre un problème modal : soit généralisé (GEP), soit quadratique (QEP) [Solveurs modaux et résolution du problème généralisé (GEP)]. Pour ce faire, on propose plusieurs méthodes via l’opérateur [CALC_MODES]: puissances inverses et coefficient de Rayleigh, Lanczos, IRA, Bathe & Wilson et QZ. Elles ont chacune leur périmètre d’utilisation, leur avantages, leurs inconvénients et leur historique de développement.
Pour traiter efficacement de gros problèmes modaux (en taille de maillage et/ou en nombre de modes recherchés), on conseille l’usage de la macro-commande [CALC_MODES] avec l’option BANDE découpée en plusieurs sous-bandes. Elle décompose le calcul modal d’un GEP standard (symétrique et réel), en une succession de sous-calculs indépendants, moins coûteux, plus robustes et plus précis. Rien qu’en séquentiel, les gains peuvent être notables : facteurs 2 à 5 en temps, 2 ou 3 en pic RAM et 10 à 104 sur l’erreur moyenne des modes.
De plus, son parallélisme multi-niveaux peut procurer des gains supplémentaires de l’ordre de 20 en temps et 2 en pic RAM, en réservant une soixantaine de processeurs.
Dans la première partie du document, nous résumons la problématique générale de résolution d’un problème modal, les différentes classes de méthodes et leurs déclinaisons dans les librairies du domaine public. Toutes choses qu’il faut avoir à l’esprit avant d’aborder, dans la seconde partie, l’architecture générale d’un calcul modal. Puis nous détaillons les aspects numériques, informatiques et fonctionnels de chacune des approches disponibles dans le code.
Un chapitre spécifique détaille la mise en oeuvre du parallélisme et du calcul intensif dans le cadre des calculs modaux de type GEP standard.
Généralités sur les solveurs modaux en mécanique des structures#
Problèmes modaux#
Que cela soit pour étudier les vibrations d’une structure, éventuellement amortie et/ou tournante , ou rechercher ses modes de flambement , le mécanicien doit souvent résoudre un problème modal. Pour ce faire, Code_Aster propose un opérateur [1]_ qui traite deux types de problèmes modaux: les généralisés (GEP pour ‘Generalized Eigenvalue Problem’) et les quadratiques (QEP pour ‘Quadratic Eigenvalue Problem’) :
\(\begin{array}{c}\text{Trouver}(\lambda ,\mathrm{u})\text{tel}\text{que}\\ (\mathrm{A}-\lambda \mathrm{B})\mathrm{u}=0(\text{GEP})\\ (\mathrm{A}+\lambda \mathrm{B}+{\lambda}^{2}\mathrm{C})\mathrm{u}=0(\text{QEP})\end{array}\) (2.1-1)
Pour résoudre ces deux classes de problèmes, on les transforme souvent en un problème modal standard (SEP pour ‘Standard Eigenvalue Problem’). Ce type d’approche a le mérite d’être générique et de s’appuyer alors sur des solveurs modaux classiques :
\(\begin{array}{c}\text{Trouver}(\tilde{\lambda},\tilde{\mathrm{u}})\text{tel}\text{que}\\ ({\mathrm{A}}_{\sigma}-\tilde{\lambda}\mathrm{Id})\tilde{\mathrm{u}}=0(\text{SEP})\end{array}\) (2.1-2)
Une transformation spectrale , par exemple, du type ‘shift and invert’, permet de transformer un GEP en un SEP
\(\underset{{\mathrm{A}}_{\sigma}}{\underset{\underbrace{}}{{(\mathrm{A}-\sigma \mathrm{B})}^{-1}\mathrm{B}}}\underset{\tilde{\mathrm{u}}}{\underset{\underbrace{}}{\mathrm{u}}}-\underset{\tilde{\lambda}}{\underset{\underbrace{}}{\frac{1}{\lambda -\sigma }}}\underset{\tilde{\mathrm{u}}}{\underset{\underbrace{}}{\mathrm{u}}}=0\) (2.1-3)
Le complexe \(\sigma\) est un décalage spectrale (appelé souvent ‘ shift ’) qui oriente la zone de recherche dans le spectre. Cette valeur peut être paramétrée dans Code_Aster , par exemple, par le mot-clé CENTRE/FREQ. Dans la même veine, on peut transformer un QEP en un GEP via une technique de linéarisation du type
\(\left[\underset{\tilde{\mathrm{A}}}{\underset{\underbrace{}}{\left[\begin{array}{cc}-\mathrm{A}& 0\\ 0& \mathrm{N}\end{array}\right]}}-\underset{\tilde{\lambda}}{\underset{\underbrace{}}{\lambda}}\underset{\tilde{\mathrm{B}}}{\underset{\underbrace{}}{\left[\begin{array}{cc}\mathrm{B}& \mathrm{C}\\ \mathrm{N}& 0\end{array}\right]}}\right]\underset{\tilde{\mathrm{u}}}{\underset{\underbrace{}}{\left[\begin{array}{c}\mathrm{u}\\ \lambda \mathrm{u}\end{array}\right]}}=0\) avec \(\mathrm{N}=\alpha \mathrm{Id}(\text{par}\text{ex}.\alpha :=\frac{(\mathrm{\parallel }\mathrm{A}\mathrm{\parallel }+\mathrm{\parallel }\mathrm{B}\mathrm{\parallel }+\mathrm{\parallel }\mathrm{C}\mathrm{\parallel })}{3})\) (2.1-4)

Figure 2.1-1. Déformées modales de structures sollicitées dynamiquement (aéroréfrigérant, cuve de réacteur nucléaire) et contraintes modales sur un alternateur.
En mécanique des structures, suivant la problématique, les matrices \(A\) , \(B\) et \(C\) précitées sont des combinaisons linéaires des différentes matrices mécaniques: masse, rigidité, rigidité géométrique, amortissement visqueux ou induit par la structure, effets gyroscopiques. Elles sont souvent réelles (sauf en présence d’amortissement hystérétique), mais pas toujours symétriques (par exemple, du fait d’effets gyroscopiques) et rarement définies positives (à cause des Lagranges notamment). Cet écart à la norme des problèmes modaux usuels (SEP symétriques et définis positifs) et cette variabilité des problématiques compliquent bien sûr leurs traitements algorithmiques.
Une difficulté numérique majeure entre les QEP et les deux autres classes de problèmes (GEP et SEP) concerne le tri des solutions calculées. Pour un problème de taille \(n\) , un QEP admet \(\mathrm{2n}\) modes propres (à valeur propre finie ou infinie) qui peuvent être dépareillées (réelle, imaginaire pure, complexe quelconque) ou en couple (, \((\lambda ,\stackrel{ˉ}{\lambda})\) \((\lambda ,-\stackrel{ˉ}{\lambda})\) …). Il faut alors définir des heuristiques robustes pour filtrer les valeurs propres souhaitées par l’utilisateur [2]_ .
Une autre complication inhérente au QEP est d’ordre algorithmique . Il n’existe pas de décomposition de Schur (resp. Schur généralisé) comme pour les SEP (resp. GEP) sur laquelle va pouvoir s’appuyer l’algorithme de résolution. Par exemple, pour le SEP (2.1-2), cette décomposition nous assure l’existence d’une matrice unitaire (donc bien conditionnée et facilement inversible) \(U\) , permettant la réécriture de la matrice de travail \({\mathrm{A}}_{\sigma}\) sous une forme plus facile à manipuler [3]_ : la matrice triangulaire supérieure \(T\) .
\(\mathrm{U}{\mathrm{A}}_{\sigma}{\mathrm{U}}^{\text{*}}=\mathrm{T}\) (2.1-5)
Méthodes de résolution#
Les solveurs modaux peuvent se regrouper en (au moins) quatre familles . Elles permettent de résoudre des SEP, parfois des GEP et rarement directement des QEP. Pour traiter ces deux derniers types de problème, on a déjà mentionné qu’il fallait souvent pré-traiter le problème mécanique initial (transformation spectrale, technique de linéarisation) pour construire une problème de travail «SEP-compatible» avec les solveurs modaux.
Les algorithmes de type QR (cf. §9 et annexe 1) qui ont été présentés par H.Rutishauser (1958) et formalisés concurremment par J.C.Francis et V.N.Kublanovskaya (1961). QR est un algorithme fondamental souvent impliqué dans les autres méthodes. On le retrouve dans CALC_MODES avec OPTION=”TOUT” (directement avec la méthode QZ cf. §9 et indirectement dans Lanczos et IRAM cf. §6,7).
Périmètre d’utilisation: Calcul de tout le spectre .

Figure 2.2-1. Schéma fonctionnel des méthodes de type QR : apparition des valeurs propres recherchées sur la diagonale.
Avantages: Bonne convergence, robustesse, calcul direct de la forme de Schur, adapté aussi au GEP.
Inconvénients: Complexités mémoire et calcul prohibitives (à réserver aux problèmes de petite taille inférieure à \({10}^{3}\) degrés de liberté), sensibilités aux différences d’amplitude des termes des matrices.
Variantes: Avec shift implicite ou explicite, simple ou double …
Les méthodes de sous-espace qui consistent à projeter l’opérateur de travail sur un espace \(\mathrm{H}\) tel que le spectre de l’opérateur projeté soit une bonne approximation de la partie du spectre initial que l’on recherche Ces algorithmes sont le noyau dur de l’opérateur CALC_MODES avec OPTION parmi (“BANDE”, “CENTRE”, “PLUS_PETITE”, “PLUS_GRANDE”) (cf. §5/6/7/8).
Périmètre d’utilisation: Calcul d’une partie du spectre .
Avantages: Réduction de la taille du problème et des complexités mémoire et calcul, nécessite seulement le calcul d’un produit matrice-vecteur et non pas la connaissance de toute la matrice.
Inconvénients: Utilise de nombreux pré- et post-traitements , convergence peut devenir problématique, capture plus ou moins facilement les multiplicités et les clusters suivant les variantes.
Variantes: Itérations de sous-espace, Bathe et Wilson(1971), Lanczos(1950), Arnoldi 1951), Davidson (1975), Sorensen(1992), Jacobi-Davidson(1996)…
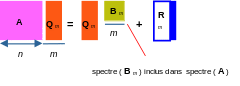
Figure 2.2-2. Schéma fonctionnel des méthodes de type sous-espace. Calcul de \(p\) modes en projetant la matrice de travail de taille \(n\) sur un espace de taille \(m\) ( \(p<m<n\) ).
Les algorithmes de type puissances qui ont été historiquement développés les premiers pour résoudre des problèmes modaux génériques. Ce sont des algorithmes de base dont les autres sont une amélioration. Ils sont impliqués dans l’opérateur CALC_MODES avec OPTION parmi (“PROCHE”, “SEPARE”, “AJUSTE”) (cf. §4).
Périmètre d’utilisation: **Calcul des valeurs extrêmes du spectre.*
Avantages: Simplicité, très bonne estimation du vecteur propre en quelques itérations.
Inconvénients: Convergence peut devenir problématique, mauvaise capture des multiplicités, des clusters…

Variantes: Puissances inverses, (bi) itération du quotient de Rayleigh…
Figure 2.2-3. Schéma fonctionnel des méthodes de type puissance à partir de la décomposition \(A=UD{U}^{\text{*}}\) de l’opérateur diagonalisable \(A\) ( \(U\) matrice unitaire et \(D\) matrice diagonale des valeurs propres).
Les autres approches sont plus ou moins empiriques et spécialisées. Elles sont souvent reliées à d’autres problématiques: recherche de racines de polynômes, de fonctions quelconques… On peut citer ainsi la méthode de bissection utilisée en pré-traitements dans CALC_MODES avec OPTION parmi (“SEPARE”, “AJUSTE”) (cf. §4), mais aussi celle de Müller-Traub (en QEP), de Jacobi, de Laguerre etc. Elles permettent parfois de traiter directement des GEP et des QEP.
Remarque:
De nombreux parallèles peuvent être conduits entre ces familles (la méthode QR n’est ainsi qu’une méthode d’itérations de sous-espaces appliquée à l’espace tout entier), mais elles conduisent aussi à des processus analogues à ceux développés pour d’autres problématiques. Ainsi en optimisation: la méthode du quotient de Rayleigh est à la méthode des puissances inverses, ce que la méthode de Newton est pour une méthode de descente classique. Pour la résolution de systèmes linéaires: la méthode du gradient conjugué est une méthode de sous-espace pour les systèmes symétriques définis positifs. Pour la recherche de racines de polynômes : la méthode des puissances est une méthode de Bernoulli appliquée à la matrice «compagnon» du polynôme associé.
Les librairies d’algèbre linéaire#
Pour effectuer efficacement la résolution d’un problème modal, la question du recourt à une librairie ou à un produit externe est désormais incontournable . Pourquoi? Parce que cette stratégie permet:
Des développements moins techniques, moins invasifs et beaucoup plus rapides dans le code hôte.
D’acquérir, à moindre frais, un large périmètre d’utilisation tout en externalisant bon nombre des contingences associées (typologie du problème, représentation des données, architecture de la machine cible…).
De bénéficier du retour d’expérience d’une communauté d’utilisateurs variée et des compétences (très) pointues d’équipes internationales.
Ces librairies conjuguent en effet souvent efficacité, fiabilité, performance et portabilité :
Efficacité car elles exploitent la localité spatiale et temporelle des données et jouent sur la hiérarchie mémoire (exemple des différentes catégories de BLAS).
Fiabilité car elles proposent parfois des outils pour estimer l’erreur commise sur la solution (estimation du conditionnement et des ‘backward/forward errors’) voire pour l’améliorer (par ex. équilibrage matriciel).
Depuis l’émergence dans les années 1970/1980 des premières librairies publiques [4]_ et constructeurs [5]_ et de leurs communautés d’utilisateurs, l’offre s’est démultipliée. La tendance étant bien sûr de proposer des solutions performantes (vectoriel, parallélisme à mémoire centralisé puis distribué, parallélisme multi-niveau via des threads) ainsi que des «toolkits» de manipulation d’algorithmes d’algèbre linéaire et des structures de données associées. Citons de manière non exhaustive: ScaLAPACK(Dongarra & Demmel 1997), SparseKIT(Saad 1988), PETSc(Argonne 1991), HyPre(LL 2000), TRILINOS(Sandia 2000)…

Figure 2.3-1. Quelques «logos» de bibliothèques d’algèbre linéaire incluant des solveurs modaux.
Concernant plus spécifiquement les solveurs modaux , une trentaine de packages sont disponibles. On distingue les produits «autonomes» de ceux incorporés à une librairie, les publics des commerciaux, ceux traitant des problèmes denses et d’autres des creux. Certains ne fonctionnent qu’en mode séquentiel, d’autres supportent un parallélisme à mémoire partagée et/ou distribuée. Enfin, certains produits sont généralistes (symétrique, non symétrique, réel/complexe, SEP/GEP…) d’autres adaptés à un besoin/scénario bien précis.
On peut trouver une liste assez exhaustive de tous ces produits dans une synthèse commise par l’équipe de SLEPc[HRTV07] (‘Scalable Library for Eigenvalue Problem Computations’). Toutefois, elle ne reprend que les solveurs modaux creux du domaine public et oublie de mentionner JADAMILU, LZPACK et PARPACK.
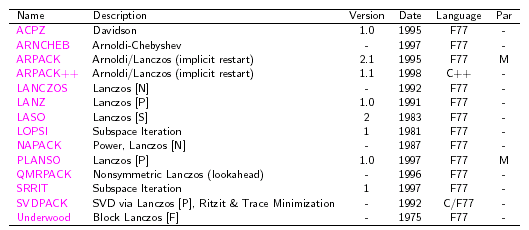
Tableau 2.3-1. Extrait du survey de SLEPc[HRTV07] sur les produits libres implémentant un solveur modal creux. Solveurs déjà anciens et plus maintenus; ‘M’ pour MPI, ‘O’ OpenMP et ‘-’ pour séquentiel;
Type de réorthogonalisation (cf. §6): [F] pour complète, [S] sélective, [P] partielle ou aucune [N].
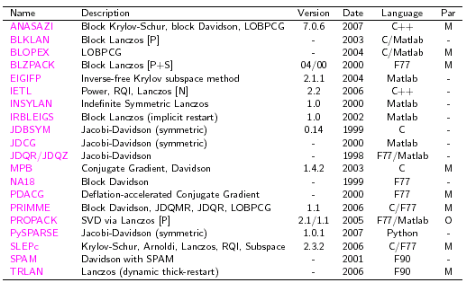
Tableau 2.3-2. Extrait du survey de SLEPc[HRTV07] sur les produits libres implémentant un solveur modal creux. Solveurs réçents ou encore maintenus.
Quelques résultats et benchmarks#
Pour attester du bien fondé de son approche, chaque produit procure sur son site web des résultats de runs séquentiels (voire parallèle). Ils sont souvent basés sur des matrices de tests issues de collections publiques (MatrixMarket[MaMa], Université de Floride, Harwell…). Compte-tenu, notamment, de la difficulté de l’exercice et de son fort investissement en temps et en moyens (humain et machine), on trouve assez peu de comparatifs sur les solveurs modaux.
Parmi ces benchmark, trois ont retenu notre attention :
SEP à matrices réelles symétriques définies positives [BP02] traités par ARPACK[Arp], JD(Jacobi-Davidson[SV96]) et DACG(‘Deflation Accelerated Conjugate Gradient’[GSF92]). Etude en séquentiel sur une dizaine de matrices creuses issues de différentes applications (éléments finis, différences finies, éléments finis mixtes…) et de tailles variables: 5.103 à 3.105 ddls.
Résultats: pour rechercher un nombre de modes propres inférieur à 40, JD et DACG sont plus efficaces qu’ARPACK. Au delà, ARPACK est plus compétitif . Sur un problème difficile comportant un cluster de 10 valeurs propres (valeurs propres très proches), seul DACG a fonctionné de manière satisfaisante.
GEP à matrices réelles symétriques [AHLT05] issus de problèmes de mécanique vibratoire de grande taille (supérieure à \({10}^{6}\) degrés de liberté). Les problèmes sont discrétisés par des EF isoparamétriques et de structure (poutre, coque) en élasticité linéaire. Quatre types de solveurs modaux sont testés: LOBPCG(‘Locally Optimal block Preconditioned Conjugate Gradient’[Kny91]), DACG, JD et ARPACK. D’un point de vue numérique, l’étude est très fouillée en insistant sur les aspects préconditionneurs, réorthogonalisations et critère de redémarrage. Les calculs ont été menés en séquentiel en utilisant en interne du solveur modal, un solveur linéaire du type GCPC[Boi09b] préconditionné par l’AMG de Trilinos.
Résultats: en temps CPU et en fiabilité, ARPACK est souvent dépassé par ces nouveaux concurrents .
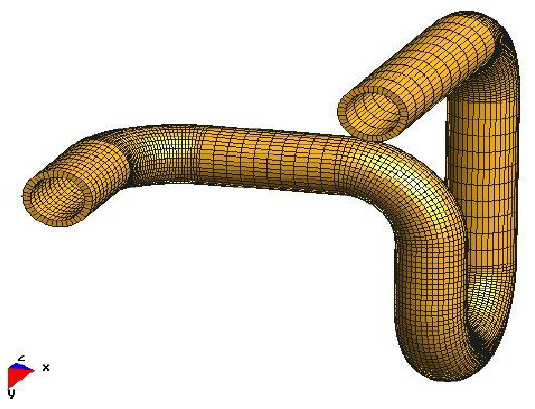
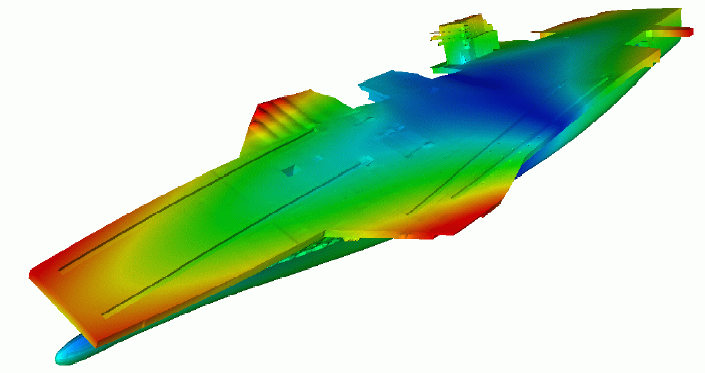
Figure 2.4-1. Exemples de problèmes de mécanique vibratoire utilisés dans les benchmarks[AHLT03]: tube coudé élastique et porte-avions!
SEP à matrices réelles non symétriques [LS96] traités par ARPACK, un Arnoldi accéléré via Tchebyschev (code ARNCHEB) et des méthodes de sous-espace (packages LOPSI et SRRIT). Vieille étude en séquentiel sur une vingtaine de matrices de petite taille (104 degrés de liberté) issues de différents domaines de la physique.
Résultats: ARPACK est souvent le meilleur sur les aspects consommation mémoire, CPU et fiabilité.
Point positif , les méthodes modales disponibles dans Code_Aster sont référencées dans les benchmarks (notamment ARPACK). Cependant le code accuse un certain retard par rapport à la recherche actuelle et ne propose pas (pas encore!) les toutes dernières approches:
Parallélisation des solveurs modaux et distribution des données associée.
Algorithmes préconditionnés et par blocs (en particulier LOBPCG, JD et DACG).
Contexte#
Problématique#
Nous considérons le problème modal généralisé (GEP)
Trouver \((\lambda ,U)\) tels que \(Au=\lambda Bu,u\ne 0\) (3.1-1)
où \(A\) et \(B\) sont des matrices à coefficients réels ou complexes, symétriques ou non (en structure et/ou en valeurs). Ce type de problème correspond, en mécanique, notamment à:
L’étude des vibrations libres d’une structure non amortie et non tournante. Pour cette structure, on recherche les plus petites valeurs propres ou bien celles qui sont dans un intervalle donné pour savoir si une force excitatrice peut créer une résonance. Dans ce cas standard, la matrice \(A\) est la matrice de rigidité, notée \(\mathrm{K}\) , réelle et symétrique (éventuellement augmentée de la matrice de rigidité géométrique notée \({K}_{g}\) , si la structure est précontrainte) et \(B\) est la matrice de masse ou d’inertie notée \(M\) (réelle symétrique). Les valeurs propres obtenues sont les carrés des pulsations associées aux fréquences cherchées.
Le système à résoudre peut s’écrire: \((K+{K}_{g})u={\omega}^{2}Mu\) où est \(\omega =2\pi f\) la pulsation, \(f\) la fréquence propre et \(u\) le vecteur de déplacement propre associé. Les modes propres \((\omega ,u)\) sont réels.
En présence d’amortissement hystérétique , \(\mathrm{K}\) devient complexe symétrique. Alors les modes propres sont potentiellement complexes et dépareillés.
En revanche, si \(K\) et/ou \(M\) restent réelles mais éventuellement non symétriques [6] , les modes propres sont soit réels, soit en couple \((\lambda ,\stackrel{ˉ}{\lambda})\) .
Ce type de problématique est activé par le mot-clé TYPE_RESU=‘DYNAMIQUE’.

A / B |
Réelle symétrique |
Réelle non symétrique |
Complexe |
Réelle symétrique |
Cas le plus courant aucune restriction sur les méthodes; Modes réels. |
OPTION parmi (“BANDE”,”CENTRE”,”PLUS_PETITE”,”PLUS_GRANDE”,”TOUT”)avec SOLVEUR_MODAL=_F(METHODE=”SORENSEN’ ou ’QZ’); Modes réels ou complexes \((\lambda ,\stackrel{ˉ}{\lambda})\) . |
Cas non traité |
Réelle non symétrique |
OPTION parmi (“BANDE”,”CENTRE”,”PLUS_PETITE”,”PLUS_GRANDE”,”TOUT”) avec SOLVEUR_MODAL=_F(METHODE=”SORENSEN’ ou ’QZ’); Modes réels ou complexes \((\lambda ,\stackrel{ˉ}{\lambda})\) . |
SIMULTavec ‘SORENSEN’/’QZ’ Modes réels ou complexes \((\lambda ,\stackrel{ˉ}{\lambda})\) . |
Cas non traité |
Complexe symétrique |
OPTION parmi (“BANDE”,”CENTRE”,”PLUS_PETITE”,”PLUS_GRANDE”,”TOUT”) avec SOLVEUR_MODAL=_F(METHODE=”SORENSEN’ ou ’QZ’); Modes réels, complexes quelconques ou \((\lambda ,\stackrel{ˉ}{\lambda})\) . |
Cas non traité |
Cas non traité |
Autres complexes (hermitien, non symétrique…) |
Cas non traité |
Cas non traité |
Cas non traité |
Tableau 1. Périmètre d’utilisation de l’opérateur CALC_MODES selon le critère de recherche et l’algorithme d’analyse, en fonction de propriétés des matrices du GEP.
La recherche de mode de flambement linéaire . Dans le cadre de la théorie linéarisée, en supposant a priori que les phénomènes de stabilité sont convenablement décrits par le système d’équations obtenu en supposant la dépendance linéaire du déplacement par rapport au niveau de charge critique, la recherche du mode de flambement \(u\) associé à ce niveau de charge critique \(\lambda\) , se ramène à un problème généralisé aux valeurs propres de la forme: \((\mathrm{K}+\lambda {\mathrm{K}}_{\mathrm{g}})\mathrm{u}=0\) avec \(K\) matrice de rigidité et \({K}_{g}\) matrice de rigidité géométrique. Pour se fondre dans le «moule» d’un calcul de GEP standard, le code calcule, dans un premier temps, les modes propres \((-\lambda ,u)\) réels. Puis il les convertit au format d’un calcul de flambement: \((\lambda ,\mathrm{u})\) .
Ce type de problématique est activé par le mot-clé TYPE_RESU=‘MODE_FLAMB’. Il est à réserver aux GEPs symétriques réels (sinon le code le détecte et produit une erreur fatale).
Remarques:
CALC_MODES permet d’automatiser le choix de l’algorithme en fonction du critère de recherche, et de réduire les coûts (CPU et mémoire) d’une recherche d’une partie importante du spectre (uniquement en GEP à modes réels) lorsqu’on recherche les modes sur une bande globale découpée en sous-bandes.
L’utilisateur peut spécifier la classe d’appartenance de son calcul en initialisant le mot-clé TYPE_RESU à “DYNAMIQUE” (valeur par défaut) ou à “MODE_FLAMB”. L’affichage des résultats sera alors formaté en tenant compte de cette spécificité. Dans le premier cas on parlera de fréquence (FREQ) alors que dans le second, on parlera de charge critique (CHAR_CRIT).
En présence d’amortissements et d’effets gyroscopiques, l’étude de la stabilité dynamique d’une structure conduit à la résolution d’un problème modal d’ordre plus élevé, dit quadratique (QEP): \((K+i\omega C-{\omega}^{2}M)u=0\) . Il est résolu par les deux opérateurs modaux et fait l’objet d’une note spécifique[Boi09].
Maintenant que les liens entre la mécanique des structures et la résolution de problèmes modaux généralisés ont été rappelés, nous allons nous intéresser aux traitements des conditions limites dans le code et à leurs incidences sur les matrices de masse et de rigidité.
Prise en compte des conditions limites#
Il y a deux façons, lors de la construction des matrices de rigidité et de masse, de prendre en compte les conditions aux limites (cette description en terme de problème dynamique s’extrapole facilement au flambement):
La double dualisation, en utilisant des degrés de liberté de Lagrange[Pel01], permet de vérifier
\(Cu=0\) (CLL pour Condition Limite Linéaire),
avec \(C\) matrice réelle de taille \(p\times n\) (\(K\) et \(M\) sont d’ordre \(n\) ). Elle entraîne la manipulation de matrices plus grosses (dites «dualisées») car incorporant ces nouvelles inconnues. Les matrices de rigidité et de masse dualisées ont alors la forme
\(\tilde{\mathrm{K}}=(\begin{array}{ccc}\mathrm{K}& \beta {\mathrm{C}}^{\mathrm{T}}& \beta {\mathrm{C}}^{\mathrm{T}}\\ \beta \mathrm{C}& -\alpha \mathrm{Id}& \alpha \mathrm{Id}\\ \beta \mathrm{C}& \alpha \mathrm{Id}& -\alpha \mathrm{Id}\end{array})\) \(\tilde{M}=(\begin{array}{ccc}M& 0& 0\\ 0& 0& 0\\ 0& 0& 0\end{array})\)
avec \(\alpha\) et \(\beta\) réels strictement positifs (qui servent à équilibrer les termes de la matrice). La dimension du problème a été augmentée de \(\mathrm{2p}\) , car aux \(n\) degrés de liberté dits « physiques », on a rajouté des Lagranges. Il y a deux Lagranges par relation linéaire affectée aux \(p\) conditions limites.
La mise a zéro de \(p\) lignes et colonnes des matrices de rigidité et de masse . Ceci n’est valable que pour des blocages de degrés de liberté (Dirichlet simple, pas de relation de proportionnalité entre ddls). On ne peut pas prendre en compte de relation linéaire et on parlera de blocage cinématique (CLB pour Condition Limite de Blocage). Les matrices de rigidité et de masse deviennent:
\(\tilde{K}=(\begin{array}{cc}\stackrel{ˉ}{K}& 0\\ 0& \mathrm{Id}\end{array})\) \(\tilde{M}=(\begin{array}{cc}\stackrel{ˉ}{M}& 0\\ 0& 0\end{array})\)
La dimension du problème reste inchangée mais il faut cependant retirer les participations des ddls bloqués aux composantes des matrices initiales (\(\stackrel{ˉ}{K}\) est obtenue à partir de \(K\) en éliminant les lignes et les colonnes des ddls qui sont bloqués; idem pour \(\stackrel{ˉ}{M}\) ).
Lorsqu’on impose des conditions limites, le nombre de valeurs propres (avec toutes leurs multiplicités) réellement impliquées dans la physique du phénomène est donc inférieur à la taille \(n\) du problème transformé:
\({n}_{\mathit{ddl}-\mathit{actifs}}=n-\frac{3p'}{2}\text{avec}p'=2p\) (double dualisation),
\({n}_{\mathrm{ddl}-\mathrm{actifs}}=n-p\) (blocage cinématique).
L’encadré ci-dessous montre l’affichage dédié à ces paramètres dans le fichier message.
LE NOMBRE DE DDL
TOTAL EST: 220 \(\to\) n
DE LAGRANGE EST: 58 \(\to\) p’=2p
LE NOMBRE DE DDL ACTIFS EST : 133 \(\to\) nddl_actifs
Exemple 1. Affichage dans le fichier message de la taille du problème modal.
D’autre part, dans les algorithmes de calcul modal, on doit s’assurer de l’appartenance des solutions à l’espace admissible . On s’y ramène via des traitements auxiliaires. Ainsi lorsqu’on utilise des blocages cinématiques (CLB), il faut, dans les différents algorithmes et à chaque itération, utiliser un «vecteur de positionnement» \({\mathrm{u}}_{\mathit{bloq}}\) , défini par
si \(i\) ème degré de liberté n’est pas bloqué \({\mathrm{u}}_{\mathit{bloq}}(i)=1\) ,
sinon \({\mathrm{u}}_{\mathit{bloq}}(i)=0\) ,
et en pré-multiplier chaque vecteur manipulé
\({\mathrm{u}}^{1}(i)={\mathrm{u}}^{0}(i)\cdot {\mathrm{u}}_{\mathit{bloq}}(i)(i=\mathrm{1...n})\mathrm{\Rightarrow }{\mathrm{u}}^{1}\)
Cette astuce introduit la contrainte des blocages dans tout l’algorithmique et oriente implicitement la recherche de solution dans l’espace admissible.
De même, si on utilise la méthode de double dualisation, on a besoin d’un vecteur de positionnement des degrés de liberté de lagrange \({\mathrm{u}}_{\mathit{lagr}}\) défini comme \({\mathrm{u}}_{\mathit{bloq}}\) . Il est seulement utilisé lors du choix du vecteur initial aléatoire. Pour que ce vecteur \({u}^{0}\) vérifie les conditions limites (CLL) on opère de la façon suivante:
\(\mid \begin{array}{c}{\mathrm{u}}^{1}(i)={\mathrm{u}}^{0}(i)\cdot {\mathrm{u}}_{\mathit{lagr}}(i)(i=\mathrm{1...n})\\ \tilde{\mathrm{K}}{\mathrm{u}}^{2}={\mathrm{u}}^{1}\end{array}\mathrm{\Rightarrow }{\mathrm{u}}^{1}\)
D’autre part, on inclut souvent la contrainte supplémentaire que ce vecteur initial appartiennent à l’ensemble image de l’opérateur de travail . Cela permet d’enrichir plus rapidement le calcul modal en ne se limitant pas au noyau. Ainsi, dans le cas de Lanczos et d’IRAM, on prendra comme vecteur initial, non pas le \({u}^{2}\) précédent, mais \({u}^{3}\) tel que
\({\mathrm{u}}^{3}={(\mathrm{K}-\sigma \mathrm{M})}^{\text{-1}}\mathrm{M}{\mathrm{u}}^{2}\)
Par la suite, pour simplifier les notations, nous ne ferons pas le distinguo entre les matrices initiales et leurs pendants dualisés (notés avec un tilde) que si nécessaire. Bien souvent, elles seront désignées par \(A\) et \(B\) afin de se rapprocher de la notation modale usuelle sans se rattacher à telle ou telle classe de problèmes.
Remarque:
Toutes les options de calculs fonctionnent quelque soit le type de prise en compte des conditions limites: AFFE_CHAR_MECA ou AFFE_CHAR_CINE. Toutefois, celles-ci ne doivent pas être redondantes: par exemple, un AFFE_CHAR_MECA + AFFE_CHAR_CINE sur une même inconnue.
Propriétés des matrices#
Dans le cas (le plus courant) où les matrices considérées sont symétriqueset àcoefficients réels , on répertorie les cas de figure décrits dans le tableau ci-dessous. Les matrices peuvent être définies positives (noté \(>0\) ), semi‑définies positives (\(\ge 0\) ), indéfinies (\(\le 0\text{ou}\ge 0\) ) voire singulières (\(S\) ).
Structure libre |
Lagranges [7] |
Flambement |
Fluide-structure |
|
\(A(K)\) |
\(\ge 0\) et \(S\) |
\(<0\) ou \(>0\) |
\(>0\) |
\(\ge 0\) et S |
\(B\) (resp. \(M\) ou \({K}_{g}\) ) |
\(>0\) |
\(\ge 0\) et \(S\) |
\(\le 0\text{ou}\ge 0\) |
\(>0\) |
Tableau 3.3-1. Propriétés des matrices du GEP.
Les colonnes de ce tableau s’excluant mutuellement, en pratique, un problème de flambement utilisant des doubles Lagranges pour modéliser certaines de ses conditions limites, voit ses matrices dualisées (\(\tilde{K}\text{et}\tilde{{K}_{g}}\) ) devenir potentiellement indéfinies.
Cet éventail de propriétés doit être pris en compte lors du choix du couple «(opérateur de travail, produit scalaire)». Ce cadre peut ainsi renforcer, avec efficacité et transparence, la robustesse et le périmètre de l’algorithme de calcul modal dans tous les cas de figure rencontrés par Code_Aster .
Dans le cas où les matrices sont complexes symétriques ou réelles non symétriques , on ne peut plus définir de produit scalaire matriciel. Seules alors sont disponibles les méthodes QZ (§9) et IRAM(§7). La première n’a pas besoin de ce type de mécanisme et, on «bluffe» la seconde en lui fournissant un «faux» produit-scalaire matriciel, en fait le produit scalaire euclidien usuel (cf. §7.5). Cette dernière astuce est licite avec IRAM, car en tant que variante d’Arnoldi, elle peut fonctionner avec un couple (opérateur de travail,produit-scalaire) non symétrique.
Les paragraphes suivants vont nous permettent de mesurer l’incidence de ces propriétés sur le spectre de problème généralisé.
Propriétés des modes propres#
Rappelons tout d’abord que si la matrice du SEP \(\mathrm{A}\mathrm{u}=\lambda \mathrm{u}\) est réelle symétrique, alors ses éléments propres sont réels; Les éléments propres d’une matrice sont ses valeurs et ses vecteurs propres. D’autre part, \(A\) étant normale, ses vecteurs propres sont orthogonaux.
Dans le cas du GEP \(\mathrm{A}\mathrm{u}=\lambda \mathrm{B}\mathrm{u}\) , cette condition n’est pas suffisante. Ainsi, considérons le problème généralisé suivant:
\(\left[\begin{array}{cc}1& 1\\ 1& 0\end{array}\right](\begin{array}{}{u}_{1}\\ {u}_{2}\end{array})=\lambda \left[\begin{array}{cc}1& 0\\ 0& -1\end{array}\right](\begin{array}{}{u}_{1}\\ {u}_{2}\end{array})\)
ses modes propres sont
. \({\lambda}_{\pm}=\frac{1}{2}(1\pm i\sqrt{(3)})\text{et}{u}_{\pm}=\frac{1}{\sqrt{1+{\lambda}_{\pm}^{2}}}(\begin{array}{}-{\lambda}_{\pm}\\ 1\end{array})\)
Si on ajoute l’hypothèse « une des matrices \(A\) ou \(B\) est définie positive « , alors le problème généralisé a ses solutions réelles . On a même la caractérisation (condition suffisante) plus précise suivante.
Théorème1
Soient \(A\) et \(B\) deux matrices symétriques réelles. S’il existe \(\alpha \in \mathrm{ℝ}\) et \(\beta \in ℝ\) tels que \(\alpha A+\beta B\) soit définie positive, alors le problème généralisé a ses éléments propres réels.
Preuve:
Ce résultat s’obtient immédiatement en multipliant le problème généralisé par \(\alpha\) et en effectuant un décalage spectral \(\beta\) . On obtient alors le problème \((\alpha A+\beta B)u=(\lambda \alpha +\beta )Bu\) . Comme est définie \(\alpha A+\beta B\) positive, elle admet une décomposition de Cholesky unique sous la forme \(C{C}^{T}\) avec \(C\) matrice régulière.
Le problème s’écrit alors \({C}^{\text{-1}}B{C}^{-T}z=\mu z\) avec \(z={C}^{T}u\) et \(\mu =\frac{1}{\alpha \lambda +\beta }\) , ce qui permet de conclure, car la matrice \({C}^{\text{-1}}B{C}^{-T}\) est symétrique.
Remarques
Cette caractérisation n’est pas nécessaire, ainsi le problème généralisé associé aux matrices \(A=\mathrm{diag}(1,-2,-1)\) et \(B=\mathrm{diag}(-2,1,1)\) admet un spectre réel tout en ne répondant pas à la condition de définie positivité.
Dans le cas de matrices complexes et hermitienne, ce théorème reste valide. Par contre, en complexe non hermitien (c’est le cas lors de la prise en compte de l’amortissement hystérétique dans Code_Aster), les modes propres peuvent être complexes: vecteurs propres à composantes complexes et valeurs propres \(\lambda\) réelles ou complexes quelconques.
En réel non symétrique, les modes propres peuvent être complexes: vecteurs propres à composantes complexes et valeurs propres \(\lambda\) réelles ou complexes par couple \((\lambda ,\stackrel{ˉ}{\lambda})\) .
Proposition 2
Si les matrices \(A\) et \(B\) sont réelles et symétriques, les vecteurs propres du problème généralisé sont \(A\) et \(B\) - orthogonaux, ce qui signifie qu’ils vérifient les relations
\(\lbrace \begin{array}{}{u}_{i}^{T}B{u}_{j}={\delta}_{ij}{a}_{j}\\ {u}_{i}^{T}A{u}_{j}={\lambda}_{j}{\delta}_{ij}{a}_{j}\end{array}\)
où \({a}_{j}\) est un scalaire dépendant de la norme du \(j\) ième vecteur propre, \({\delta}_{ij}\) est le symbole de Kronecker et \({u}_{j}\) est le vecteur propre associé à la valeur propre \({\lambda}_{j}\) .
Preuve:
Immédiate pour des valeurs propres distinctes, en écrivant les \(\mathrm{A}\) et \(B\) - produit scalaire entre deux couples \((i,j)\) et \((j,i)\) , puis en utilisant la symétrie des matrices (cf. [Imb91]).
Remarques:
On montre que les \(A\) et \(B\) - orthogonalités des vecteurs propres sont une conséquence de l’hermiticité des matrices. Elles sont clairement une généralisation des propriétés du problème standard hermitien (voire normaux): dans le cas d’une matrice à coefficients complexe et hermitienne, le produit scalaire à considéré est un produit hermitien.
L’orthogonalité par rapport aux matrices ne signifie surtout pas que les vecteurs propres sont orthogonaux pour la norme euclidienne classique. Celle-ci ne peut être que le fruit de symétries particulières (cf. TP n°1 [BQ00]).
Cette propriété simplifie les calculs de recombinaisons modales (DYNA_TRAN_MODAL[Boy07]), lorsqu’on manipule des matrices de rigidité et de masse généralisées qui sont diagonales. Les quantités j \({k}_{j}={\lambda}_{j}{a}_{j}\) et \({m}_{j}={a}_{j}\) sont appelées, respectivement, rigidité modale et masse modale du \(j\) ième mode.
Pour les matrices non hermitiennes, le théorème 1 n’est plus vérifié.
Sachant que les modes sont souvent réels, nous allons maintenant nous préoccuper de leur estimation.
Estimation du spectre réel#
Le document R5.01.04 est dédié à cette problématique transverse aux opérateurs modaux: INFO_MODE et CALC_MODES.
Rappelons juste que dans le cas le plus courant de modes réels (GEP réel symétrique), le problème du comptage de valeurs propres se résout à l’aide du fameux test de Sturm (cf. §2.2/3.2). La situation est beaucoup moins favorable lorsque le spectre réside dans le plan complexe (GEP complexe ou non symétrique et QEP). Dans ce cas, seul l’opérateur INFO_MODE dispose d’une méthode adaptée: la méthode APM (cf. §2.3/3.3). Mais du fait de ses énormes coûts calcul et de son caractère novateur, il est conseillé de la réserver, pour l’instant, aux problèmes simplifiés de petite taille (<104 degrés de liberté).
Maintenant que nous sommes en mesure de comptabiliser le spectre du GEP, il reste à le construire ! Les algorithmes génériques étant destinés aux SEP, il faut transformer notre problème initial.
Transformation spectrale#
Ces techniques permettent de répondre à un triple objectif:
identifier un SEP,
Orienter la recherche du spectre,
Séparer les valeurs propres.
Les algorithmes de calcul spectral convergeant d’autant mieux que le spectre (de travail) qu’ils traitent est séparé, ces techniques peuvent être considérées comme des préconditionnement du problème de départ. Elles permettent de rendre la séparation de certains modes beaucoup plus importante que celles d’autres modes, et d’améliorer ainsi leur convergence.
La plus répandue de ces transformations est la technique dite de « shift and invert » qui consiste à travailler avec l’opérateur \({\mathrm{A}}_{\sigma}\) tel que:
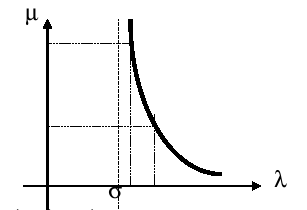
\(\text{Au}=\lambda \text{Bu}\mathrm{\Rightarrow }\underset{{\mathrm{A}}_{\sigma}}{\underset{\underbrace{}}{{(\text{A}-\sigma \mathrm{B})}^{-1}\mathrm{B}}}\mathrm{u}=\underset{\mu}{\underset{\underbrace{}}{\frac{1}{\lambda -\sigma }}}\mathrm{u}\)
Figure 3.6-1. Effet du « shift and invert » sur la séparation des valeurs propres.
La figure 3.6-1 montre que cette séparation et cette orientation du spectre de travail en \(\mu\) sont dues aux propriétés particulières de la fonction hyperbolique. D’autre part, on observe que seules les valeurs propres sont affectées par la transformation. En fin de processus modal il suffit donc de repasser dans le plan des \(\lambda\) par un changement de variable idoine.
Remarques:
La variable \(\sigma\) est usuellement désignée par le terme de «shift» ou de décalage spectral.
La matrice de travail \({A}_{\sigma}\) doit bien sûr être inversible, cela peut d’ailleurs devenir une des motivations de ce décalage (cf. §6.5).
Pour mémoire, notons qu’avec un shift complexe plusieurs scénarios sont envisageables:
Travailler complètement en arithmétique complexe,
En arithmétique réelle, en isolant les contributions réelles et imaginaires de \({\mathrm{A}}_{\sigma}\) , par exemple via les opérateurs de travail
\({A}_{\sigma}^{+}=\text{Re}({A}_{\sigma})\mathrm{\Rightarrow }{\mu}^{+}=\frac{1}{2}(\frac{1}{\lambda -\sigma }+\frac{1}{\lambda -\stackrel{ˉ}{\sigma}})\) ,
\({A}_{\sigma}^{-}=\text{Im}({A}_{\sigma})\mathrm{\Rightarrow }{\mu}^{-}=\frac{1}{\mathrm{2i}}(\frac{1}{\lambda -\sigma }-\frac{1}{\lambda -\stackrel{ˉ}{\sigma}})\) .
Chacune de ses approches a ses avantages et ses inconvénients. Pour les QEP de Code_Aster [Boi09], c’est la première démarche qui a été retenue pour Sorensen (METHODE=’SORENSEN’+APPROCHE=’COMPLEXE’). La seconde est réservée aux autres approches: METHODE=’SORENSEN’ ou ‘TRI_DIAG’ + APPROCHE=’REEL’/’IMAGINAIRE’).
Remarques
Ce choix de l’opérateur de travail est indissociable de celui du (pseudo)-produit scalaire. Il permet de s’orienter vers tel ou tel algorithme et peux ainsi influer sur la robustesse du calcul.
D’autres classes de transformations spectrales existent. Par exemple celle de Cayley, avec un double shifts (\({\sigma}_{1,}{\sigma}_{2}\) ), permet de sélectionner les valeurs propres situées à droite d’un axe vertical
\(\underset{{A}_{\sigma}}{\underset{\underbrace{}}{{(\mathrm{A}-{\sigma}_{1}\mathrm{B})}^{\text{-1}}(\mathrm{A}-{\sigma}_{2}\mathrm{B})}}\mathrm{u}=\underset{\mu}{\underset{\underbrace{}}{\frac{\lambda -{\sigma}_{2}}{\lambda -{\sigma}_{1}}}}\mathrm{u}\)
Le paragraphe suivant va synthétiser ce qui précède dans l’organigramme global de résolution d’un problème modal généralisé de Code_Aster .
Implantation#
Le déroulement d’un calcul modal dans Code_Aster peut se décomposer en quatre phases. Les paragraphes suivant les détaillent.
Détermination du shift#
La première opération consiste à déterminer le shift ainsi que certains paramètres du problème. Cela s’effectue de manière plus ou moins transparente suivant l’option de calcul choisie par l’utilisateur:
OPTION=”SEPARE’ou “AJUSTE” =>le shift est déterminé par la première phase de l’algorithme et le nombre de modes propres recherchés par bande fréquentielle (fourni par le critère de Sturm) est borné par NMAX_FREQ.
OPTION=”PROCHE”=>le shift est fixé par l’utilisateur et le nombre de modes propres est égal au nombre de shifts.
OPTION=”PLUS_PETITE” => leshift est nul et le nombre de modes est paramétré par NMAX_FREQ.
OPTION=”BANDE”=>leshift est égal au milieu de la bande fixée par l’utilisateur et le nombre de modes est déterminé par le critère de Sturm.
OPTION=”CENTRE”=> le shift est fixé par l’utilisateur et le nombre de modes propres est paramétré par NMAX_FREQ.
Remarques:
Cette phase ne concerne pas l’algorithme QZ. En effet ce dernier calcule tout le spectre du GEP. C’est juste après le calcul modal que l’on tient compte des desiderata de l’utilisateur (OPTION=’BANDE’ ou ’CENTRE’ ou “PLUS_PETITE” ou “PLUS_GRANDE” ou ’TOUT’) pour sélectionner les modes recherchés.
Pour un GEP à modes complexes (\(\mathrm{K}\) complexe symétrique ou matrices non symétriques), seules les options ’CENTRE’, “PLUS_PETITE”, “PLUS_GRANDE”, ’TOUT’ sont disponibles (avec Sorensen et QZ).
Factorisation de matrices dynamiques#
Dans la seconde phase de pré-traitements, on factorise [Boi08] des matrices «dynamique» du type \(Q(\sigma ):=A-\sigma B\) *.* C’est-à-dire qu’on décompose la matrice dynamique \(Q(\sigma )\) en un produit de matrices particulières (triangulaire, diagonale) plus faciles à manipuler pour résoudre des systèmes linéaires du type \(Q(\sigma )x=y\) . En symétrique, la décomposition est de la forme \(Q(\sigma )=LD{L}^{T}\) , en non symétrique, on a \(Q(\sigma )=LU\) , avec \(U\) , \(L\) et \(D\) , respectivement, triangulaire supérieure, inférieure et diagonale.
Une fois cette factorisation numérique (coûteuse) effectuée, la résolution d’autres systèmes linéaires comportant la même matrice mais avec un second membre différent (problème de type multiple seconds membres) est très rapide.
Ce cas de figure se retrouve
* à chaque fois que l’on met en œuvre le **test de Sturm** . C’est-à-dire pour certains scénarios de la phase 1 de sélection du shift (OPTION='SEPARE’/'AJUSTE' ou 'BANDE') et en prévision de la phase 4 de post-vérification lors du comptage des valeurs propres réelles (GEP à matrices réelles et symétriques uniquement).
lorsqu’on doit manipuler une matrice de travail comportant un inverse. Par exemple dans le cas de Lanczos ou d’IRAM (OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”,”TOUT”] + SOLVEUR_MODAL=_F(METHODE=’TRI_DIAG’/‘SORENSEN’)), on s’intéresse à \({A}_{\sigma}={(A-\sigma B)}^{-1}B\) . Avec la méthode des puissances inverses (OPTION=”SEPARE’/”AJUSTE”/”PROCHE”), il s’agit de \({A}^{\sigma}={(A-\sigma B)}^{-1}\) . Les deux autres approches, Bathe & Wilson ou QZ (OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”,”TOUT”] + SOLVEUR_MODAL=_F(METHODE=’JACOBI’/’QZ’)) ne sont pas concernées par cette factorisation préliminaire d’une matrice de travail.
Remarques:
Cette factorisation subit d’ailleurs les mêmes aléas que le critère de Sturm lorsque le shift est proche d’une valeur propre. On procède alors aux même décalages suivant l’algorithme 1 de R5.01.04.
Lorsque cette phase de pré-traitements met en œuvre l’algorithme 5 de R5.01.04 et que NMAX_ITER_SHIFT est atteint le calcul produit une alarme s’il s’agit d’une factorisation pour le test de Sturm (risque d’instabilités numériques), une erreur fatale si on cherche à factoriser la matrice de travail (risque de résultats faux).
Lorsqu’on utilise l’algorithme QZ sur des GEP non symétriques ou complexes, on n’a pas besoin de factoriser de matrice dynamique. Ce distinguo permet d’économiser un peu de complexité calcul, l’algorithme QZ étant déjà assez coûteux en-soi!
En chaînant les opérateurs INFO_MODE [U4.52.01] et CALC_MODES, on peut mieux orienter / calibrer son calcul spectral voire limiter le surcoût qu’engendre le test de Sturm initial de l’option “BANDE” (cf. mot-clé TABLE_FREQ/CHAR_CRIT[U4.52.02]).
Calcul modal#
On effectue le calcul modal proprement dit: on résout le problème standard SEP, puis on revient au GEP initial. Lors de cette conversion, on filtre et transcrit les résultats du calcul précédent.
Concernant les valeurs propres, on retient toutes les solutions calculées: réelles, complexes seules ou en couple.
Dans CALC_MODES avec OPTION=”SEPARE’/”AJUSTE”/”PROCHE”, deux variantes sont disponibles: la méthode des itérations inverses (“DIRECT”) et son accélération par quotient de Rayleigh (“RAYLEIGH”). Elles affinent les valeurs propres préalablement détectées par les heuristiques (‘SEPARE’ ou ’AJUSTE’) ou les estimations fournies par l’utilisateur (‘PROCHE‘).
Pour ce qui est de CALC_MODES avec OPTION=”BANDE”/”CENTRE”/”PLUS_*”/”TOUT”, il permet l’usage de quatre méthodes distinctes: la méthode de Bathe & Wilson (“JACOBI”), les méthodes de sous-espace de type Lanczos (“TRI_DIAG “ ) et Sorensen (“SORENSEN”) et la méthode globale QZ (‘QZ’).
Concernant les vecteurs propres, on force leur \(B\) -orthonormalisation uniquement en GEP symétrique réel (sinon on ne peut pas définir de \(B\) -produit scalaire). Avec la méthode de Sorensen et avec QZ, cette orthonormalisation est effectuée explicitement, à l’issu du calcul modal, via l’algorithme IGSM de Kahan-Parlett (cf. annexe 2). Pour les autres solveurs modaux, cette étape est incluse dans leurs procédures internes de calcul.
Lorsqu’on effectue une réorthogonalisation explicite, celle-ci ne concerne que les modes propres supposés appartenir au même espace propre ( cf. remarque ci-dessous). La théorie nous assure de l’orthogonalité des autres cas de figure. Cette orthogonalisation «ciblée» permet souvent de gagner au moins 50% du temps de calcul global de l’opérateur (parfois jusqu’à 90%).
Remarques:
Chacune de ces méthodes possède des tests d’arrêts internes. Sans compter que les méthodes de projection emploient des méthodes modales auxiliaires: Jacobi (cf. Annexe 3) pour ‘Bathe & Wilson’ et \(\text{QR}/\text{QL}\) (cf. Annexe 1) pour Lanczos et Arnoldi. Elles nécessitent aussi des tests d’arrêts. L’utilisateur a souvent accès à ces paramètres, bien qu’il soit chaudement recommandé, au moins dans un premier temps, de conserver leurs valeurs par défaut.
La réorthogonalisation effectuée en post-traitement de Sorensen et de QZ est paramétrable: une valeur négative du coefficient PARA_ORTHO_SOREN indique que celle-ci doit être totale et non ciblée (du coup le calcul sera beaucoup plus coûteux); la valeur de SEUIL_FREQ/CHAR_CRIT permet d’augmenter ou de réduire le nombre de modes à réorthogonaliser (deux modes sont considérés comme appartenant au même espace propre s’ils sont inférieurs à ce critère en valeur absolue et si leur écart l’est aussi). Normalement ces paramètres (de niveau développeur) ne doivent pas être modifiés dans une étude standard.
Post-traitements de vérification#
Cette dernière partie regroupe les post-traitements qui vérifient le bon déroulement du calcul . Ils sont de deux types:
Norme [8]_
du résidu du problème initial
\(\begin{array}{c}\begin{array}{c}u\mathrm{\Leftarrow }\frac{u}{{\mathrm{\parallel }u\mathrm{\parallel }}_{\infty}}\\ \text{Si}\mid \lambda \mid >\text{SEUIL\_FREQ}\text{alors}\end{array}\\ \frac{{\mathrm{\parallel }\text{Au}-\lambda \text{Bu}\mathrm{\parallel }}_{2}}{{\mathrm{\parallel }\text{Au}\mathrm{\parallel }}_{2}}?<\text{SEUIL},\\ \text{Sinon}\\ \begin{array}{c}{\mathrm{\parallel }\text{Au}-\lambda \text{Bu}\mathrm{\parallel }}_{2}?<\text{SEUIL},\\ \text{Fin si}.\end{array}\end{array}\)
Algorithme 1. Test de la norme du résidu.
Cette séquence est paramétrée par les mot-clés SEUIL et SEUIL_FREQ, appartenant respectivement aux mot-clés facteur VERI_MODE et CALC_FREQ. D’autre part, ce post‑traitement est activé par l’initialisation à “OUI” (valeur par défaut) de STOP_ERREUR dans le mot-clé facteur VERI_MODE. Lorsque cette règle est activée et non-respectée, le calcul s’arrête, sinon l’erreur est juste signalée par une alarme. On ne saurait bien sûr que trop recommander de ne pas désactiver ce paramètre passe-droit !
Comptage des valeurs propres
Ce post-traitement est mis en place uniquement dans le cas de matrices réelles symétriques et il n’est activé par défaut que si OPTION=”BANDE”,”CENTRE”,”PLUS_*”,”TOUT”. Dans ce cadre, il permet de vérifier que le nombre de valeurs propres contenues dans une bande test \(\left[{\sigma}_{1},{\sigma}_{2}\right]\) est égal au nombre détecté par l’algorithme. Cette procédure de comptage s’active en deux temps: détermination de la bande test (cf. figure et algorithme ci-dessous) puis calcul de Sturm proprement dit. Ce calcul de Sturm fait l’objet d’une documentation spécifique (cf. [R5.01.04]), on ne détaille donc ici que l’étape préliminaire qui est spécifique aux post-traitements de CALC_MODES avec OPTION=”BANDE”/ “CENTRE”/”PLUS_*”/”TOUT”.
L’inclusion de la bande initiale [9]_ dans \(\left[{\sigma}_{i},{\sigma}_{f}\right]\) est conduite afin de détecter d’éventuels problèmes de clusters ou de multiplicités aux bornes initiales.
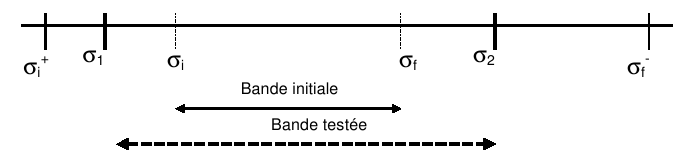
Figure 3.7-1. Comptage des valeurs propres par le test de Sturm en GEP réel symétrique.
En notant \({\sigma}_{i}^{+}\) et \({\sigma}_{f}^{-}\) , respectivement, la plus grande et la plus petite valeur propre non demandée par l’utilisateur et englobant la bande initiale (cf. figure 3.7-1), on a l’algorithme de construction de la bande test suivant:
\(\begin{array}{c}\text{Si}{\sigma}_{i}^{+}\text{existe}(\text{resp}.{\sigma}_{f}^{-})\text{et si}\frac{\mid {\sigma}_{i}^{+}-{\sigma}_{i}\mid }{\mid {\sigma}_{i}\mid }<\text{PREC\_SHIFT}(\text{resp}.\frac{\mid {\sigma}_{f}^{-}-{\sigma}_{f}\mid }{\mid {\sigma}_{f}\mid })\\ \\ \text{alors}{\sigma}_{1}=\frac{{\sigma}_{i}^{+}+{\sigma}_{i}}{2}(\text{resp}.{\sigma}_{2}=\frac{{\sigma}_{f}^{-}+{\sigma}_{f}}{2}),\\ \text{Sinon}\\ {\sigma}_{1}={\sigma}_{i}(\text{1-}\text{sign}({\sigma}_{i})\text{PREC\_SHIFT})(\text{resp}.{\sigma}_{2}={\sigma}_{f}(\text{1+sign}({\sigma}_{f})\text{PREC\_SHIFT})),\\ \text{Fin si}.\end{array}\)
Algorithme 2. Construction de la bande test pour le test de Sturm.
Cette séquence de construction de la bande test, via les modes calculés et non demandés, n’est active que pour les méthodes de Lanczos et de Bathe & Wilson de CALC_MODES avec OPTION=”BANDE”/ “CENTRE”/”PLUS_*”/”TOUT”. Avec les méthodes de Sorensen et QZ, on ne sélectionne que les modes demandés et donc les bornes de l’intervalle de test sont déterminées par la seconde partie de l’algorithme n°2.
Cet algorithme est paramétrée par le mot-clé PREC_SHIFT du mot-clé facteur VERI_MODE. Les encadrés ci-dessous affichent la trace des messages d’erreurs lorsque ces post-vérifications se déclenchent.
Vérification à posteriori des modes
<E> <ALGELINE5_15>
pour le concept MODE_B_1, le mode numéro 5
de fréquence 84.821272
a une norme d’erreur de 0.000102 supérieure au seuil admis 0.000001.
Vérification à posteriori des modes
<E> <ALGELINE5_23>
pour le concept MODET,
dans l’intervalle [28.987648 , 5071.142099]
il y a théoriquement 6 fréquence(s) propres()
et on en a calculé 5.
Ce problème peut apparaître lorsqu’il y a des modes multiples (structure avec symétries) ou une forte densité modale.
Exemple 3. Impressions dans le fichier message des post-vérifications.
La procédure de comptage est désactivable via le mot-clé VERI_MODE/STURM. De même, lorsque au moins une des deux étapes de post-vérification (norme du résidu ou procédure de comptage) n’est pas respectée, la suite des événements est pilotée par STOP_ERREUR (si “OUI” le calcul s’arrête, sinon l’erreur est juste signalée par une alarme). On ne saurait bien sûr que trop recommander de ne pas désactiver ces paramètres “passe-droit” !
Remarques:
Lorsqu e avec les options “BANDE”,”CENTRE”,”PLUS_*” ou “TOUT” on active la procédure d’amélioration (mot-clé AMELIORATION=”OUI” ), le test de Sturm n’est pas effectué à l’issue de la première étape de résolution (par une méthode de sous-espace). C’est inutile, puisque ces modes sont susceptibles d’être modifiés dans la deuxième étape, celle d’amélioration (par quelques itérations de méthode des puissances inverses). Ce n’est qu’après cette étape qu’on effectue toutes les vérifications: résidu, test de Sturm et appartenance à la bande initiale (si OPTION=”BANDE” ).
Le test de Sturm peut aussi être activé avec les options “ PROCHE “, “ SEPARE “ et “ AJUSTE “. Il ne rempli talors pas tout à fait la même fonction. En effet, ces options servent à affiner des estimations initiales de valeurs propres et à calculer les vecteurs propres associés: la présence de “trous” dans le spectre calculé est a lors possible et licite. En revanche, l es autres options (” BANDE “ etc…) doivent calculer tous les modes spécifiés, sans en oublie r: aucun trou dans le spectre n’est alors toléré.
Avec “PROCHE”, “SEPARE” et “AJUSTE”, l” é mission de messages d’alarme ou d’erreur ne r é vèle donc pas forcément de problème numérique mais peut être normal suivant la mise en données. Ainsi si on spécifie FREQ=(100.0,300.0) , que l’option “ PROCHE “ affine ces valeurs en (99.0, 299.0) et que le spectre du problème mécanique comporte normalement aussi la valeur 200.0 , le test de Sturm (si on l’active) va arrêter le calcul sur un message d’erreur alors que cette absence de la valeur 200.0 est normale. L’utilisateur n’a pas demandé à l’affiner! Avec le paramétrage initial FREQ=(100.0, 200.0, 300.0) cette alarme n’apparaîtrait plus.
Dans ce cadre, l’activation du test de Sturm est donc à manier avec précaution. Fonctionnellement, il sert plutôt au report des tests de vérification lorsqu’on active le mot-clé AMELIORATION à l’issue d’une méthode de sous-espace (cf. remarque précédente).
Affichage dans le fichier message#
Dans le fichier message sont mentionnées les informations relatives aux modes retenus. Par exemple, dans le cas le plus courant d’un GEP symétrique réel (modes propres réels), on précise le solveur modal utilisé, la liste des fréquences \({f}_{i}\) retenues (FREQUENCE) et leur norme d’erreur (NORME D’ERREUR, cf. algorithme n°1).
CALCUL MODAL: METHODE GLOBALE DE TYPE QR
ALGORITHME QZ_SIMPLE
NUMERO FREQUENCE (HZ) NORME D’ERREUR
1 1.67638E+02 2.47457E-11
2 1.67638E+02 1.48888E-11
3 1.05060E+03 2.00110E-12
4 1.05060E+03 1.55900E-12
Exemple 4a. Impressions dans le fichier message des valeurs propres retenues lors de GEP à modes réels. Extrait du cas-test forma11a.
Pour un GEP à modes complexes (non symétrique réel ou complexe symétrique [10]_ ), contrairement aux QEP[Boi09], Code_Aster ne filtre pas les valeurs propres conjuguées des complexes quelconques. Il les conserve toutes et les affiche par ordre croissant de partie réelle. Ainsi, les colonnes FREQUENCE et AMORTISSEMENT regroupent, respectivement, \({f}_{i}=\frac{{\lvert}{\lambda}_{i}{\rvert}}{2\pi}\) et \({\xi}_{i}=\frac{\text{Im}({\lambda}_{i})}{{ \lvert}{\lambda}_{i}{\rvert}}\) .
CALCUL MODAL: METHODE D’ITERATION SIMULTANEE
METHODE DE SORENSEN
NUMERO FREQUENCE (HZ) AMORTISSEMENT NORME D’ERREUR
1 5.93750E+02 4.99981E-03 4.53561E-16
2 9.45536E+02 4.99981E-03 1.54551E-15
3 3.51473E+03 4.99981E-03 1.11150E-15
Exemple 4b. Impressions dans le fichier message des valeurs propres retenues lors de GEP à modes complexes. Extrait du cas-test zzzz208a.
Maintenant que le contexte des GEPs dans Code_Aster a été brossé, nous allons nous intéresser plus particulièrement aux méthodes de type puissance et à leur implantation dans l’opérateur CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”].
Méthode des puissances inverses (CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”])#
Introduction#
Cette méthode n’est accessible dans Code_Aster que pour le cas des matrices à coefficients réels. On se limitera donc à ce cas dans la suite de ce chapitre. Pour calculer plusieurs valeurs propres du problème généralisé, on n’utilise pas la méthode générale des itérations inverses telle quelle .
On peut, par exemple, la combiner à une technique de déflation [11]_ de manière à filtrer automatiquement l’information spectrale mise à jour pour ne plus la retrouver à l’itération suivante. Avec la déflation par restriction [12]_ de Wielandt on construit itérativement l’opérateur de travail (dans le cas symétrique), en notant \(({\mu}_{k},{\mathrm{u}}_{k})\) le mode à filtrer
\({\mathrm{A}}_{k+1}={\mathrm{A}}_{k}-{\mu}_{k}{\mathrm{u}}_{k}{\mathrm{u}}_{k}^{\mathrm{t}}\) .
Cette stratégie ,qui n’appréhende pas les multiplicités, doit être complétée par un critère de Sturm. D’autre part, le fait de travailler en arithmétique finie et de ne pas construire effectivement l’opérateur \({A}_{k}\) à chaque itération, contraint à mâtiner cette démarche de processus d’orthogonalisation performants.
Toutes ces complications ont conduit à choisir une autre voie, qui se décompose en deux parties:
La localisation des valeurs propres (détermination d’une valeur approchée de chaque valeur propre contenue dans un intervalle donné par une technique de bissection , affinée ou non, par une méthode de la sécante ).
L’amélioration de ces estimations et le calcul de leurs vecteurs propres associés par une méthode d’itérations inverses .
La recherche d’une valeur approchée pour chaque valeur propre considérée est sélectionnée dans le mot-clé facteur CALC_FREQ via OPTION:
Si OPTION=”SEPARE”, dans chaque intervalle de fréquences définies par le mot-clé FREQ, une valeur approchée de chaque valeur propre contenue dans cet intervalle est calculée en utilisant la méthode de dichotomie (cf. §4.2.1).
Si OPTION=”AJUSTE”, on effectue tout d’abord les mêmes opérations que précédemment et ensuite, partant de ces approximations, on affine le résultat par la méthode de la sécante.
Pour ces deux options, on calcule en même temps la position modale de chaque valeur propre ce qui permet de détecter les modes multiples. Soit on ne retient que les NMAX_FREQ fréquences les plus basses contenues dans l’intervalle maximal spécifié par l’utilisateur, soit on calcule toutes les valeurs de cet intervalle (si NMAX_FREQ=0).
Si OPTION=”PROCHE”, les fréquences données par le mot-clé FREQ, sont considérées comme les valeurs approchées des valeurs propres cherchées.
Remarques:
Bien sûr, comme on l’a déjà précisé, ces options ne sont à utiliser que pour déterminer ou affiner quelques valeurs propres. Pour une recherche plus étendue, il faut utiliser les autres options de recherche.
Avec l’option “PROCHE”, on ne peut pas calculer de modes multiples.
C’est un algorithme coûteux car il fait beaucoup appel au test de Sturm et donc à ses factorisations associées.
Les bornes des intervalles de recherche sont fournies par FREQ ou CHAR_CRIT suivant l’initialisation de TYPE_RESU.
Nous allons maintenant détailler les différents algorithmes (et leurs paramétrages) qui sont mis en place dans la première partie du processus.
Localisation et séparation des valeurs propres#
Méthode de bissection#
Comme on l’a déjà vu précédemment, le corollaire 5bis de la loi d’Inertie de Sylvester (cf. § 3.5 ) permet de déterminer le nombre de valeurs propres contenues dans un intervalle donné en effectuant deux décompositions \(LD{L}^{T}\) . Ce critère peut donc conduire à raffiner l’intervalle jusqu’à n’englober qu’une valeur propre. Ce pilotage étant mis en place, on passe d’une itération à l’autre en utilisant le principe de la dichotomie .
Sur un intervalle de départ \([{\lambda}_{a},{\lambda}_{b}]\) , on opère donc de la façon suivante, connaissant \(pm({\lambda}_{a})\) et \(pm({\lambda}_{b})\) :

Algorithme 3. Méthode de Bissection.
On arrête le processus si on a découpé plus de NMAX_ITER_SEPARE fois l’intervalle de départ, ou si pour un intervalle donné, on a (\((\frac{\mid {\lambda}_{a}-{\lambda}_{b}\mid }{{\lambda}^{\text{*}}})\le \text{PREC\_SEPARE}\) dans ce cas on ne raffine plus la recherche dans cet intervalle). On obtient finalement une liste de fréquences. Dans chaque intervalle défini par les arguments de cette liste, se trouve une valeur propre ayant une certaine multiplicité. Comme approximation de cette valeur propre, on prend le milieu de l’intervalle.
Remarques:
On aurait pu utiliser comme critère le changement de signe du polynôme caractéristique, mais outre le fait qu’il est très coûteux à évaluer, il ne permet pas, tel quel, de détecter les multiplicités,
L’initialisation du processus peut s’effectuer de manière empirique suivant les besoins de l’utilisateur. Pour englober une partie du spectre on peut aussi utiliser les régionnements du plan complexe des théorèmes de Gerschgörin-Hadamard (sur \(\mathrm{A},{\mathrm{A}}^{\mathrm{T}}\) …). Dans cette optique, la méthode de bissection peut s’avérer plus efficace qu’un QR en présence de cluster. Sa convergence, bien que linéaire, est en effet majorée par \(1/2\) alors que celle de QR peut tendre vers 1[LT86].
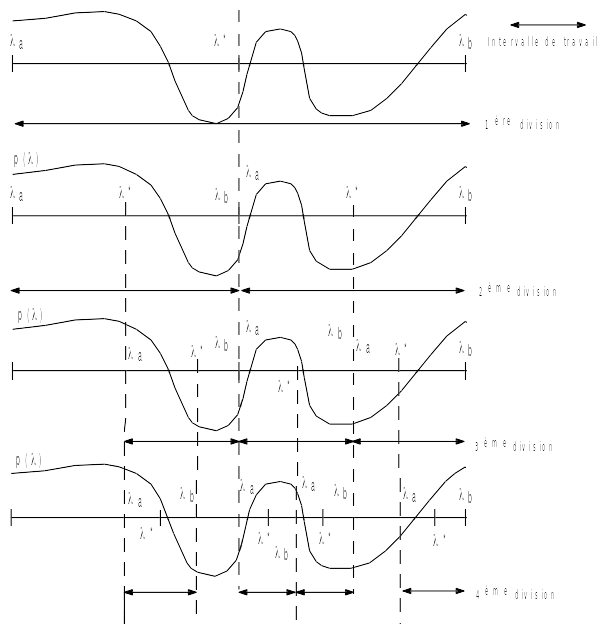
Figure 4.2-1. Méthode de bissection.
Méthode de la sécante#
La méthode de la sécante est une simplification de la méthode de Newton-Raphson . A l’étape quelconque , \(k\) connaissant une valeur \({\lambda}_{k}\) et en approximant la fonction non linéaire \(p(\lambda )\) par sa tangente en ce point, on détermine la prochaine valeur \({\lambda}_{k+1}\) comme étant l’intersection de cette droite avec l’axe des \(\lambda\) , et ainsi de suite, suivant le schéma itératif
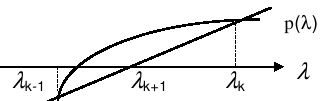
\({\lambda}_{k+1}={\lambda}_{k}-p({\lambda}_{k})\frac{{\lambda}_{k}-{\lambda}_{k-1}}{p({\lambda}_{k})-p({\lambda}_{k-1})}\)
Figure 4.2-2. Méthode de la sécante.
La tangente étant approximée par une différence finie afin de ne pas avoir à calculer de dérivée de \(p(\lambda )\) , seule l’estimation du polynôme est requise. On considère qu’on a atteint la convergence quand \(\frac{\mid {\lambda}_{k+1}-{\lambda}_{k}\mid }{{\lambda}_{k}}<\text{PREC\_AJUSTE}\) et, par ailleurs, on se limite à NMAX_ITER_AJUSTE itérations si ce critère n’est pas atteint.
Remarques:
Cette méthode a une convergence presque quadratique lorsqu’elle est proche de la solution, dans le cas contraire, elle peut diverger. D’où l’intérêt de combiner la méthode de bissection avec cette approche. Cette stratégie élégante de combiner bissection et sécante a été initiée par Van Wijngaardeen et Dekker(1960).
Si on ne réactualise par le calcul du dernier point dans la formule de la sécante (\({\lambda}_{k+1}={\lambda}_{0}\) ), on retrouve la classique méthode de la «fausse position» [13]_
. Celle-ci converge moins vite (tout en requièrant une évaluation de fonction par itération), mais elle est robuste et stable (comme la méthode de bissection). On est sûr d’améliorer l’évaluation initiale.
On montre que la méthode de la sécante réalise le meilleur compromis «vitesse de convergence/nombre d’évaluations de fonction par itération».
La méthode de la sécante s’appuie sur une interpolation linéaire entre les deux derniers itérés ( \({\lambda}_{k+1},p({\lambda}_{k+1})\) ) et ( \({\lambda}_{k},p({\lambda}_{k})\) ). En généralisant ce procédé à un ordre d’interpolation supérieure, c’est-à-dire les trois derniers itérés, on retrouve la méthode de Müller-Traub utilisée pour les QEP avec CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”][Boi09].
Nous allons maintenant détailler l’algorithme des puissances inverses (couplé à une accélération de Rayleigh) constituant la seconde partie du processus.
Méthode des puissances inverses#
Principe#
Pour déterminer la valeur propre du problème généralisé \(\mathrm{A}\mathrm{u}=\lambda \mathrm{B}\mathrm{u}\) la plus proche en module de \(\sigma\) , on applique la méthode des puissances à l’opérateur \({(A-\sigma B)}^{-1}B\) . En fait, on ne construit que la matrice factorisée [14]_ \({\mathrm{A}}^{\sigma}={(\mathrm{A}-\sigma \mathrm{B})}^{-1}\) et cela revient à traiter le problème généralisé \({({\mathrm{A}}^{\sigma})}^{\text{-1}}\mathrm{B}\mathrm{u}=\underset{\mu}{\underset{\underbrace{}}{\frac{1}{\lambda -\sigma }}}\mathrm{u}\) . La méthode des puissances convergeant prioritairement vers les valeurs propres de plus fort module (en \(\mu\) ), on capturera ainsi les \(\lambda\) les plus proches du shift.
Le principe est le suivant, connaissant une estimation \(\sigma\) de la valeur propre recherchée et partant d’un vecteur initial normalisé \({\mathrm{y}}_{0},\) on construit une suite de vecteurs propres approchés \({({\mathrm{y}}_{k})}_{k}\) par la formule récurrente

Algorithme 4. Méthode des puissances inverses.
Avec \({\lambda}_{1,}{\lambda}_{2}\) … les premières valeurs propres (de vecteur propre \({\mathrm{u}}_{i}\) ) les plus proches en module de \(\sigma\) , on montre que l’on a une convergence linéaire de \({\mathrm{y}}_{k}\to {\mathrm{u}}_{1}\) et une convergence quadratique de \({\mu}_{k}\to \frac{1}{\mid {\lambda}_{1}-\sigma \mid }\) et \(\frac{\tilde{{\mathrm{y}}_{k}}(i)}{\tilde{{\mathrm{y}}_{k-1}}(i)}\to \frac{1}{\mid {\lambda}_{1}-\sigma \mid }(i=\mathrm{1....n})\) (le facteur de convergence de ces suites est de l’ordre de \(\frac{\mid {\lambda}_{1}-\sigma \mid }{\underset{i\ne 1}{\min}\mid {\lambda}_{i}-\sigma \mid }\) ).
Remarques:
Ce résultat n’est acquis (au facteur de convergence près) que lorsque la valeur propre dominante (ici celle la plus proche en module du shift) est unique. Dans le cas contraire, des résultats restent cependant possibles, même dans le cadre complexe, mais l’analyse rigoureuse de la convergence de cet algorithme est encore incomplète[GL89][Vau00].
En théorie, ces résultats nécessitent que le vecteur initial ne soit pas orthogonal au sous-espace propre à gauche recherché. En pratique, les erreurs d’arrondis évitent ce problème (cf. [LT86] pp500-509).
Même si l’estimation de la valeur propre est grossière, l’algorithme fournit rapidement une très bonne estimation du vecteur propre.
L’inconvénient majeur de cette méthode est qu’il faut effectuer une factorisation pour chaque valeur propre à calculer.
En général on travaille en norme euclidienne ou en norme infinie, mais pour faciliter les calculs post‑modaux on cherche ici à \(B\) -normaliser les vecteurs propres (lorsque \(B\) est indéfinie, on travaille avec la pseudo-norme associée). L’algorithme de base peut être réécrit en posant \({\mathrm{z}}_{0}=\mathrm{B}{\mathrm{y}}_{0}\)

Algorithme 5. Méthode des puissances inverses avec \(B\) -pseudo-norme.
Notons que \(\rho ({y}_{k})\to \frac{1}{\mid {\lambda}_{1}-\sigma \mid }\) . Cette présentation évite les produits matrice-vecteur par la matrice \(B\) lors du calcul des produits scalaires et préfigure déjà le coefficient de Rayleigh du paragraphe suivant. On observe que le facteur de convergence est d’autant plus petit que le décalage spectral \(\sigma\) est proche de la valeur propre cherchée et donc que \(A-\sigma B\) est proche de la singularité . Cela n’est en fait pas préjudiciable au processus car l’erreur faite en résolvant le système est « principalement » dans la direction engendrée par le vecteur propre qui est la direction cherchée. Cela signifie que lors de la résolution de \({\mathrm{A}}^{\sigma}{\mathrm{y}}_{k}={\mathrm{z}}_{k+1}\) , on ne trouve pas la solution exacte \({\mathrm{y}}_{k}\) mais que les erreurs d’arrondis conduisent à solution voisine de la forme \({\tilde{\mathrm{y}}}_{k}={\mathrm{y}}_{k}+\mathrm{w}\) . Celle-ci est proportionnelle à la solution exacte, mais comme la normalisation est arbitraire, tout se passe correctement[Par80].
Remarque:
Ce mauvais conditionnement, loin d’avoir un effet défavorable, améliore même la convergence de l’algorithme.
Cet algorithme est donc utilisé pour améliorer le vecteur propre associé à la valeur approximée de la phase 1. Pour affiner cette estimation de la valeur propre, on introduit un quotient de Rayleigh.
Méthode d’itération du quotient de Rayleigh#
Rappelons que le quotient de Rayleigh appliqué au problème généralisé se définit par le nombre \(R(x)\) , avec \(x\) un vecteur non nul de \({\mathrm{ℝ}}^{n}\) , tel que:
\(R(\mathrm{x})=\frac{{\mathrm{x}}^{\mathrm{T}}\mathrm{A}\mathrm{x}}{{\mathrm{x}}^{\mathrm{T}}\mathrm{B}\mathrm{x}}\)
Ce quotient possède la propriété remarquable de stationnarité au voisinage de tout vecteur propre et d’atteindre un extremum (local) qui est la valeur propre correspondante: pour chaque \(x\) fixé, \(R(x)\) minimise \(\lambda \to {\parallel (A-\lambda B)x\parallel }_{2}\) .
Ce que nous pouvons traduire par « si \(x\) est une approximation d’un vecteur propre du système \(Ax=\lambda Bx\) , alors \(R(x)\) est une approximation de la valeur propre associée au vecteur \(x\) « , et réciproquement, nous avons vu que si on disposait d’une bonne estimation d’une valeur propre, la méthode des itérations inverses permettait d’obtenir une bonne estimation du vecteur propre correspondant. D’où l’idée de combiner ces deux propriétés en considérant l’algorithme d’itération inverse avec décalage spectral pour lequel on réévalue, à chaque itération, la valeur propre via le quotient de Rayleigh. On obtient alors l’algorithme dit d’itérations du quotient de Rayleigh (en \(B\) -pseudo-norme)

Algorithme 6. Méthode d’itérations du quotient de Rayleigh avec \(B\) -pseudo-norme.
Pour le problème modal standard, on peut montrer[Par80] que la convergence de cet algorithme est cubique dans le cas où l’opérateur de travail est normal [15]_ ( a fortiori dans le cas hermitien) et au mieux quadratique dans les autres cas. Si on utilisait cette méthode sans la modifier, il faudrait à chaque itération du processus d’amélioration de chaque valeur propre, effectuer une factorisation \(\mathrm{L}\mathrm{D}{\mathrm{L}}^{\mathrm{T}}\) , ce qui serait très coûteux. D’où l’idée de n’effectuer [16]_ ce décalage de Rayleigh, que si on est dans un voisinage (notion arbitraire à définir) de la solution.
Remarque:
Dans un cadre plus général, certains auteurs ont introduit un algorithme dit «de bi-itérations du quotient de Rayleigh». Basé sur la stationnarité du bi-quotient \({R}_{b}(x,y)=\frac{{y}^{T}Ax}{{y}^{T}Bx}\) au voisinage des vecteurs propres à droite et à gauche, il fournit (en non hermitien) les deux types de vecteurs propres. Son coût est cependant rédhibitoire car il requiert deux fois plus de factorisations (cf. B.N.Parlett 1969 [Par80]).
Implantation dans Code_Aster#
Ce décalage spectral n’est activé que si le mot-clé OPTION du mot-clé facteur CALC_MODE est initialisé à “RAYLEIGH”. Par défaut, on a “DIRECT” et le décalage est alors classique (correction globale plutôt que progressive de la valeur propre). L’algorithme mis en place dans le code se découpe comme suit (en \(B\) -pseudo norme):
Initialisation de la valeur propre à partir de l’estimation de la première phase: \({\lambda}^{\text{*}}\) .
Calcul d’un vecteur initial \({\mathrm{y}}_{0}\) aléatoire vérifiant les conditions limites.
\(B\) -orthonormalisation de \({\mathrm{y}}_{0}\) par rapport aux modes précédemment calculés (si c’est un mode multiple d’après la première phase) par un Gram-Schmidt Modifié [17]_
(GSM).
Calcul de \({\delta}_{0}=\text{sign}({\mathrm{y}}_{0}^{T}\mathrm{B}{\mathrm{y}}_{0})\) .
Pour \(k=1\) ,NMAX_ITER faire
Résoudre \((\mathrm{A}-{\lambda}^{\text{*}}\mathrm{B}){\mathrm{y}}_{k}={\delta}_{k-1}\mathrm{B}{\mathrm{y}}_{k-1}\) .
\(B\) -orthonormalisation (éventuelle) de \({\mathrm{y}}_{k}\)
Calcul de la correction de la valeur propre \(c=\frac{{\mathrm{y}}_{k}^{T}\mathrm{B}{\mathrm{y}}_{k-1}}{{\mathrm{y}}_{k}^{T}\mathrm{B}{\mathrm{y}}_{k}}\) .
Si \(\mid \mid {\mathrm{y}}_{k}^{T}\mathrm{B}{\mathrm{y}}_{k-1}\mid -1\mid \le \mathit{PREC}\) alors
\({\lambda}^{\text{*}}={\lambda}^{\text{*}}+c\) ,
exit;
Sinon
Si OPTION=”RAYLEIGH’et si \(\mid c\mid \le 0.1{\lambda}^{\text{*}}\) alors
\({\lambda}^{\text{*}}={\lambda}^{\text{*}}+c\) ;
Fin si.
Fin si.
Fin boucle.
Algorithme 7. Schéma fonctionnel de la méthode des puissances inverses dans CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”].
La norme d’erreur maximale admissible PREC et le nombre maximal d’itérations autorisées NMAX_ITER sont des arguments du mot-clé facteur CALC_MODE.
Remarques:
Le vecteur propre étant \(B\) -normé, on considère avoir atteint la convergence lorsque la valeur absolue du produit scalaire impropre est proche de l’unité.
Pour éviter de prendre un vecteur initial \(B\) -orthogonal à la valeur propre cherchée on utilise une méthode de tirage aléatoire pour les composantes de ce vecteur.
D’autre part pour pouvoir déterminer des modes multiples ou proches, on utilise une \(B\) ‑orthogonalisation aux modes déjà calculés.
L’option « d’accélération » de l’algorithme par quotient de Rayleigh étant coûteuse, elle n’est utilisée à chaque itération que si on est au voisinage de la valeur propre recherchée.
Périmètre d’utilisation#
GEP à matrices réelles symétriques .
L’utilisateur peut spécifier la classe d’appartenance de son calcul (dynamique ou flambement) en initialisant le mot-clé TYPE_RESU. Suivant cette valeur, on renseigne le vecteur FREQ ou CHAR_CRIT.
Affichage dans le fichier message#
Dans le fichier message, les résultats sont affichés sous forme de tableau
————————————————————————
LE NOMBRE DE DDL
TOTAL EST: 192
DE LAGRANGE EST: 84
LE NOMBRE DE DDL ACTIFS EST: 66
VERIFICATION DU SPECTRE DE FREQUENCES (SUITE DE STURM)
LE NOMBRE DE FREQUENCES DANS LA BANDE ( 1.00000E-02, 6.00000E-02) EST 4
CALCUL MODAL: METHODE D’ITERATION INVERSE
DICHOTOMIESECANTEINVERSE
NUMERO FREQUENCE(HZ) AMORT NB_ITER/NB_ITER/PRECISION/NB_ITER/ PRECISION
4 1.97346E-02 0.00000E+00 4 6 2.97494E-07 4 1.22676E-07
5 2.40228E-02 0.00000E+00 4 5 4.21560E-05 3 4.49567E-09
6 4.40920E-02 0.00000E+00 3 5 2.19970E-05 3 2.62910E-09
7 5.23415E-02 0.00000E+00 3 5 2.34907E-07 5 1.32212E-07
VERIFICATION A POSTERIORI DES MODES
Exemple 4. Trace de CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”](GEP) dans le fichier message.
Avec l’option “PROCHE”, les colonnes « Dichotomie » et « Sécante » n’apparaissent pas, tandis qu’avec l’option “SEPARE”, seule la colonne « Sécante » disparaît. La dernière colonne précision regroupe des données intermédiaires et ne représente pas, comme pour le cas de CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”,”TOUT”], la norme d’erreur du résidu. C’est un artefact qui va être amené à disparaître.
Récapitulatif du paramétrage#
Récapitulons maintenant le paramétrage de l’opérateur CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”].
Opérande |
Mot-clé |
Valeur par défaut |
Références |
TYPE_RESU =”DYNAMIQUE” |
“DYNAMIQUE” |
§3.1 |
|
“MODE_FLAMB” |
§3.1 |
||
OPTION =‘SEPARE’ |
“AJUSTE” |
§4.1 |
|
‘AJUSTE’ |
§4.1 |
||
‘PROCHE’ |
§4.1 |
||
CALC_FREQ ou CALC_CHAR_CRIT |
FREQ |
§4.1 |
|
CHAR_CRIT |
§4.1 |
||
NMAX_FREQ |
0 |
§4.1 |
|
NMAX_ITER_SHIFT |
3 |
[Boi12] §3.2 |
|
PREC_SHIFT |
0.05 |
[Boi12] §3.2 |
|
SEUIL_FREQ |
1.E-02 |
§3.7 |
|
SOLVEUR_MODAL |
NMAX_ITER_SEPARE |
30 |
§4.2 |
PREC_SEPARE |
1.E-04 |
§4.2 |
|
NMAX_ITER_AJUSTE |
15 |
§4.2 |
|
PREC_AJUSTE |
1.E-04 |
§4.2 |
|
OPTION_INV=‘DIRECT’ |
“DIRECT” |
§4.3 |
|
‘RAYLEIGH’ |
§4.3 |
||
PREC_INV |
1.E-05 |
§4.3 |
|
NMAX_ITER_INV |
30 |
§4.3 |
|
VERI_MODE |
STOP_ERREUR=”OUI” |
“OUI” |
§3.7 |
“NON” |
|||
SEUIL |
1.E-02 |
§3.7 |
Tableau 4.6-1. Récapitulatif du paramétrage de CALC_MODES avec OPTIONparmi [“PROCHE”,”AJUSTE”,”SEPARE”] (GEP).
Remarques:
On retrouve toute la « tripaille » de paramètres liée aux pré-traitements du test de Sturm (NMAX_ITER_SHIFT, PREC_SHIFT) et aux post-traitements de vérification (SEUIL_FREQ, VERI_MODE).
Lors des premiers passages, il est fortement conseillé de ne modifier que les paramètres principaux notés en gras. Les autres concernent plus les arcanes de l’algorithme et ils ont été initialisés empiriquement à des valeurs standards.
Méthode de sous-espace (CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”])#
Introduction#
Le cas des GEP à modes complexes (cf. §3.1) peut être traité dans Code_Aster uniquement par les méthodes IRAM et QZ. Il est donc abordé au chapitre relatif à ces méthodes. Par soucis de lisibilité, on se limitera au cas des matrices à coefficients réels pour exposer les principes généraux des méthodes de sous-espace.
Si on souhaite seulement calculer les \(p\) éléments propres d’un problème généralisé d’ordre \(n\) où \(n\ll p\) (par exemple, les \(p\) plus petites valeurs propres ou toutes les valeurs propres comprises dans un intervalle donné), on a vu qu’il était préférable d’avoir recourt à des méthodes de sous-espace. Elles sont basées sur l’analyse de Rayleigh-Ritz qui consiste à projeter efficacement le problème considéré sur un sous espace de dimension \(m(p<m<n)\) et à rechercher certains éléments propres de ce problème projeté (beaucoup plus facile à traiter) à l’aide d’algorithmes robustes (QR ou QL pour Lanczos et IRAM, Jacobi pour la méthode de Bathe et Wilson).
Les critères d’efficacité de ladite projection sont:
La petite taille de l’espace de projection (directement liée aux complexités calcul et mémoire).
La facilité de sa construction.
La robustesse de la projection orthogonale [18]_
.
La mise sous une forme canonique de la matrice projetée.
La bonne approximation de la partie du spectre initial recherché par celui de l’opérateur projeté.
La minimisation des complexités calcul et mémoire et celle des effets d’arrondis (ceux-ci sont surtout liés aux problèmes d’orthogonalité soulevés par le 3ièmepoint).
On présentera tout d’abord l’analyse de Rayleigh-Ritz avant de détailler trois méthodes issues de cette analyse : la méthode de Lanczos, celle dite de Sorensen (IRA) et celle de Bathe et Wilson.
Analyse de Rayleigh-Ritz#
Considérons le problème modal standard d’ordre \(n\) , \(Au=\lambda u\) , et le sous-espace \(H\) de \({ℝ}^{n}\) engendré par une base orthonormée \(({\mathrm{q}}_{1,}{\mathrm{q}}_{2,}\mathrm{...},{\mathrm{q}}_{m})\) . Cette dernière constitue la matrice orthogonale \({\mathrm{Q}}_{m}\) permettant de définir l’opérateur de projection \({\mathrm{P}}_{m}={\mathrm{Q}}_{m}{\mathrm{Q}}_{m}^{T}\) .
La méthode de Galerkin utilisée par cette analyse consiste à résoudre le problème suivant
\(\lbrace \begin{array}{c}\text{Trouver}(\tilde{\lambda},\tilde{\mathrm{u}})\in \mathrm{ℝ}\times H\text{tel que}\\ {\mathrm{P}}_{m}(\mathrm{A}\tilde{\mathrm{u}}-\tilde{\lambda}\tilde{\mathrm{u}})=0\end{array}\mathrm{\iff }\lbrace \begin{array}{c}\text{Avec}\tilde{\mathrm{u}}={\mathrm{Q}}_{m}\mathrm{x},\text{trouver}(\tilde{\lambda},\mathrm{x})\in \mathrm{ℝ}\times {\mathrm{ℝ}}^{m}\text{tel}\text{que}\\ \underset{{\mathrm{B}}_{m}}{\underset{\underbrace{}}{{\mathrm{Q}}_{m}^{\text{*}}{\text{AQ}}_{m}}}\mathrm{x}=\tilde{\lambda}\mathrm{x}\end{array}\)
La recherche des éléments de Ritz (\(\tilde{\lambda},\tilde{u}\) ) qui nous intéressent revient donc à trouver les modes propres de la matrice de Rayleigh \({\mathrm{B}}_{m}={\mathrm{Q}}_{m}^{T}\mathrm{A}{\mathrm{Q}}_{m}\) .
Les valeurs propres restent inchangées dans les deux formulations, par contre connaissant un vecteur propre \(x\) de \({\mathrm{B}}_{m}\) on doit remonter à l’espace tout entier via la transformation \(\tilde{\mathrm{u}}={\mathrm{Q}}_{m}\mathrm{x}\) .
La démarche peut donc se résumer sous la forme:
Choix d’un espace \(H\) et d’une base \(({\mathrm{h}}_{1},{\mathrm{h}}_{2},\mathrm{...},{\mathrm{h}}_{m})\) représentée par \(H\) .
Orthonormalisation de la base

Calcul de la matrice de Rayleigh \({\mathrm{B}}_{m}:={\mathrm{Q}}_{m}^{\text{*}}{\text{AQ}}_{m}\)
Calcul des éléments propres de \({\mathrm{B}}_{m}:(\tilde{\lambda},\mathrm{x})\)
Calcul de ses éléments de Ritz: \((\tilde{\lambda},\tilde{\mathrm{u}}={\mathrm{Q}}_{m}\mathrm{x})\) ,
Test d’erreur via le résidu: \(\mathrm{r}=\mathrm{A}\tilde{\mathrm{u}}-\tilde{\lambda}\tilde{\mathrm{u}}\) .
Algorithme 8. Procédure de Rayleigh-Ritz.
Remarques:
Les éléments de Ritz sont en fait les modes propres de la matrice (d’ordre \(N\) ) de l’approximation de Galerkin \({\mathrm{C}}_{m}={\mathrm{P}}_{m}\mathrm{A}{\mathrm{P}}_{\mathit{m.}}\)
La complexité calcul de ce processus, de l’ordre au pire de \(O({m}^{2}(\mathrm{4n}+m))\) (beaucoup moins avec un bon espace, cf. Lanczos et IRAM), est sans commune mesure avec celle d’un bon QR (\(O({n}^{2})\) ) ou celle d’une itération du quotient de Rayleigh encapsulée dans un processus heuristique tel que celui développé dans CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”](\(\gg {\mathrm{pn}}^{3}\) ). Mais il est bien clair que ces méthodes sont plus complémentaires que concurrentes.
Pour estimer l’erreur commise en utilisant les éléments propres de la matrice \({\mathrm{B}}_{m}\) on a le résultat suivant.
Théorème 1
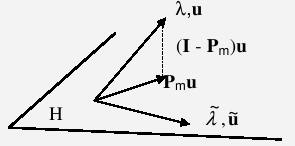
Soit \((\lambda ,u)\) un élément propre de la matrice diagonalisable (c’est le cas des matrices normales et des matrices non défectives (matrices dont toutes les valeurs propres ont même multiplicité arithmétique et géométrique) \(A\) et, \({\mathrm{B}}_{m}\) la matrice de Rayleigh associée, alors celle-ci admet une valeur propre \(\tilde{\lambda}\) vérifiant
\(\mid \lambda -\tilde{\lambda}\mid \le \beta \frac{{\mathrm{\parallel }(\mathrm{I}-{\mathrm{P}}_{m})\mathrm{u}\mathrm{\parallel }}_{2}}{{\mathrm{\parallel }{\mathrm{P}}_{m}\mathrm{u}\mathrm{\parallel }}_{2}^{2}}\)
où \(\beta\) est un nombre dépendant de \(\lambda\) , \(A\) et \({\mathrm{P}}_{m}\) .
Dans le cas hermitien le numérateur de cette majoration est au carré. Le vecteur propre associé, \(\tilde{u}\) , vérifie quant à lui
\(\sin(\mathrm{u},\tilde{\mathrm{u}})\le \beta \frac{{\mathrm{\parallel }(\mathrm{I}-{\mathrm{P}}_{m})-\mathrm{u}\mathrm{\parallel }}_{2}}{{\mathrm{\parallel }{\mathrm{P}}_{m}\mathrm{u}\mathrm{\parallel }}_{2}}\) .
Preuve
Cf. [LT86] pp531-537.
On montre que pour \(m\) assez grand, \(\beta\) peut être majoré par un nombre qui ne dépend que de \(A\) et de \(\underset{{\lambda}_{i}\ne {\lambda}_{j}}{\min}\mid {\lambda}_{i}-{\lambda}_{j}\mid\) . L’estimation du second membre \({\mathrm{\parallel }(\mathrm{I}-{\mathrm{P}}_{m})\mathrm{u}\mathrm{\parallel }}_{2}\) dépend du choix du sous-espace.
Remarque:
Le nombre \(\underset{{\lambda}_{i}\ne {\lambda}_{j}}{\min}\mid {\lambda}_{i}-{\lambda}_{j}\mid\) (et ses variantes) est omniprésent dans les analyses d’erreurs, de convergence ou de conditionnements spectraux. On voit, une fois de plus, l’importance de la séparation de spectre de travail sur la bonne tenue numérique des algorithmes.
Bien sûr, pour tenir compte de l’information spectrale déjà obtenue, voire pour l’améliorer ou la filtrer, on itère cette procédure de Rayleigh-Ritz en modifiant le sous-espace de projection. On enchaînera alors la construction de ce nouvel espace (récurrent du précédent) et ce processus de projection. Deux types d’espaces (chacun rattaché à des méthodes distinctes) sont les plus souvent usités.
Choix de l’espace de projection#
Deux choix d’espace de projection \(H\) sont les plus souvent mis en place:
Le premier, celui de la méthode de Bathe et Wilson(cf. § 8 METHODE=”JACOBI”) , consiste à choisir un sous espace \(H\) de dimension \(m\) puis à construire successivement:
\(\begin{array}{c}{\mathrm{H}}_{1}=\mathrm{A}\mathrm{H}\\ {\mathrm{H}}_{2}=\mathrm{A}{\mathrm{H}}_{1}={\mathrm{A}}^{2}\mathrm{H}\\ \mathrm{...}\\ {\mathrm{H}}_{i}=\mathrm{A}{\mathrm{H}}_{i-1}={\mathrm{A}}^{i}\mathrm{H}\end{array}\)
Cette méthode, qui tient à la fois de la généralisation sous forme bloc de la méthode des puissances et de la troncature de l’algorithme QR, conduit à un appauvrissement de l’espace de travail: \(\mathrm{dim}{H}_{i}\le \mathrm{dim}{H}_{i-1}\) . Pour ne pas retrouver toujours le même mode propre dominant il faut insérer dans le processus une réorthogonalisation (avec tous les problèmes de complexité calcul et d’arrondis que cela implique).
Le second, celui de la méthode de Lanczos(cf. § 6 METHODE=”TRI_DIAG”) et d’IRAM(cf. § 7 METHODE=”SORENSEN”) consiste à partir d’un vecteur initial \(y\) , à construire la suite d’espaces de Krylov (\({H}_{i}\) ) i=1,m où \({H}_{i}\) est l’espace engendré par la famille de vecteurs \((\mathrm{y},\text{Ay},...,{\mathrm{A}}^{i-1}\mathrm{y})\) . Ce dernier est appelé l’espace de Krylov de \(A\) et d’ordre i initié par \(y\) :
\({H}_{i}={K}_{i}(\mathrm{A},\mathrm{y})\mathrm{\equiv }\text{Vect}(\mathrm{y},\text{Ay},...,{\mathrm{A}}^{i-1}\mathrm{y})\) .
Ils vérifient la propriété suivante \(\mathrm{dim}{H}_{i}\le \mathrm{dim}{H}_{i+1}\) . Contrairement au choix précédent, on a donc un certain enrichissement de l’espace de travail. D’autre part, on verra qu’ils permettent de projeter de manière optimale au sens des critères définis précédemment.
Historiquement, le premier type d’espace a été très utilisé en mécanique des structures. Mais pour diminuer la complexité calcul liée à la taille des sous-espaces et aux orthogonalisations, on leur préfère désormais les méthodes de type Lanczos/Arnoldi.
Remarque:
On rencontre une variété impressionnante d’algorithmes utilisant un espace du premier type. Ils sont appelés « “itérations de sous-espace », « itérations orthogonales » ou encore « itérations simultanées ». Au-delà des différents vocables, il faut surtout retenir que ces adaptations concernent les stratégies de redémarrages [19]_
, les techniques d’accélération [20]_ et de factorisation mises en œuvre pour enrichir l’espace de travail. Il existe même des versions basées sur les puissances inverses permettant de calculer les p plus petits modes (cf. [LT86] pp538-45, [Vau00] pp49-54).
Pour ces méthodes de projection, en supposant que l’espace initial \(H\) ne soit pas trop pauvre suivant les \(p\) directions dominantes, le facteur de convergence du \(i\) ème mode au bout de \(k\) itérations s’écrit (lorsqu’ils sont rangés classiquement, c’est à dire par ordre décroissant de module):
\(O({\mid \frac{{\lambda}_{m+1}}{{\lambda}_{i}}\mid }^{k})\)
Il exprime clairement deux phénomènes:
La convergence prioritaire des modes dominants.
L’amélioration de ces convergences (et donc de leurs normes d’erreur pour un nombre d’itérations fixé) lorsque la taille du sous-espace augmente.
Pour transformer le problème modal généralisé en un problème standard on a recourt à des transformations spectrales. Elles permettent aussi d’orienter la recherche du spectre et d’améliorer la convergence (cf. § 3.6 ).
Choix du décalage spectral#
Pour calculer les plus petites valeurs propres voisines d’une fréquence donnée ou toutes les valeurs propres comprises dans une bande de fréquence donnée, on effectue un décalage spectral du problème généralisé. Soit \(\sigma\) la valeur de décalage, on transforme le problème initial \(Au=\lambda Bu\) en un problème standard décalé.
\({\mathrm{A}}^{\sigma}{\mathrm{B}}^{\text{-1}}\mathrm{u}=\mu \mathrm{u}\) avec \({\mathrm{A}}^{\sigma}=\mathrm{A}-\sigma \mathrm{B}\) et \(\mu =\lambda -\sigma\)
Cette transformation spectrale, dite de « shift simple « , est utilisée dans la méthode de Bathe et Wilson. Comme le processus détecte les plus petites valeurs propres en \(\mu\) , on capture progressivement celles qui sont les plus proches de \(\sigma\) (en module si le shift est réel et en partie réelle et imaginaire s’il est complexe).
On effectuant la transformation inverse ( » shift and invert « ) il advient
\({\mathrm{A}}_{\sigma}\mathrm{u}=\mu \mathrm{u}\) avec \({\mathrm{A}}_{\sigma}={(\mathrm{A}-\sigma \mathrm{B})}^{\text{-1}}\mathrm{B}\) et \(\mu =\frac{1}{\lambda -\sigma }\)
C’est le problème traité avec Lanczos et IRAM qui permet de calculer les plus grandes valeurs propres \(\mu\) donc les valeurs propres les plus proches du shift \(\sigma\) (en module). Dans le cas de la méthode IRAM pour des matrices à coefficients complexes, le shift est obligatoirement complexe.
Dans la commande CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”], il y a quatre façons de choisir ce shift (pour le flambement, la transposition aux niveaux de charges critiques est immédiate):
\(\sigma =0\) , on cherche les plus petites valeurs propres du problème de départ. Ceci correspond à OPTION=”PLUS_PETITE”.
\(\sigma ={\sigma}_{0}\) avec \({\sigma}_{0}={(2\pi {f}_{0})}^{2}\) , on cherche les fréquences proches de la fréquence FREQ= \({f}_{0}\) (OPTION=”CENTRE”).
\(\sigma =\frac{{\sigma}_{0}+{\sigma}_{1}}{2}\) avec \({\sigma}_{0}={(2\pi {f}_{0})}^{2}\) et \({\sigma}_{1}={(2\pi {f}_{1})}^{2}\) , on cherche toutes les fréquences comprises dans la bande \([{f}_{0,}{f}_{1}]\) (OPTION=”BANDE’avec FREQ={ \({f}_{0},{f}_{1}\) }).
\(\sigma ={\sigma}_{0}+j{\sigma}_{1}\) avec \({\sigma}_{0}={(2\pi {f}_{0})}^{2}\) et \({\sigma}_{1}=\eta \frac{{(2\pi {f}_{0})}^{2}}{2}\) on cherche les fréquences proches de la fréquence FREQ= \({f}_{0}\) et de l’amortissement réduit AMOR_REDUIT= \(\eta\) (OPTION=”CENTRE”). Cette approche est disponible seulement en dynamique avec un GEP à modes complexes: matrices \(\mathrm{A}\) et/ou \(B\) complexes symétriques ou réelles non symétriques (cf. tableau 1).
Le nombre de fréquences à calculer est donné en général par l’utilisateur à l’aide de NMAX_FREQ sous le mot-clé facteur CALC_FREQ. Mais pour l’option “BANDE”, il est déterminé automatiquement en utilisant le corollaire 3bis de R5.01.04.
Remarque:
On rappelle que la factorisation de la matrice de travail, tout comme les tests de Sturm de l’option “BANDE’sont tributaires d’instabilités numériques lorsque le shift est proche d’une valeur propre. Des traitements palliatifs, paramétrables par l’utilisateur, ont été implantés (cf. R5.01.04).
Méthode de Lanczos (SOLVEUR_MODAL= _F(METHODE=‘TRI_DIAG’))#
Introduction#
Cet algorithme, mis au point par Lanczos [Lan50] en 1950 , n’a guère été utilisé jusqu’au milieu des années 70. De prime abord très simple et efficace, il est le siège néanmoins de grandes instabilités numériques pouvant provoquer la capture de modes fantômes ! Celles-ci sont liées principalement à des problèmes de maintien d’orthogonalité entre les vecteurs engendrant l’espace de Krylov. La compréhension de ce type de comportement face à l’arithmétique finie des ordinateurs fut longue à exhumer. Depuis, de nombreuses solutions palliatives ont vu le jour et une abondante littérature couvre le sujet. Citons par exemple l’ouvrage de J.K. Cullum[CW85] qui lui est entièrement consacré, celui de B.N.Parlett[Par80] et la synthèse actualisée et exhaustive de J.L. Vaudescal[Vau00] (pp55-78).
Dans la suite de ce paragraphe, nous allons tout d’abord nous attarder sur le cadre théorique de fonctionnement de l’algorithme. Puis, avant de détailler la variante mise en place dans Code_Aster , nous nous attacherons au cadre réaliste de l’arithmétique finie.
Algorithme de Lanczos théorique#
Principe#
Son périmètre d’application recouvre les couples opérateur de travail-(pseudo)produit scalaire assurant l” hermiticité de \({\mathrm{A}}_{\sigma}\) . Il permet de construire itérativement une matrice de Rayleigh \({\mathrm{B}}_{m}\) de taillemodulable, tridiagonale et hermitienne (avec un véritable produit scalaire, sinon elle perd cette dernière propriété). Cette forme particulière facilite grandement le calcul des modes de Ritz: avec QR on perd alors un ordre de magnitude passant, lorsqu’on recherche \(p\) modes propres en projetant sur un sous-espace de taille \(m\) , de \(O(\mathrm{pm²})\) à \(O(\mathrm{20pm})\) . L’algorithme consiste à construire progressivement une famille de vecteurs de Lanczos \({\mathrm{q}}_{1,}{\mathrm{q}}_{2,}\mathrm{...},{\mathrm{q}}_{m}\) en projetant orthogonalement, à l’itération \(k\) , le vecteur \({\mathrm{A}}_{\sigma}{\mathrm{q}}_{k}\) sur les deux vecteurs précédents \({\mathrm{q}}_{k}\) et \({\mathrm{q}}_{k-1}\) . Le nouveau vecteur devient \({\mathrm{q}}_{k+1}\) et ainsi, de proche en proche, on assure structurellement l’orthogonalité de cette famille de vecteurs. Le processus itératif se résume ainsi.
\(\begin{array}{c}\begin{array}{c}{\mathrm{q}}_{0}=0,{\beta}_{0}=0.\\ \text{Calcul de}{\mathrm{q}}_{1}/\mathrm{\parallel }{\mathrm{q}}_{1}\mathrm{\parallel }=1.\end{array}\\ \text{Pour}\text{k=1,m}\text{faire}\\ \mathrm{z}={\mathrm{A}}_{\sigma}{\mathrm{q}}_{k}-{\beta}_{\text{k-1}}{\mathrm{q}}_{\text{k-1}},\\ {\alpha}_{k}=(\mathrm{z},{\mathrm{q}}_{k}),\\ \mathrm{v}=\mathrm{z}-{\alpha}_{k}{\mathrm{q}}_{k},\\ \begin{array}{c}{\beta}_{k}=\mathrm{\parallel }\mathrm{v}\mathrm{\parallel },\\ \text{Si}{\beta}_{k}\mathrm{\ne }0\text{alors}\end{array}\\ \begin{array}{c}{\mathrm{q}}_{\text{k+1}}=\frac{\mathrm{v}}{{\beta}_{k}},\\ \text{Sinon}\\ \text{Déflation};\\ \text{Fin si}.\end{array}\\ \text{Fin}\text{boucle}.\end{array}\) Algorithme 9. Lanczos théorique.
En notant, \({\mathrm{e}}_{m}\) le m ième vecteur de la base canonique, le vecteur résidu de la factorisation de Lanczos s’écrit \({\mathrm{R}}_{m}={\beta}_{m}{\mathrm{q}}_{m+1}{\mathrm{e}}_{m}^{T}\) .
n
\({\mathrm{B}}_{m}\)
m
\({\mathrm{Q}}_{m}\)
\({\mathrm{A}}_{\sigma}\)
\({\mathrm{Q}}_{m}\)
=
0
\(n\)
m
\({\mathrm{R}}_{m}={\beta}_{m}{\mathrm{q}}_{m+1}{\mathrm{e}}_{m}^{T}\)
m
\(m\)
Figure 6.2-1. Factorisation de Lanczos.
La matrice de Rayleigh prend alors la forme (en complexe avec un produit scalaire hermitien)
\({\mathrm{B}}_{m}=\left[\begin{array}{cccc}{\alpha}_{1}& {\stackrel{ˉ}{\beta}}_{1}& 0& 0\\ {\beta}_{1}& {\alpha}_{2}& ...& 0\\ 0& ...& ...& {\stackrel{ˉ}{\beta}}_{m-1}\\ 0& 0& {\beta}_{m-1}& {\alpha}_{m}\end{array}\right]\)
Par construction, cet algorithme nous assure des résultats suivants (en arithmétique exacte):
Les \({({\mathrm{q}}_{k})}_{k=1,m}\) constituent une famille orthonormale.
Ils engendrent l’espace de Krylov d’ordre \(m\) initié par \({\mathrm{q}}_{1}\) , \({\mathrm{K}}_{m}({\mathrm{A}}_{\sigma},{\mathrm{q}}_{1})=\text{Vect}({\mathrm{q}}_{1},{\mathrm{A}}_{\sigma}{\mathrm{q}}_{1},...,{\mathrm{A}}_{\sigma}^{m-1}{\mathrm{q}}_{1})\) .
Ils permettent de construire une matrice \({\mathrm{B}}_{m}\) tridiagonale, hermitienne et de taille modulable.
Le spectre de \({\mathrm{B}}_{m}\) n’admet que les m modes simples dominants sur lesquels \({\mathrm{q}}_{1}\) a une composante.
Remarques:
L’algorithme ne permet donc pas, en théorie, la capture de modes multiples. Cela peut s’expliquer en remarquant que toute matrice de Hessenberg [21]_
irréductible (donc a fortiori une matrice tridiagonale) n’admet que des modes simples.
Le coût d’une itération est faible, de l’ordre de celui d’un produit matrice-vecteur \({\mathrm{A}}_{\sigma}{\mathrm{q}}_{k},\) soit pour les \(m\) premières itérations une complexité calcul de \(O(\mathrm{nm}(c+5))\) (avec c le nombre moyen de termes non nuls sur les lignes de la matrice de travail). D’autre part, la complexité mémoire requise est faible car on n’a pas besoin de construire \({\mathrm{A}}_{\sigma}\) en entier, on a juste besoin de connaître son action sur un vecteur. Cette caractéristique est très intéressante pour résoudre des problèmes de grandes tailles[Vau00].
En général le domaine d’activité oriente le choix d’un vecteur de Lanczos initial, celui-ci doit par exemple appartenir à un espace de solutions admissibles (vérifiant des contraintes, des conditions limites…) ainsi qu’à l’ensemble image de l’opérateur. Ce dernier point est important car il permet d’enrichir plus rapidement la recherche modale en ne se limitant pas au noyau.
L’algorithme de Lanczos n’est qu’un moyen d’aborder les sous-espaces de Krylov. Sa généralisation aux configurations non symétriques est appelée algorithme d’Arnoldi (cf.§ 7.2 ).
Estimations d’erreurs et de convergences#
Du fait de la forme particulière de \({\mathrm{B}}_{m}\) , l’extraction des éléments de Ritz recherchés est simplifiée, et en plus, le résultat suivant nous permet rapidement ( via un produit de deux réels !) d’estimer leurs qualités.
Propriété 2
La norme euclidienne du résidu de l’élément de Ritz \((\tilde{\lambda},\tilde{\mathrm{u}}={\mathrm{Q}}_{m}\mathrm{x})\) est égale à
:math:`{mathrm{parallel }mathrm{r}mathrm{parallel }}_{2}={mathrm{parallel }(sigma -tilde{lambda}mathrm{I})tilde{mathrm{u}}mathrm{parallel }}_{2}=mid {beta}_{m}mid mid {mathrm{e}}_{m}^{T}mathrm{x}mid `
Preuve:
Triviale en prenant la norme euclidienne de la factorisation de Lanczos \({\mathrm{A}}_{\sigma}{\mathrm{B}}_{m}\mathrm{x}={\mathrm{Q}}_{m}{\mathrm{B}}_{m}\mathrm{x}+{\beta}_{m}{\mathrm{q}}_{m+1}{\mathrm{e}}_{m}^{T}\mathrm{x}\) où \({\mathrm{q}}_{m+1}\) est normé à l’unité.
Remarques:
Un résultat plus général, indépendant de toute méthode de résolution, nous assure que pour chaque mode propre \((\tilde{\lambda},x)\) de \({\mathrm{B}}_{m}\) , il existe un mode propre \((\tilde{\lambda},u)\) de \({\mathrm{A}}_{\sigma}\) tel que:
:math:`begin{array}{c}mid lambda -tilde{lambda}mid le frac{{mathrm{parallel }mathrm{r}mathrm{parallel }}_{2}^{2}}{gamma}\ mid sin(mathrm{u},tilde{mathrm{u}})mid le frac{{mathrm{parallel }mathrm{r}mathrm{parallel }}_{2}}{gamma}end{array}text{avec}gamma =underset{{lambda}_{i}mathrm{ne }tilde{lambda}}{min}mid {lambda}_{i}-{tilde{mathrm{u}}}^{T}{mathrm{A}}_{sigma}tilde{mathrm{u}}mid `
Donc, plus que la minimisation du résidu, le critère d’arrêt des méthodes de type Lanczos/Arnoldi \(\mid {\beta}_{m}\mid <\varepsilon\) permet d’approcher au mieux le spectre originel. Ces majorations ne sont accessibles que dans le cas hermitien.
Dans le cas général (et en particulier non normal) elles sont plus difficiles voire impossibles à construire sans information complémentaire (niveau de non-normalité, de «défectivité»..). L’estimation du résidu n’est alors plus le bon critère pour estimer la qualité des modes approximés.
Intéressons nous maintenant à la qualité de convergence de l’algorithme. Particularisons le théorème 2 pour cet algorithme. En bornant la norme d’erreur de \({\mathrm{\parallel }({\text{I-P}}_{m})\text{u}\mathrm{\parallel }}_{2}\) on obtient les majorations suivantes:
Théorème 3
Soit \(({\lambda}_{i},{\mathrm{u}}_{i})\) le i ème mode propre dominant de \({\mathrm{A}}_{\sigma}\) diagonalisable, il existe alors un mode de Ritz \((\tilde{{\lambda}_{i}},{\tilde{\mathrm{u}}}_{i})\) tel que:
\(\begin{array}{c}\mid {\lambda}_{i}-{\tilde{\lambda}}_{i}\mid \le \frac{{\alpha}^{2}}{\beta}{(\underset{j<i}{\Pi}\frac{{\lambda}_{j}-{\lambda}_{n}}{{\lambda}_{j}-{\lambda}_{i}})}^{2}{T}_{m-i}^{-2}({\gamma}_{i})\\ \mid \sin({\mathrm{u}}_{i},{\tilde{\mathrm{u}}}_{i})\mid \le \alpha (\underset{j<i}{\Pi}\frac{{\lambda}_{j}-{\lambda}_{n}}{{\lambda}_{j}-{\lambda}_{i}}){T}_{m-i}^{-1}({\gamma}_{i})\end{array}\)
avec \({\gamma}_{i}\text{=1+2}\frac{{\lambda}_{i}-{\lambda}_{\text{i+1}}}{{\lambda}_{\text{1+i}}-{\lambda}_{n}}\) , \({T}_{m-i}(x)\) le polynôme de Tchebycheff de degré \(m-i\) , \(\beta\) la constante du théorème 1 et \(\alpha =\frac{\beta}{{\mathrm{\parallel }{\mathrm{P}}_{m}{\mathrm{u}}_{i}\mathrm{\parallel }}_{2}}\tan({\mathrm{q}}_{1},{\mathrm{u}}_{i})\) .
Preuve:
Cf. [LT86] pp554-557.
Ces majorations indiquent que:
Si le vecteur initial n’a aucune contribution le long des vecteurs propres, on ne peut capturer lesdits modes (\(\alpha \to +\infty\) ).
On a prioritairement convergence des modes extrêmes et d’autant mieux que le spectre est séparé (ces méthodes sont moins sensibles aux clusters que les méthodes de types puissances itérées), sans tassement de valeurs propres (les fameux « clusters »).
L’erreur décroît lorsque \(m\) augmente (comme l’inverse du polynôme \({\mathrm{T}}_{\text{m-i}}(\mathrm{x})\) , donc comme l’inverse d’une exponentielle).
L’estimation sur les valeurs propres est meilleure que celle de leurs vecteurs propres associés.
Remarque:
La convergence de la méthode a été étudiée par P. Kaniel puis améliorée (et corrigée) par S.C.Paige ; On trouvera une synthèse de ces études dans le papier de Y. Saad[Saa80].
Regardons maintenant comment se comporte l’algorithme en arithmétique finie. Nous allons voir qu’il est le siège de phénomènes surprenants.
Algorithme de Lanczos pratique#
Problème d’orthogonalité#
Lors de la mise en œuvre effective de cet algorithme, on s’aperçoit que très vite les vecteurs de Lanczos perdent leurs orthogonalités . La matrice de Rayleigh n’est alors plus la matrice projetée de l’opérateur initial et le spectre capturé est de plus en plus entaché d’erreurs. Longtemps ce phénomène inéluctable a été attribué à tort aux effets d’arrondi de l’arithmétique finie. En 1980, C.C.Paige montra que la perte d’orthogonalité était surtout imputable à la convergence d’un mode propre . Ainsi, dès qu’on capture un mode dominant, on perturbe l’agencement des vecteurs de Lanczos précédents. Le résultat suivant exprime clairement ce paradoxe.
Propriété 4 (Analyse de Paige)
En reprenant les notations de l’algorithme 9 et en notant \(\varepsilon\) la précision machine, à l’itération \(k+1\) l’orthogonalité du nouveau vecteur de Lanczos s’exprime sous la forme:
\(\mid {\mathrm{q}}_{k+1}^{T}{\mathrm{q}}_{i}\mid =\frac{\mid {\mathrm{v}}^{T}{\mathrm{q}}_{i}\mid +\varepsilon {\mathrm{\parallel }{\mathrm{A}}_{\sigma}\mathrm{\parallel }}_{2}}{\mid {\beta}_{k}\mid }(i\le k)\)
Preuve:
Cf. [Pai00].
Le problème survient en fait lors de la normalisation du nouveau vecteur de Lanczos \({\mathrm{q}}_{k+1}\) . Lorsque ce mode converge, d’après la propriété 2, cela provient de la petitesse du coefficient \({\beta}_{k}\) et donc malgré l’orthogonalité théorique (\(\mid {\mathrm{v}}^{T}{\mathrm{q}}_{i}\mid =0(i\le k)\) ), l’orthogonalité effective est loin d’être acquise (\(\mid {\mathrm{q}}_{k+1}^{T}{\mathrm{q}}_{i}\mid \text{>>}\varepsilon (i\le k)\) ).
Le traitement numérique de ces problèmes a fait l’objet de nombreuses recherches depuis trente ans et de nombreuses stratégies palliatives ont été développées. Le choix de telle ou telle méthode dépend du type d’information spectrale requis et des moyens informatiques disponibles, la synthèse de JL.Vaudescal propose d’ailleurs un très bon survol de ces variantes:
Algorithme de Lanczos sans réorthogonalisation , développé par J.K.Cullum et R.A.Willoughby[CW85] qui consiste à expurger le spectre calculé de ses modes fantômes en étudiant les entrelacements des valeurs propres de la matrice de travail et d’une de ses sous‑matrices. Cette variante admet un faible surcoût calcul et mémoire pour déterminer les valeurs propres, mais elle complexifie (parfois grandement) la recherche des vecteurs propres.
Algorithmes de Lanczos avec réorthogonalisation totale (B.N.Parlett) ou sélective (J.Scott) qui consistent à chaque pas à réorthogonaliser le dernier vecteur de Lanczos obtenu par rapport à tous les vecteurs déjà calculés ou simplement par rapport aux vecteurs de Ritz convergés (cette variante permet ainsi de piloter dynamiquement la perte d’orthogonalité admissible). Ces variantes sont beaucoup plus coûteuses en complexité calcul (les réorthogonalisations automatiques) et mémoires (stockage des vecteurs précédents) mais elles s’avèrent plus efficaces et plus robustes.
Dans la variante de Newmann-Pipano[NP77] (METHODE=”TRI_DIAG”) du Code_Aster , c’est la stratégie de réorthogonalisation complète [22]_ qui a été choisie: le vecteur \({q}_{k+1}\) n’est donc pas tout à fait calculé comme dans l’algorithme théorique.
Remarques:
Ces problèmes de perte d’orthogonalité surviennent avec d’autant plus d’acuité que la taille du sous-espace augmente. C’est un argument supplémentaire pour la mise en place d’un processus itératif limitant cette taille.
Ces stratégies se déclinent vectoriellement ou par blocs, elles sont implantées dans des algorithmes simples ou itératifs. Ces derniers pouvant bénéficier de restarts explicites ou implicites, pilotés ou automatiques. La variante IRAM bénéficie ainsi d’un restart implicite calculé automatiquement.
Le point central de ces algorithmes est constitué par la méthode d’orthogonalisation mise en place. Tout le processus est dépendant de son succès et de sa robustesse. Aux transformations orthogonales de type Housholder ou Givens, très dispendieuses mais très robustes, on préfère désormais les algorithmes de type Gram-Schmidt Itératifs (IGSM) qui sont un meilleur compromis entre efficacité et complexité calcul (cf. Annexe 2). C’est d’ailleurs ce choix qui a été fait pour les variantes de Lanczos/Arnoldi mises en place dans le code.
La variante de réorthogonalisation sélective par rapport aux modes convergés revient à effectuer une déflation implicite par restriction sur l’opérateur de travail pour ne pas avoir à les recalculer (cf. § 4.1 ).
Capture des multiplicités#
On a vu qu’en théorie l’algorithme de Lanczos ne permettait pas, quelle que soit sa stratégie de réorthogonalisation, la capture théorique de modes multiples. En pratique , pour une fois, les effets d’arrondi viennent à la rescousse et « saupoudrent » de petites composantes le long de quasiment tous les vecteurs propres. On peut donc capturer des multiplicités , cependant elles peuvent être erronées et nécessitent un post-traitement de vérification complémentaire.
Remarque:
En fait, seule une version par blocs (G.Golub & R.Underwood 1979) peut nous permettre une détection correcte des multiplicités, du moins tant que la taille des blocs est suffisante. Cette version a été étendue (M.Sadkane[Sad93] 1993) à l’algorithme d’Arnoldi mais il serait dommage de se priver de la variante de Sorensen (IRAM) qui est plus efficace et plus robuste.
Phénomène de Lanczos#
Le succès de cet algorithme reposait au départ sur ce qu’on appelle le « phénomène de Lanczos ». Cette conjecture prédit que pour une taille de sous-espace suffisamment grande ( \(m\gg n\) ) on est capable de détecter tout le spectre (à charge par la suite de distinguer le «bon grain de l’ivraie») de l’opérateur de travail. Compte tenu des faibles pré-requis mémoire d’un Lanczos «basique» ( grosso modo une matrice tridiagonale et quelques vecteurs), ceci est particulièrement intéressant pour traiter des systèmes creux de très grandes tailles (les autres algorithmes de type puissances itérées ou QR nécessitent eux la connaissance de toute la matrice de travail).
Nous allons maintenant détailler (un peu) quelques éléments dont l’intérêt dépasse largement le cadre de cet algorithme.
Traitements complémentaires#
Détection d’espaces invariants#
Dans l’algorithme 8, la nullité du coefficient \({\beta}_{l-1}\) empêche la normalisation du nouveau vecteur et requiert un traitement annexe dit de déflation . Le sous-espace de Krylov calculé est alors un sous- espace invariant et son spectre est donc exact. En d’autres mots, les \(l-1\) premières valeurs propres exhumées par l’algorithme de soutien (QRou QL) sont celles de \({\mathrm{A}}_{\sigma}\) .
Pour continuer, il faut alors choisir un nouveau vecteur aléatoire respectant les conditions limites, l’orthogonaliser avec tous les vecteurs de Lanczos déjà calculés et construire une deuxième famille de vecteurs de Lanczos qu’on orthogonalise par rapport à la première famille constituant l’espace:
\({\mathrm{H}}_{l}={\mathrm{K}}_{l}({\mathrm{A}}_{\sigma},{\mathrm{q}}_{1})=\text{Vect}({\mathrm{q}}_{1},{\mathrm{A}}_{\sigma}{\mathrm{q}}_{1},...,{\mathrm{A}}_{\sigma}^{l-1}{\mathrm{q}}_{1})\)
La matrice tridiagonale obtenue a la forme suivante:
\({\mathrm{B}}_{m}=\left[\begin{array}{ccccccc}{\alpha}_{1}& {\stackrel{ˉ}{\beta}}_{1}& & & & & \\ {\beta}_{1}& {\alpha}_{2}& ...& & & 0& \\ & ...& ...& \mathrm{\simeq }0& & & \\ & & \mathrm{\simeq }0& {\alpha}_{l}& {\stackrel{ˉ}{\beta}}_{l}& & \\ & & & {\beta}_{l}& {\alpha}_{l+1}& ...& \\ & 0& & & ...& ...& {\stackrel{ˉ}{\beta}}_{m-1}\\ & & & & & {\beta}_{m-1}& {\alpha}_{m}\end{array}\right]\)
La factorisation de Lanczos intermédiaire (à l’ordre \(l\) ) s’écrit:
\({A}_{\sigma}{Q}_{l}={Q}_{l}{B}_{l}\)
Les valeurs \({({\alpha}_{k},{\beta}_{k})}_{k=1,l}\) sont obtenues à partir du premier vecteur aléatoire et les valeurs suivantes \({({\alpha}_{k},{\beta}_{k})}_{k=l+1,m}\) via un deuxième vecteur aléatoire. Pour détecter la nullité du terme extra-diagonal on utilise le critère numérique
\(\mid {\beta}_{l-1}\mid \le \text{PREC\_LANZOS}\mid {\alpha}_{l}\mid\) alors \({\beta}_{l-1}=0\) ,
où PREC_LANCZOS est initialisé sous le mot-clé facteur CALC_FREQ.
Remarques:
Un critère plus robuste retenu par les librairies mathématiques EISPACK, LAPACK et ARPACK utilise le terme diagonal précédent, un paramètre modulable \(c\) et la précision machine \(\varepsilon\) ,
\(\mid {\beta}_{l-1}\mid <c\varepsilon (\mid {\alpha}_{l-1}\mid +\mid {\alpha}_{l}\mid )\)
c’est ce critère qui à été retenu pour IRAM (mais l’utilisateur ne peut modifier le paramètre \(c\) , celui-ci est fixé à une valeur standard par le code), différents messages prévenant d’ailleurs l’utilisateur de la détection d’un espace invariant.
L’obtention d’un tel espace est tout à fait sympathique puisqu’elle nous assure de la très bonne qualité des premiers modes. De plus, on réduit la taille du problème en le scindant en deux parties: l’une résolue, l’autre à résoudre. De nombreuses techniques cherchent à reproduire artificiellement ce phénomène (cf. § 4.1 ).
Stratégies de redémarrages#
Pour limiter les problèmes d’orthogonalisation endémiques, borner les pré-requis mémoire et prendre en compte dynamiquement l’information spectrale déjà obtenue, des stratégies de redémarrages ont été couplées à l’algorithme de Lanczos. Il perd son caractère «simple» et devient «itératif». On itère les «restarts» jusqu’à satisfaire les critères de convergence souhaités. L’algorithme ne subit pas la convergence des modes imposés par le théorème 8 et il peut favoriser intéractivement celle de certains modes.
En théorie cependant, plus la taille du sous-espace est grande, meilleure est la convergence. Un compromis est donc à trouver entre la taille du sous-espace et la fréquence des redémarrages. Différents vecteurs de redémarrages peuvent être utilisés, s’écrivant généralement comme une somme pondérée des \(p\) modes propres recherchés (Y.Saad 1980)
\({\mathrm{q}}_{1}=\sum_{i=1}^{p}{\chi }_{i}{\mathrm{Q}}_{m}{\mathrm{x}}_{i}\)
En effet, si on redémarre avec un vecteur initial appartenant au sous-espace invariant engendré par les modes recherchés, on est alors sûr d’obtenir (avec un bon algorithme d’orthogonalisation) une norme résiduelle de l’ordre de la précision machine et des modes propres presque exacts. Outre la décision de déclencher le redémarrage, toute la problématique réside dans la recherche de ces poids \({\chi }_{i}\) . Nous verrons qu’avec IRAM, les restarts mis en place via des filtres polynomiaux implicites résolvent élégamment et automatiquement cette question.
Remarques:
Cette philosophie des restarts a été initiée par W.Karush(1951).
Les redémarrages basés sur les vecteurs de Schur associés à la décomposition spectrale recherchée semblent plus stables (J.Scott 1993).
Des critères d’efficacité ont été recherchés pour décider de l’opportunité d’un restart (B.Vital 1990).
Au lieu d’une simple combinaison linéaire de vecteurs propres, on peut déterminer un vecteur de redémarrage via des polynômes (Tchebychev en réel et Faber en complexe) permettant d’axer la recherche modale dans telle ou telle zone. On parle alors d’accélérations polynomiales explicites[Sad93].
Le paragraphe suivant va reprendre certains des concepts présentés jusqu’alors pour expliciter la variante mise en place dans le code.
Implantation dans Code_Aster#
Variante de Newmann & Pipano#
Cette variante développée par M.Newmann & A.Pipano[CW85][NP77] en 1977, est une méthode de Lanczos simple, en arithmétique réelle, avec réorthogonalisation totale ( via un GSM). Elle utilise le «shift and invert» classique mâtiné du pseudo-produit scalaire introduit par la matrice décalée \((A-\sigma B)\)
\(\underset{{\mathrm{A}}_{\sigma}}{\underset{\underbrace{}}{{(\mathrm{A}-\sigma \mathrm{B})}^{\text{-1}}\mathrm{B}}}\mathrm{u}=\underset{\lambda}{\underset{\underbrace{}}{\frac{1}{\mu -\sigma }}}\mathrm{u}\)
avec :
\(\mid \begin{array}{c}(x,y)={y}^{t}(A-\sigma B)x,\\ \delta =\text{sign}(x,x),\\ \parallel x\parallel =\delta {\mid (x,x)\mid }^{\frac{1}{2}}.\end{array}\)
Ce choix rend le couple «opérateur de travail-produit scalaire» symétrique et il est adapté aux matrices particulières de la mécanique des structures. On peut ainsi traiter des problèmes:
De structure libre et de fluide structure (\(A\) peut être singulière).
De flambement (\(B\) est indéfinie).
Le pseudo-produit scalaire introduit par la matrice décalée est ainsi régulier (\(\sigma\) répond à cette prérogative) et il permet de chercher des vecteurs de Lanczos \((A-\sigma B)\) -orthogonaux. La réorthogonalisation totale ne s’effectue que si elle s’avère nécessaire et ce critère est paramétrable.
Le prix à payer pour ce gain en robustesse est la perte de symétrie possible de la matrice de Rayleigh.
\({\mathrm{B}}_{m}=\left[\begin{array}{cccc}{\alpha}_{1}& {\gamma}_{1}& 0& 0\\ {\beta}_{1}& {\alpha}_{2}& ...& 0\\ 0& ...& ...& {\gamma}_{m-1}\\ 0& 0& {\beta}_{m-1}& {\alpha}_{m}\end{array}\right]\text{avec}\mid \begin{array}{c}{\gamma}_{i}={\delta}_{i}{\beta}_{i}\\ {\delta}_{i}=\text{sign}({\mathrm{q}}_{i+1},{\mathrm{q}}_{i+1})\end{array}\)
Après avoir été équilibrée et mise sous forme de Hessenberg supérieure, \({\mathrm{B}}_{m}\) est diagonalisée par une méthode QL implicite si elle reste malgré tout symétrique ou par une méthode QR sinon (cf. Annexe1). La différence en coût calcul entre ces solveurs reste négligeable face aux coûts des réorthogonalisations. Le schéma de Lanczos implanté devient alors:
\(\begin{array}{c}\begin{array}{c}\text{Tirage aléatoire de}{\mathrm{q}}_{\text{init}}.\\ {\tilde{\mathrm{q}}}_{1}={(\mathrm{A}-\sigma \mathrm{B})}^{-1}{({\mathrm{q}}_{\text{init}}(i).{\mathrm{u}}_{\text{lagr}}(i))}_{i}.\\ {\stackrel{ˆ}{\mathrm{q}}}_{1}={\mathrm{A}}_{\sigma}{({\tilde{\mathrm{q}}}_{1}(i).{\mathrm{u}}_{\text{bloq}}(i))}_{i}.\\ {\delta}_{1}=\text{sign}({\stackrel{ˆ}{\mathrm{q}}}_{1}^{T}(\mathrm{A}-\sigma \mathrm{B}){\stackrel{ˆ}{\mathrm{q}}}_{1})\\ {\mathrm{q}}_{1}={\delta}_{1}{\stackrel{ˆ}{\mathrm{q}}}_{1}{\mid {\stackrel{ˆ}{\mathrm{q}}}_{1}^{T}(\mathrm{A}-\sigma \mathrm{B}){\stackrel{ˆ}{\mathrm{q}}}_{1}\mid }^{-\frac{1}{2}}\\ {\mathrm{q}}_{0}=0,{\beta}_{0}=0,{d}_{0}=0.\end{array}\\ \text{Pour k=1,m faire}\\ \mathrm{z}={\mathrm{A}}_{\sigma}{\mathrm{q}}_{k}-{\delta}_{\text{k-1}}{\beta}_{\text{k-1}}{\mathrm{q}}_{\text{k-1}},\\ {\alpha}_{k}={\mathrm{q}}_{k}^{T}(\mathrm{A}-\sigma \mathrm{B})\mathrm{z},\\ \begin{array}{c}\mathrm{v}=\mathrm{z}-{\delta}_{k}{\alpha}_{k}{\mathrm{q}}_{k},\\ \text{Réothogonalisation de}\mathrm{v}\text{par rapport aux}{({\mathrm{q}}_{i})}_{i=1,k}(\text{IGSM}),\end{array}\\ \begin{array}{c}{\beta}_{k}={\mathrm{v}}^{\mathrm{T}}(\mathrm{A}-\sigma \mathrm{B})\mathrm{v},\\ {\delta}_{k}=\text{sign}({\mathrm{v}}^{\mathrm{T}}(\mathrm{A}-\sigma \mathrm{B})\mathrm{v}),\\ \text{Si}{\beta}_{k}\mathrm{\ne }0\text{alors}\end{array}\\ \begin{array}{c}{\mathrm{q}}_{\text{k+1}}=\frac{{\delta}_{k}\mathrm{v}}{{\mid {\beta}_{k}\mid }^{\frac{1}{2}}},\\ \text{Sinon}\\ \text{Déflation};\\ \text{Fin si}.\end{array}\\ \text{Fin}\text{boucle}.\end{array}\)
Algorithme 10. Méthode de Lanczos. Variante de Newman-Pipano.
Remarques:
La \(B\) -orthogonalité et à fortiori celle au sens euclidien ne peuvent plus être que le fruit de configurations particulières. Ceci ne modifie pas les propriétés d’orthogonalités des modes propres (cf. proposition 2).
Comme on l’a déjà signalé il existe toute une zoologie de couples «opérateur-produit scalaire», celui-ci n’étant qu’une possibilité parmi d’autres. Ainsi, les bibliothèques[Arp] classiques proposent de traiter les problèmes de flambement en «buckling mode» via le même «shift and invert» et le pseudo-produit scalaire introduit par \(A\) . Mais du fait de l’introduction quasi-systématique de Lagranges, cette matrice devient indéfinie voire singulière, ce qui perturbe grandement le processus. Les mêmes causes produisent les mêmes effets lorsque pour un calcul de dynamique, on utilise le \(B\) -produit scalaire.
La réorthogonalisation s’effectue grâce à une variante «maison» de la Méthode de Gram-Schmidt Itératif (IGSM) suivant le processus suivant:
Pour \(i=1,k\)
\(a={\mathrm{q}}_{k+1}^{T}(\mathrm{A}-\sigma \mathrm{B}){\mathrm{q}}_{i}\) ,
Si \(∣\langle {\mathrm{q}}_{k+1}^{T}(\mathrm{A}-\sigma \mathrm{B}){\mathrm{q}}_{i}\rangle ∣\ge \text{PREC\_ORTHO}\) alors
Pour \(j=1\) ,NMAX_ITER_ORTHO
\(\begin{array}{c}\mathrm{x}={\mathrm{q}}_{k+1}-({\mathrm{q}}_{k+1}^{T}(\mathrm{A}-\sigma \mathrm{B}){\mathrm{q}}_{i}){\mathrm{q}}_{i}\\ b={\mathrm{x}}^{\mathrm{T}}(\mathrm{A}-\sigma \mathrm{B}){\mathrm{q}}_{i}\end{array}\) ,
Si \((\mid b\mid \le \text{PREC\_ORTHO})\) alors
\({\mathrm{q}}_{k+1}=\mathrm{x}\) ,
\(i+1\Rightarrow i\) , exit;
Sinon
Si \(b\le a\) alors
\({\mathrm{q}}_{k+1}=\mathrm{x}\) ,
\(a=b\) ;
Sinon
Échec, émission d’un message d’alarme,
\(i+1\Rightarrow i\) , exit;
Fin si.
Fin si.
Fin boucle en \(j\) .
Fin si.
Fin boucle en \(i\) .
Algorithme 11. Procédure de réorthogonalisation de ‘TRI_DIAG’.
Remarque:
Après quelques tests, il semble que cette variante spécifique au code soit moins efficace que l’IGSM de type Kahan-Parlett[Par80] choisi pour l’IRAM (cf. Annexe 2).
Paramétrage#
Pour pouvoir activer cette méthode, il faut initialiser le mot-clé METHODE à “TRI_DIAG”. D’autre part, la taille du sous-espace de projection est déterminée, soit par l’utilisateur, soit empiriquement à partir de la formule:
\(m=\min(\max(\mathrm{4p},p+7),{n}_{\mathrm{ddl}-\mathrm{actifs}})\)
où |
\(p\) |
est le nombre de valeurs propres à calculer, |
\({n}_{\mathrm{ddl}-\mathrm{actifs}}\) |
est le nombre de degrés de liberté actifs du système (cf. §:ref:3.2 <Ref487283059> ) |
L’utilisateur peut toujours imposer lui-même la dimension en l’indiquant avec le mot-clé DIM_SOUS_ESPACE du mot-clé facteur CALC_FREQ. On peut préférer à une valeur par défaut, un coefficient multiplicatif par rapport au nombre de fréquences contenues dans l’intervalle d’étude. Ce type de fonctionnalité concerne le mot-clé COEF_DIM_ESPACE.
Les paramètres de la réorthogonalisation totale, PREC_ORTHO et NMAX_ITER_ORTHO , le nombre maximal d’itérations QR,NMAX_ITER_QR, et le critère de déflation, PREC_LANCZOS, sont accessibles par l’utilisateur sous le mot-clé facteur CALC_FREQ. Lorsque ce phénomène de déflation se produit, un message spécifique précise son rang 1.
Avertissement sur la qualité des modes#
Rappelons que cette variante n’est pas itérative. A partir du nombre de fréquences souhaitées, on estime la dimension du sous-espace de calcul et on espère que les modes propres du problème standard projeté seront une bonne approximation de ceux du problème généralisé. On vérifie a posteriori la validité des résultats (cf. §3.5) mais on n’a aucun contrôle actif sur cette précision.
S’ils ne sont pas satisfaisants, on n’a comme seul recourt que d’effectuer un nouvel essai en augmentant la dimension du sous-espace.
Remarque:
La méthode IRA que nous allons aborder propose un contrôle modulable et dynamique de la précision des résultats, c’est une méthode itérative.
Détection de modes rigides#
Une méthode algébrique calculant les valeurs propres nulles du problème modal généralisé a été introduite. Physiquement celles-ci correspondent aux mouvements à énergie de déformation nulle d’une structure libre (cf. [BQ00] TP n°2). Hormis les difficultés numériques de manipulation de quantités quasi-nulles, du fait de leurs multiplicités, leur capture correcte était jusqu’à présent souvent problématique pour le Lanczos implanté dans Code_Aster : des modes fantômes apparaissaient correspondant à des multiplicités ratées!
Cet algorithme de détection des modes de corps rigide, que l’on active en initialisant OPTION à ‘MODE_RIGIDE’ (valeur par défaut ‘SANS‘), intervient en pré-traitement du calcul modal proprement dit (uniquement avec ‘TRI_DIAG’). Elle est basée sur l’analyse de la matrice de rigidité et se décompose en trois phases:
Détection des pivots nuls de cette matrice.
Blocage de ces pivots.
Résolution d’un système linéaire dont sont solutions les vecteurs propres associés.
Lors du processus de Lanczos il suffit dès lors d’orthogonaliser, au fur et à mesure de leur détermination, les vecteurs de base avec ces derniers.
Cependant, l’introduction de la méthode IRA réduit l’intérêt (si ce n’est à titre de comparaison) d’une telle option (qui n’est pas gratuite en complexité calcul puisqu’elle requiert des inversions de systèmes). A quoi bon se priver d’un tel algorithme qui n’est nullement affecté par la présence de ces modes multiples un peu particuliers!
Cette méthode reste néanmoins utile à titre de solution de secours en cas de défaillance d’IRAM. On peut aussi envisager de l’encapsuler dans un opérateur auxiliaire (comme INFO_MODE).
Remarque:
Cette option ‘MODE_RIGIDE’ n’est activable qu’avec Lanczos pour des GEP à modes réels.
Périmètre d’utilisation#
GEP à matrices symétriques réelles .
L’utilisateur peut spécifier la classe d’appartenance de son calcul (dynamique ou flambement) en initialisant le mot-clé TYPE_RESU. Suivant cette valeur, on renseigne le vecteur FREQ ou CHAR_CRIT.
Affichage dans le fichier message#
L’exemple ci-dessous issu de la liste de cas tests du code (sdll112a) récapitule l’ensemble des traces gérées par l’algorithme. Le nombre d’itérations QR effectives (ou QL) ne peut être qu’identique pour toutes les valeurs propres. C’est un artefact d’information qui sera amené à disparaître.
LE NOMBRE DE DDL
TOTAL EST: 86
DE LAGRANGE EST: 20
LE NOMBRE DE DDL ACTIFS EST: 56
L’OPTION CHOISIE EST: PLUS_PETITE
LA VALEUR DE DECALAGE EN FREQUENCE EST : 0.00000E+00
INFORMATIONS SUR LE CALCUL DEMANDE :
NOMBRE DE MODES DEMANDES : 10
LA DIMENSION DE L’ESPACE REDUIT EST : 0
ELLE EST INFERIEURE AU NOMBRE DE MODES, ON LA PREND EGALE A 40
LES FREQUENCES CALCULEES INF. ET SUP. SONT:
FREQ_INF : 1.54569E+01
FREQ_SUP : 1.01614E+02
LA PREMIERE FREQUENCE SUPERIEURE NON RETENUE EST: 1.29375E+02
CALCUL MODAL: METHODE D’ITERATION SIMULTANEE
METHODE DE LANCZOS
NUMERO FREQUENCE (HZ) NORME D’ERREUR ITER_QR
1 1.54569E+01 1.29798E-12 4
2 1.54569E+01 7.15318E-13 4
3 3.35823E+01 3.98618E-13 4
4 3.35823E+01 4.25490E-12 4
…
10 1.01614E+02 3.18663E-12 4
VERIFICATION A POSTERIORI DES MODES
DANS L’INTERVALLE ( 1.54182E+01, 1.16326E+02)
IL Y A BIEN 10 FREQUENCE(S)
Exemple 5. Trace de CALC_MODES avec OPTIONparmi [“BANDE”,”CENTRE”,”PLUS_*”] dans le fichier messageavec SOLVEUR_MODAL=_F(METHODE=‘TRI_DIAG’).
Récapitulatif du paramétrage#
Récapitulons maintenant le paramétrage disponible de l’opérateur CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”] avec cet algorithme.
Opérande |
Mot-clé |
Valeur par défaut |
Références |
TYPE_RESU =”DYNAMIQUE” |
“DYNAMIQUE” |
§3.1 |
|
“MODE_FLAMB” |
§3.1 |
||
OPTION =‘PLUS_*’ |
‘PLUS_PETITE’ |
§5.4 |
|
‘BANDE’ |
§5.4 |
||
‘CENTRE’ |
§5.4 |
||
SOLVEUR_MODAL |
METHODE = ‘TRI_DIAG’ |
‘SORENSEN’ |
§6.5 |
MODE_RIGIDE=”NON” |
‘NON’ |
§6.5 |
|
‘OUI’ |
§6.5 |
||
PREC_ORTHO |
1.E-12 |
§6.5 |
|
NMAX_ITER_ORTHO |
1.E-04 |
§6.5 |
|
PREC_LANCZOS |
1.E-04 |
§6.5 |
|
NMAX_ITER_QR |
15 |
§6.5 |
|
DIM_SOUS_ESPACE COEF_DIM_ESPACE |
Calculé |
§6.5 |
|
CALC_FREQ |
FREQ ou CHAR_CRIT (si “CENTRE” ) |
§5.4 |
|
§5.4 |
|||
NMAX_FREQ ou NMAX_CHAR_CRIT (si “PLUS_*”) |
10 |
§5.4 |
|
NMAX_ITER_SHIFT |
3 |
[Boi12] §3.2 |
|
PREC_SHIFT |
0.05 |
[Boi12] §3.2 |
|
SEUIL_FREQ ou SEUIL_CHAR_CRIT |
1.E-02 |
§3.7 |
|
VERI_MODE |
STOP_ERREUR=”OUI” |
“OUI” |
§3.7 |
“NON” |
§3.7 |
||
PREC_SHIFT |
5.E-03 |
§3.7 |
|
SEUIL |
1.E-06 |
§3.7 |
|
STURM=‘OUI’ |
‘OUI’ |
§3.7 |
|
‘NON’ |
§3.7 |
Tableau 6.8-1. Récapitulatif du paramétrage de CALC_MODES avec OPTIONparmi [“BANDE”,”CENTRE”,”PLUS_*”] (GEP) avec SOLVEUR_MODAL=_F(METHODE=‘TRI_DIAG’).
Remarques:
On retrouve toute la « tripaille » de paramètres liée aux pré-traitements du test de Sturm (NMAX_ITER_SHIFT, PREC_SHIFT) et aux post-traitements de vérification (SEUIL_FREQ / SEUIL_CHAR_CRIT, VERI_MODE).
Lors des premiers passages, il est fortement conseillé de ne modifier que les paramètres principaux notés en gras. Les autres concernent plus les arcanes de l’algorithme et ils ont été initialisés empiriquement à des valeurs standards.
En particulier, pour améliorer la qualité d’un mode, le seul paramètre modulable est la dimension du sous-espace (DIM_SOUS_ESPACE/COEF_DIM_ESPACE).
Algorithme IRA(SOLVEUR_MODAL=_F( METHODE=‘SORENSEN’))#
Introduction#
Nous avons vu qu’un des problèmes cruciaux de la méthode de Lanczos est la perte d’orthogonalité inéluctable de ses vecteurs de base. Une généralisation de cet algorithme au cas nonhermitien imaginée par W.E.Arnoldi [Arn51] en 1951 permet de résoudre partiellement cette problématique. Elle a été remise au goût du jour par Y.Saad[Saa80] en 1980 et une abondante littérature couvre le sujet. Mis à part l’article fondateur et les papiers de Y.Saad et M.Sadkane[Sad93], on recommande la synthèse actualisée et exhaustive de J.L.Vaudescal[Vau00].
Cette méthode étant à la base de l’algorithme IRAM dit «deSorensen» (IRAM pour ‘Implicit Restarted Arnoldi Method’), nous allons tout d’abord détailler son fonctionnement, ses comportements et ses limitations. Par la suite, nous cernerons les enjeux auxquels doit répondre IRAM (et elle le fait dans la plupart des cas standards !) et nous nous pencherons sur ses arcanes théoriques et numériques. Nous conclurons par le récapitulatif de son paramétrage effectif dans Code_Aster et par un exemple de fichier message.
Algorithme d’Arnoldi#
Principe#
Son périmètre d’application recouvre tous les couples «opérateur de travail-(pseudo)produit scalaire» . Le pendant de cette ouverture est le remplissage de la matrice de Rayleigh qui devient de la forme Hessenberg supérieure . Ce n’est pas très préjudiciable, car on peut ainsi lui appliquer directement l’algorithme QR *.* La première étape d’un bon QR, hormis l’équilibrage, consiste justement à réduire la matrice de travail sous forme de Hessenberg. Cela permet de gagner un ordre de magnitude lors de la résolution proprement dite (cf. Annexe 1).
L’algorithme est très similaire à celui de Lanczos, il consiste à construire progressivement une famille de vecteur d’Arnoldi \({\mathrm{q}}_{1,}{\mathrm{q}}_{2,}\mathrm{...},{\mathrm{q}}_{m}\) en projetant orthogonalement, à l’itération \(k\) , le vecteur \({\mathrm{A}}_{\sigma}{\mathrm{q}}_{k}\) sur les \(k\) vecteurs précédent. Le nouveau vecteur devient \({\mathrm{q}}_{k+1}\) et ainsi, de proche en proche, on assure l’orthogonalité de cette famille de vecteurs.
A la différence de Lanczos, l’orthogonalité du nouveau vecteur par rapport à tous les précédents est donc assurée explicitement et non implicitement. Celle-ci est gérée par l’algorithme de Gram-Schmidt Modifié (GSM) (cf. annexe 2) qui s’avère suffisamment robuste dans la plupart des cas.
En notant, \({\mathrm{e}}_{m}\) le \(m\) ième vecteur de la base canonique, le vecteur résidu de la factorisation d’Arnoldi s’écrit \({\mathrm{R}}_{m}={b}_{m+1,m}{\mathrm{q}}_{m+1}{\mathrm{e}}_{m}^{T}\) .
B m
0
\({\mathrm{R}}_{m}={b}_{m+1,m}{\mathrm{q}}_{m+1}{\mathrm{e}}_{m}^{T}\) n
m
m

A s
**Qm*
=
n
Q m
m
Figure 7.2-1. Factorisation d’Arnoldi.
Le processus itératif se résume comme suit:
\(\begin{array}{c}\text{Calcul de}{\mathrm{q}}_{1}/\mathrm{\parallel }{\mathrm{q}}_{1}\mathrm{\parallel }=1.\\ \text{Pour}\text{k=}1,\text{m}\text{faire}\\ \mathrm{z}={\mathrm{A}}_{\sigma}{\mathrm{q}}_{k},\\ \begin{array}{c}\text{Pour}\text{l=}1,k\text{faire}(\text{GSM})\\ {b}_{lk}=(\mathrm{z},{\mathrm{q}}_{l}),\\ \mathrm{z}=\mathrm{z}-{b}_{lk}{\mathrm{q}}_{l},\end{array}\\ \text{Fin}\text{boucle;}\\ \begin{array}{c}{b}_{k+\text{1,k}}=\mathrm{\parallel }\mathrm{z}\mathrm{\parallel },\\ \text{Si}{b}_{k+\text{1,k}}\mathrm{\ne }0\text{alors}\end{array}\\ \begin{array}{c}{\mathrm{q}}_{\text{k+1}}=\frac{\mathrm{v}}{{b}_{k+\text{1,k}}},\\ \text{Sinon}\\ \text{Déflation};\\ \text{Fin si}.\end{array}\\ \text{Fin}\text{boucle}.\end{array}\)
Algorithme 13. Arnoldi théorique.
La matrice de Rayleigh s’écrit alors:
\({\mathrm{B}}_{m}=\left[\begin{array}{cccc}{b}_{11}& {b}_{12}& ...& {b}_{\mathrm{1m}}\\ {b}_{21}& {b}_{22}& ...& {b}_{\mathrm{2m}}\\ 0& ...& ...& {b}_{m-1,m}\\ 0& 0& {b}_{m,m-1}& {b}_{\text{mm}}\end{array}\right]\)
Hormis la forme de cette matrice et une moindre acuité aux problèmes d’orthogonalité, cet algorithme nous assure les mêmes propriétés théoriques et numériques que Lanczos . Cependant si on laisse croître indéfiniment la taille du sous-espace jusqu’à convergence des valeurs propres souhaitées, les effets d’arrondi vont malgré tout reprendre le dessus et on va au devant de gros ennuis. D’où la nécessité, comme pour Lanczos, de rendre ce processus itératif via des redémarrages.
Remarques:
Cette méthode peut être vue comme une variante implicite de l’algorithme de Lanczos avec réorthogonalisation totale.
L’orthogonalisation implicite de l’algorithme peut être conduite par des algorithmes plus coûteux mais plus robustes tels que QR ou IGSM. Ceci est fortement requis lorsque l’opérateur de travail présente un trop fort défaut de normalité.
Du fait de la structure de \({\mathrm{B}}_{m}\) , la complexité mémoire est plus sollicitée qu’avec Lanczos, par contre la complexité calcul reste du même ordre de grandeur \(O(\mathrm{nm}(c+3+m))\) (avec \(c\) le nombre moyen de termes non nuls sur les lignes de la matrice de travail).
Pour améliorer ce premier point, Y.Saad[Saa80] a montré que la structure de Hessenberg supérieure peut voir s’annuler ses sur-diagonales extrêmes si on n’effectue que partiellement la réorthogonalisation.
Les algorithmes vectoriels ayant une tendance naturelle à rater des multiplicités, on préfère souvent utiliser une version blocs (M.Sadkane 1993). Mais la taille de ceux-ci influent sur la qualité des résultats, c’est pour cette raison qu’on leur préfère les versions vectorielles ou blocs d’IRAM.
Le choix du vecteur d’Arnoldi initial s’effectue de la même manière que pour Lanczos.
Estimations d’erreurs et de convergence#
En ce qui concerne l’évaluation de la qualité d’approximation des modes propres obtenus, on a un critère aussi simple et efficace que pour Lanczos.
Propriété 5
La norme euclidienne du résidu de l’élément de Ritz \((\tilde{\lambda},\tilde{\mathrm{u}}={\mathrm{Q}}_{m}\mathrm{x})\) est égale à
:math:`{mathrm{parallel }mathrm{r}mathrm{parallel }}_{2}={mathrm{parallel }({mathrm{A}}_{sigma}-tilde{lambda}mathrm{I})tilde{mathrm{u}}mathrm{parallel }}_{2}=mid {b}_{m+1,m}mid mid {mathrm{e}}_{m}^{T}mathrm{x}mid `
Preuve:
Triviale en prenant la norme euclidienne de la factorisation d’Arnoldi \({\mathrm{A}}_{\sigma}{\mathrm{Q}}_{m}\mathrm{x}={\mathrm{Q}}_{m}{\mathrm{B}}_{m}{\mathrm{x}+b}_{m+1,m}{\mathrm{q}}_{m+1}{\mathrm{e}}_{m}^{T}\mathrm{x}\) et comme \({\mathrm{q}}_{m+1}\) est normé à l’unité.
Toujours en nous focalisant sur la norme du projecteur supplémentaire \({\mathrm{\parallel }(\mathrm{I}-{\mathrm{P}}_{m})\mathrm{u}\mathrm{\parallel }}_{2}\) on peut généraliser le théorème de convergence 3 au cas non hermitien.
Théorème 6
Soit \(({\lambda}_{1},{\mathrm{u}}_{1})\) le premier (rangement classique, par ordre décroissant de module) mode propre dominant de \({\mathrm{A}}_{\sigma}\) diagonalisable et soit \({\mathrm{q}}_{1}=\sum_{k=1}^{n}{\alpha}_{k}{\mathrm{u}}_{k}\) le vecteur initial d’Arnoldi décomposé sur la base de vecteurs propres, il existe alors un mode de Ritz \(({\tilde{\lambda}}_{1},{\tilde{u}}_{1})\) tel que: \(\mid {\lambda}_{1}-{\tilde{\lambda}}_{1}\mid \le \frac{{\alpha}^{2}}{\beta}{\xi}_{1}{\delta}_{1}^{m}\)
avec \(\alpha =\frac{\beta}{{\mathrm{\parallel }{\mathrm{P}}_{m}{\mathrm{u}}_{i}\mathrm{\parallel }}_{2}}\) , \(\beta\) la constante du théorème 1, \({\xi}_{1}=\sum_{k=1,k\mathrm{\ne }1}^{n}\mid \frac{{\alpha}_{k}}{{\alpha}_{1}}\mid ` et :math:`{\delta}_{1}^{m}={(\sum_{j=2}^{m+1}\prod_{k=2,k\mathrm{\ne }j}^{m+1}∣\frac{{\lambda}_{k}-{\lambda}_{1}}{{\lambda}_{k}-{\lambda}_{j}}∣)}^{-1}\) . Ce résultat se décline de la même manière sur les autres modes.
Preuve:
En reprenant la démonstration de Y.Saad ([Saa91] pp209-210) et le résultat du théorème 1.
Ces majorations très différentes de celles obtenues avec Lanczos guident cependant les mêmes phénomènes:
Si le vecteur initial n’a aucune contribution le long des vecteurs propres recherchés, on ne peut les capturer (\({\xi}_{i}\to +\infty\) ).
On a prioritairement convergence des modes périphériques du spectre, et ce, d’autant mieux qu’il est séparé (propriété de \({\lambda}_{i}^{m}\) ).
La décroissance de l’erreur est proportionnelle à l’augmentation de \(m\) (propriété de \({\lambda}_{i}^{m}\) ).
Remarques:
Lorsqu’une valeur propre est mal conditionnée \({\xi}_{i}\to +\infty\) alors il faut augmenter \(m\) pour \({\lambda}_{i}^{m}\) que décroisse.
Des résultats analogues ont été vus dans le cas d’un opérateur défectif (cf.Zia 94).
Fort de ces enseignements, nous allons maintenant récapituler les enjeux auxquels doit répondre IRAM.
Les enjeux#
L’algorithme IRA tente d’apporter un remède élégant aux problèmes récurrents soulevés par les autres approches:
Minimisation de l’ espace de projection : il propose à minima \(m>p+1\) au lieu des \(m=4p\) de Lanczos.
Gestion optimale des surcoûts d’orthogonalisation établissant un compromis entre la taille du sous-espace et la fréquence des redémarrages .
Gestion transparente, dynamique et efficace de ces restarts.
Prise en compte automatique de l’information spectrale .
Fixation des pré-requis mémoire et de la qualité des résultats .
On a donc plus de question à se poser concernant la stratégie de réorthogonalisation, la fréquence des restarts, leurs implantations, les critères de détection d’éventuels modes fantômes… «super-IRAM» se charge de tout!
En bref, il procure:
Une meilleure robustesse globale.
Des complexités calculs \(O(\mathrm{4nm}(m-p))\) et mémoires \(O(\mathrm{2np}+{p}^{2})\) améliorées (surtout par rapport à un Lanczos simple tel celui de Newmann & Pipano) pour une précision fixée .
Une capture plus rigoureuse des multiplicités, des clusters et des modes de corps rigides (donc moins de modes parasites !).
Remarques:
Sur ce dernier point, seule une version par blocs d’IRAM ou une version incorporant du «purge and lock» (techniques de capture et de filtrage, cf. D.Sorensen & R.B.Lehoucq, 1997) peuvent nous garantir une détection correcte du spectre d’un opérateur standard (i.e. pas trop mal conditionné).
Il semble, qu’en pratique dans Code_Aster , le rapport en complexité calcul entre IRAM et Lanczos/Bathe & Wilson soit à minima d’ordre 2 en faveur du premier. Avec des tailles de problèmes raisonnables (quelques dizaines de milliers de ddls et \(p=O(100)\) ) celui-ci peut monter jusqu’à 10 (sans l’encapsulation de CALC_MODES sur plusieurs sous-bandes de recherche). Dans certains cas semi‑industriels, il a permis de dérouler une recherche de spectre qui avait échoué avec Jacobi et qui était inabordable avec Lanczos (compte tenu des délais impartis).
Une classe d’algorithme dit de «Jacobi-Davidson» (cf. R.B.Morgan 1990) semble encore plus prometteuse pour traiter des cas pathogènes. Elle utilise un algorithme de type Lanczos qu’elle préconditionne via une méthode de Rayleigh.
Dans le paragraphe suivant nous allons expliciter le fonctionnement d’IRAM.
Algorithme ‘Implicit Restarted Arnoldi’ (IRA)#
Cet algorithme a été initié par D.C.Sorensen[Sor92] en 1992 et connaît un réel essor pour la résolution de grands systèmes modaux sur des super-calculateurs parallèles. Son cadre d’application est tout à fait général. Il traite aussi bien les problèmes réels que complexes, hermitiens ou non. Il se résume en une succession de factorisations d’Arnoldi dont les résultats pilotent automatiquement des redémarrages statiques et implicites, via des filtres polynomiaux modélisés par des QR implicites.
Tout d’abord il réalise une factorisation d’Arnoldi d’ordre \(m=p+q\) (en théorie \(q=2\) suffit, en pratique \(q=p\) est préférable. C’est d’ailleurs cette dernière valeur par défaut qui a été retenue (cf. §7.5) de la matrice de travail. Puis une fois ce pré-traitement effectué il itère un processus de filtragede la partie du spectreindésirable (numériquement et méthodologiquement, il est plus facile d’exclure que d’incorporer).
Il commence par déterminer le spectre de la matrice de Rayleigh ( via l’indétronable QR) et il en dissocie la partie non désirée (en se référant aux critères fixés par l’utilisateur) qu’il utilise ensuite comme shift pour mettre en place une série de \(q\) QR implicite avec shift simple (cf. Annexe 1). La factorisation s’écrit alors:
\({\mathrm{A}}_{\sigma}{\mathrm{Q}}_{m}^{+}={\mathrm{Q}}_{m}^{+}{\mathrm{B}}_{m}^{+}+{\mathrm{R}}_{m}\mathrm{Q}\)
où \({\mathrm{Q}}_{m}^{+}={\mathrm{Q}}_{m}\mathrm{Q}\) , \({\mathrm{B}}_{m}^{+}={\mathrm{Q}}^{T}{\mathrm{B}}_{m}\mathrm{Q}\) et \(\mathrm{Q}={\mathrm{Q}}_{1}{\mathrm{Q}}_{2}\mathrm{....}{\mathrm{Q}}_{q}\) la matrice unitaire associée aux QRs. Après avoir mis à jour les matrices, on les tronque jusqu’à l’ordre \(p\)
\({\mathrm{A}}_{\sigma}{\mathrm{Q}}_{p}^{+}={Q}_{p}^{+}{\mathrm{B}}_{p}^{+}+{\mathrm{R}}_{p}^{+}\)
et ainsi, au prix de \(q\) nouvelles itérations d’Arnoldi, on peut retrouver une factorisation d’Arnoldi d’ordre \(m\) qui soit viable. Toute la subtilité du processus repose sur ce dernier enchaînement. Notons:
\(\Phi ({\mathrm{A}}_{\sigma})=\prod_{i=1}^{q}({\mathrm{A}}_{\sigma}-{\tilde{\lambda}}_{p+i}\text{Id})\) ,
le polynôme matriciel d’ordre \(q\) engendré par l’opérateur de travail. En fait, les QRs implicites ont agit sur les \(p\) premières lignes de la matrice d’Arnoldi, de Rayleigh et du résidu, de manière à ce que la factorisation complémentaire d’ordre \(q\) produise le même effet qu’une factorisation d’ordre \(m\) initiée par le vecteur
\({\tilde{\mathrm{q}}}_{1}=\Phi ({\mathrm{A}}_{\sigma}){\mathrm{q}}_{1}\) .
Le vecteur initial a été implicitement modifié (il n’y a pas construction et application effective du polynôme) afin qu’il engendre préférentiellement les modes souhaités et ce, en soustrayant les composantes jugées «impropres». Comme on l’a déjà fait remarquer ce type de restart permet de diminuer le résidu en amoindrissant les composantes du vecteur initial suivant les modes indésirables. En arithmétique exacte, on aurait immédiatement \({\mathrm{R}}_{m}=0\) et le processus s’arrêterait là!
Itération après itération, on améliore donc la qualité des modes recherchés en s’appuyant sur des modes auxiliaires . Bien sûr celle-ci est estimée à chaque étape et conditionne l’opportunité de simuler un autre restart ou pas. Le processus peut se résumer (très macroscopiquement !) comme suit:
\(\begin{array}{c}\text{Factorisation d'Arnoldi d'ordre}m:{\text{AQ}}_{m}={\mathrm{Q}}_{m}{\mathrm{B}}_{m}+{\mathrm{R}}_{m}.\\ \text{Pour k= 1, NMAX\_ITER\_SOREN faire}\\ \text{Calculer}\underset{\begin{array}{c}\text{Conservées pour}\\ \text{amélioration}\end{array}}{\underset{\underbrace{}}{\tilde{{\lambda}_{1}},\tilde{{\lambda}_{2}}...\tilde{{\lambda}_{p}}}},\underset{\begin{array}{c}\text{Utilisées comme}\\ \text{shifts}\end{array}}{\underset{\underbrace{}}{{\tilde{\lambda}}_{\text{p+1}}...{\tilde{\lambda}}_{\text{p+q}},}}\\ \text{QR avec shifts implicites,}\\ \text{Mise à jour}{\mathrm{Q}}_{m},{\mathrm{B}}_{m}\text{et}{\mathrm{R}}_{m},\\ \text{Troncature}\text{de}\text{ces}\text{matrices}à\text{l'ordre}p,\\ \begin{array}{c}{\text{AQ}}_{p}={\mathrm{Q}}_{p}{\mathrm{B}}_{p}+{\mathrm{R}}_{p}\mathrm{\Rightarrow }{\text{AQ}}_{m}={\mathrm{Q}}_{m}{\mathrm{B}}_{m}+{\mathrm{R}}_{m},\\ \text{Estimation qualité des}p\text{modes}.\end{array}\\ \text{Fin boucle}.\end{array}\)
Algorithme 14. Méthode IRA (dite de Sorensen).
Le nombre maximum d’itérations est piloté par le mot-clé NMAX_ITER_SOREN du mot-clé facteur CALC_FREQ. Il faut remarquer que l’algorithme Arnoldi est prudemment complété par une réorthogonalisation totale (déclenchée que si cela s’avère nécessaire). Ce surcoût est d’autant plus acceptable qu’elle est implantée via l’algorithme IGSM de Kahan-Parlett (cf. Annexe 2) qui est particulièrement efficace. Tout ceci permet de nous assurer de la bonne tenue de la projection vis-à-vis du spectre initial.
D’autre part, l’évaluation de la qualité des modes ne s’effectue pas simplement en construisant les \(p\) résidus \({\mathrm{\parallel }{\mathrm{r}}_{i}\mathrm{\parallel }}_{2}={\mathrm{\parallel }({\mathrm{A}}_{\sigma}-\tilde{\lambda}\mathrm{I}){\tilde{\mathrm{u}}}_{i}\mathrm{\parallel }}_{2}\) via la propriété 10. On a déjà mentionné que dans le cas non hermitien, ils ne sauraient suffire à cette tâche, notamment en cas de fort défaut de normalité. Pour s’en acquitter, sans avoir recours à d’autres informations [23]_ a priori , on utilise la propriété précédente complétée par un critère dû à Z.Bai et al[BDK93]
\(\mid {b}_{m+1,m}\mid \mid {\mathrm{e}}_{m}^{T}\mathrm{x}\mid <\max(\varepsilon \mathrm{\parallel }{\mathrm{B}}_{m}\mathrm{\parallel },\text{PREC\_SOREN}\mid \tilde{\lambda}\mid )\)
où \(\varepsilon\) est la précision machine et PREC_SOREN est un mot-clé initialisé sous CALC_FREQ. L’utilisateur a donc un contrôle (partiel) de la qualité des modes, ce dont il ne disposait pas avec les autres méthodes implantées dans le code. Compte tenu des différentes normes utilisées, cette erreur est différente de celle résultant du post-traitement global (cf. §3.6) qui est affichée dans les colonnes résultats.
Remarques:
La technique d’accélération polynomiale utilisée est plus efficace que celle de Tchebychev, puisque cette dernière est explicite et requiert m produits matrice-vecteur.
Pour éviter la détérioration des vecteurs de Ritz (et donc des vecteurs propres approchés) par des valeurs propres de très grands modules (associées au noyau de \(\mathrm{B}\) en «shift and invert») un filtrage de type Ericsson & Ruhe[ER80] a été implanté. Des techniques plus robustes existent mais elles nécessitent des informations a priori concernant notamment les blocs de Jordan associés au noyau de l’opérateur (cf. Meerbergen & Spence, 1996).
Cet algorithme peut être vu comme une forme tronquée de l’algorithme QR implicite de J.C.F.Francis (cf. Annexe 1).
Le paragraphe suivant va expliciter les choix qui ont conduit à la variante mise en place dans le code.
Implantation dans Code_Aster#
ARPACK#
Le package ARPACK( ARPACK pour ARnoldi PACKage) implémente la méthode IRA. C’est un produit public téléchargeable sur internet[Arp]. Ces concepteurs, D.Sorensen, R.Lehoucq et C.Yang de la Rice University de Houston, l’ont voulu à la fois:
Simple d’accès: interfaçage Fortran/C/C++ via le modèle de «reverse communication».
Modulable: basé sur les bibliothèques LINPACK, LAPACK et BLAS.
Riche en fonctionnalités numériques : décomposition de Schur, shifts modulables, nombreuses transformations spectrales, critères d’arrêt paramétrables.
Couvrant large périmètre d’utilisation : simple/double précision, réel/complexe, GEP à matrices symétriques/non symétriques…
Performant: pour gagner en temps CPU et en occupation mémoire, le package se décline en PARPACK version parallélisée via MPI et BLACS. D’autre part, même avec ARPACK séquentiel, les résolutions de systèmes linéaires requis par la méthode peuvent être effectuées par un solveur linéaire parallèle. La gestion mémoire des gros objets requis par ARPACK est laissée au soin du code hôte.
Figure 7.5-1. La page d’accueil du site web d’ARPACK[Arp].
Son efficacité est décuplée par l’utilisation de BLAS de niveau 2 et 3 très optimisées et par la mise en place de la « reverse communication ». L’utilisateur est donc maître de ses structures de données et de ses procédures de traitement concernant l’opérateur et le produit scalaire de travail. C’est lui qui fournit aux routines ARPACK ce type d’information. Cela permet donc de gérer au mieux, avec les outils et les procédures Code_Aster , les produits matrice-vecteur et les résolutions de système linéaire.
Pour l’instant, la gestion mémoire des gros objets requis par ARPACK est confiée à JEVEUX. Elle bénéficie donc de ses facultés «out-of-core [24]_ ». D’autre part, les opérateurs modaux d” Aster ayant accès aux mêmes solveur linéaires que ceux de statique, ils peuvent bénéficier eux aussi des avancées en temps et en mémoire que procure le parallélisme (SOLVEUR/METHODE=”MUMPS” ou “MULT-FRONT” cf. [U4.50.01][U2.08.06]). Mais, attention, ces gains sont limités à la partie solveur linéaire du calcul modal. Les speed-ups atteignables sont donc moins prometteurs puisque cette partie peut représenter, dans certains cas, que 50% du temps calcul [25]_ .
Le site d’ARPACK propose de la documentation (théorique et utilisation), des exemples d’utilisation et une page de téléchargement. La version finalisée d’ARPACK (v2.5 du 27/08/96) utilisée dans Code_Aster semble être la dernière. Malgré des milliers d’utilisation dans le monde (académique et industriel), un référencement avéré[HRTV07] et une reconnaissance certaine (cf. l’onglet «ARPACK applications» du site et les liens avec d’autres librairies telles PETSc et TRILINOS) ce projet de développement logiciel a été arrêté en 1997. Il a perduré quelques années de plus via la version C++ (ARPACK++) de D.Sorensen et F.Gomez.

Figure 7.5-2. Logo de la version C++ d’ARPACK.
Adaptations de l’algorithme de Sorensen#
Pour traiter des problèmes modaux généralisés, ce package propose toute une série de transformations spectrales, en réel ou en complexe, en hermitien ou non. En hermitien, l’algorithme de Sorensen est basé sur le couple Lanczos- QL (IRLM pour Implicit Restarted Lanczos Method). Les deux approches (hermitienne ou non) ne sont d’ailleurs pas prévues pour traiter des pseudo-produits scalaires liés à des matrices indéfinies.
Justement, pour à la fois circonscrire des problèmes numériques liés à leurs propriétés assez hétérogènes dans le code et, d’autre part, s’assurer d’une meilleure robustesse globale , nous avons choisi de travailler en non symétrique ( IRAM avec Arnoldi et QR) , sur le couple opérateur de travail-produitscalaire suivant:
\(\begin{array}{c}\underset{{\mathrm{A}}_{\sigma}}{\underset{\underbrace{}}{{(\mathrm{A}-\sigma \mathrm{B})}^{-1}\mathrm{B}}}\mathrm{u}=\underset{\lambda}{\underset{\underbrace{}}{\frac{1}{\mu -\sigma }}}\mathrm{u}\\ (\mathrm{x},\mathrm{y})={\mathrm{y}}^{\mathrm{T}}\mathrm{x}\end{array}\)
On aurait pu traiter les problèmes de flambement en «buckling mode» via le même «shift and invert» et le pseudo-produit scalaire introduit par \(A\) . Mais du fait de l’introduction quasi-systématique de Lagranges, cette matrice devient indéfinie voire singulière, ce qui perturbe grandement le processus. Les mêmes causes produisent les mêmes effets lorsque, pour un calcul de dynamique, on a recourt au \(B\) -produit scalaire. Plutôt que de modifier tout le package en introduisant un pseudo-produit scalaire, nous avons donc opté pour un simple produit scalaire «euclidien» plus robuste et beaucoup moins coûteux.
Il a donc fallu modifier les procédures de « reverse-communication » du package, car il ne prévoyait pas cette option (avec des matrices standards on préfère classiquement enrichir les composantes avec un produit scalaire matriciel, même en non symétrique). Contrairement à la variante de Newmann & Pipano introduite pour Lanczos, nous nous sommes délibérément placés dans une configuration non symétrique. Mais afin d’éviter autant que faire ce peut les problèmes d’orthogonalité récurrents, même en symétrique, nous aurions opté pour la version d’IRAM utilisant Arnoldi.
L’inconvénient de cette démarche est qu’il faut, en post-traitement préliminaire d’IRAM, \(B\) ‑orthonormaliser les vecteurs propres approchés pour retrouver numériquement la propriété 2 exploitées par les recombinaisons modales. Cette étape ne perturbe pas la base de modes propres exhumée et elle est très efficacement réalisée via l’IGSM de Kahan-Parlett.
La prise en compte des conditions limites et, en particulier des doubles dualisations, a été conduite comme pour Lanczos suivant le mode opératoire décrit en §3.2. En particulier, une fois que le vecteur initial se trouve dans l’espace admissible on lui applique l’opérateur de travail. Ce procédé classique permet de purger les vecteurs de Lanczos (et donc les vecteurs de Ritz) des composantes du noyau.
D’autre part, dans certaines configurations pour lesquelles le nombre de fréquences demandées \(p\) est égal au nombre de degrés de liberté actifs , on a dû bluffer l’algorithme qui s’arrêtait en erreur fatale! En effet, il détectait généralement bien l’espace invariant attendu (de taille \(p\) ), mais du fait de la structure particulière des vecteurs propres associés aux Lagranges (cf. preuve de la propriété 4, § 3.5 ) il avait beaucoup de mal à générer un vecteur initial qui leur soit proportionnel.
Il aurait fallu des traitements particuliers tenant compte de la numérotation de ces Lagranges, qui auraient été d’autant plus coûteux qu’ils ne sont pas foncièrement nécessaires pour résoudre le problème demandé! Toute l’information spectrale étant déjà présente au plus profond de l’algorithme, ce n’est donc pas la peine d’achever les deux itérations restantes (lorsque l’utilisateur demande \(p={n}_{\mathrm{ddl}-\mathrm{actifs}}\) , on impose automatiquement \(m=p+2\) ). Il suffit de court-circuiter le fil naturel de l’algorithme, de retirer les modes de Ritz intéressants et de les post-traiter pour revenir dans l’espace initial.
Remarque:
Ce type de cas de figure dans lequel on recherche un nombre de modes propres très proche du nombre de degrés de liberté sort du périmètre d’utilisation «idéal» de ce type d’algorithme. Un bon QR serait sans nul doute plus efficace, mais c’est un bon moyen de tester l’algorithme.
Paramétrage#
Pour pouvoir activer cette méthode, il faut initialiser le mot-clé METHODE à ‘ SORENSEN “ . La taille du sous-espace de projection est déterminée, soit par l’utilisateur, soit empiriquement à partir de la formule:
\(m=\min(\max(2p,p+2),{n}_{{\mathrm{ddl}}_{\mathrm{actifs}}})\)
où |
\(p\) |
est le nombre de valeurs propres à calculer, |
\({n}_{\mathrm{ddl}-\mathrm{actifs}}\) |
est le nombre de degrés de liberté actifs du système (cf. [§3.2]) |
L’utilisateur peut toujours imposer lui-même la dimension en l’indiquant avec le mot-clé DIM_SOUS_ESPACE du mot-clé facteur CALC_FREQ. On peut préférer à une valeur par défaut, un coefficient multiplicatif par rapport au nombre de fréquences contenues dans l’intervalle d’étude. Ce type de fonctionnalité concerne le mot-clé COEF_DIM_ESPACE.
Le paramètre de l’IGSM de Kahan-Parlett (cf. Annexe 2) PARA_ORTHO_SOREN , le nombre maximal d’itérations du processus global,NMAX_ITER_SOREN, et le critère de contrôle de qualité des modes, PREC_SOREN, sont accessibles par l’utilisateur sous le mot-clé facteur CALC_FREQ. Lorsque ce dernier mot-clé est nul, l’algorithme l’initialise à la précision machine.
Périmètre d’utilisation#
GEP à matrices réelles quelconques (symétriques ou non) ou à matrice \(A\) complexe et \(B\) réelle symétriques .
L’utilisateur peut spécifier la classe d’appartenance de son calcul (dynamique ou flambement si matrices réelles symétriques) en initialisant le mot-clé TYPE_RESU. Suivant cette valeur, on renseigne le vecteur FREQ ou CHAR_CRIT.
Affichage dans le fichier message#
L’exemple ci-dessous issu de la liste de cas tests du code (ssll103b) récapitule l’ensemble des traces gérées par l’algorithme. On retrouve notamment, pour chaque charge critique (ou fréquence), l’estimation de sa qualité via la norme d’erreur.
Ici, IRAM n’a itéré qu’une seule fois et a utilisé 30 IGSM (dans sa première phase). La résolution globale a consommé 91 produits (en fait, moins que cela du fait de l’introduction «implicite» du produit scalaire euclidien) matrice-vecteur et 31 inversions de système (juste la remontée car l’opérateur de travail est déjà factorisé).
LE NOMBRE DE DDL
TOTAL EST: 68
DE LAGRANGE EST: 14
LE NOMBRE DE DDL ACTIFS EST: 47
L’OPTION CHOISIE EST: PLUS_PETITE
LA VALEUR DE DECALAGE CHARGE CRITIQUE EST : 0.00000E+00
INFORMATIONS SUR LE CALCUL DEMANDE :
NOMBRE DE MODES DEMANDES : 10
LA DIMENSION DE L’ESPACE REDUIT EST : 30
= METHODE DE SORENSEN (CODE ARPACK) =
= VERSION : 2.4 =
= DATE : 07/31/96 =
NOMBRE DE REDEMARRAGES = 1
NOMBRE DE PRODUITS OP*X = 31
NOMBRE DE PRODUITS B*X = 91
NOMBRE DE REORTHOGONALISATIONS (ETAPE 1) = 30
NOMBRE DE REORTHOGONALISATIONS (ETAPE 2) = 0
NOMBRE DE REDEMARRAGES DU A UN V0 NUL = 0
LES CHARGES CRITIQUES CALCULEES INF. ET SUP. SONT:
CHARGE_CRITIQUE_INF : -9.96796E+06
CHARGE_CRITIQUE_SUP : -6.80007E+05
CALCUL MODAL: METHODE D’ITERATION SIMULTANEE
METHODE DE SORENSEN
NUMERO CHARGE CRITIQUE NORME D’ERREUR
1 -6.80007E+05 5.88791E-12
2 -7.04572E+05 1.53647E-12
3 -7.09004E+05 1.16735E-12
…
10 -9.96796E+06 3.55014E-12
VERIFICATION A POSTERIORI DES MODES
DANS L’INTERVALLE (-1.00178E+07,-6.76607E+05)
IL Y A BIEN 10 CHARGE(S) CRITIQUE(S)
Exemple 6. Trace de CALC_MODES avec OPTIONparmi [“BANDE”,”CENTRE”,”PLUS_*”] dans le fichier messageavec SOLVEUR_MODAL=_F(METHODE=‘SORENSEN’).
Remarque:
L’introduction de cette méthode a permis de solder de nombreuses fiches d’anomalies liées à des multiplicités, des clusters ou des recherches de valeurs propres d’ordres de grandeur très différents sur lesquels Lanczos et Bathe & Wilson achoppaient.
Récapitulatif du paramétrage#
Récapitulons maintenant le paramétrage disponible de l’opérateur CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”] avec cet algorithme.
Mot-clé facteur |
Mot-clé |
Valeur par défaut |
Références |
TYPE_RESU =”DYNAMIQUE” |
“DYNAMIQUE” |
§3.1 |
|
“MODE_FLAMB” |
§3.1 |
||
OPTION =‘PLUS_*’ |
‘PLUS_PETITE’” |
§5.4 |
|
‘BANDE’ |
§5.4 |
||
‘CENTRE’ |
§5.4 |
||
SOLVEUR_MODAL |
METHODE=‘SORENSEN’ |
‘SORENSEN’ |
§7.4 |
PREC_SOREN |
§7.4, §7.5 |
||
NMAX_ITER_SOREN |
20 |
§7.4, §7.5 |
|
PARA_ORTHO_SOREN |
0.717 |
§7.5, Annexe 2 |
|
DIM_SOUS_ESPACE COEF_DIM_ESPACE |
calculé |
§7.5 |
|
CALC_FREQ ou CALC_CHAR_CRIT |
FREQ ou CHAR_CRIT (si “CENTRE” ) |
§5.4 |
|
NMAX_FREQ ou NMAX_CHAR_CRIT (si “PLUS_*” ) |
10 |
§5.4 |
|
AMOR_REDUIT (si “CENTRE” et FREQ ) |
§5.4 |
||
NMAX_ITER_SHIFT |
3 |
[Boi12] §3.2 |
|
PREC_SHIFT |
0.05 |
[Boi12] §3.2 |
|
SEUIL_FREQ ou SEUIL_CHAR_CRIT |
1.E-02 |
§3.7 |
|
VERI_MODE |
STOP_ERREUR=”OUI” |
“OUI” |
§3.7 |
“NON” |
§3.7 |
||
PREC_SHIFT |
5.E-03 |
§3.7 |
|
SEUIL |
1.E-06 |
§3.7 |
|
STURM=‘OUI’ |
“OUI” |
§3.7 |
|
=‘NON’ |
§3.7 |
Tableau 7.8-1. Récapitulatif du paramètrage de CALC_MODES avec OPTIONparmi [“BANDE”,”CENTRE”,”PLUS_*”] (GEP)
avec SOLVEUR_MODAL=_F(METHODE=‘SORENSEN’).
Remarques:
On retrouve toute la « tripaille » de paramètres liée aux pré-traitements du test de Sturm (NMAX_ITER_SHIFT, PREC_SHIFT) et aux post-traitements de vérification (SEUIL_FREQ / SEUIL_CHAR_CRIT, VERI_MODE).
Lors des premiers passages, il est fortement conseillé de ne modifier que les paramètres principaux notés en gras. Les autres concernent plus les arcanes de l’algorithme et ils ont été initialisés empiriquement à des valeurs standards.
En particulier, pour améliorer la qualité d’un mode, le paramètre fondamental est la dimension du sous-espace (DIM_SOUS_ESPACE/COEF_DIM_ESPACE).
Méthode de Bathe et Wilson (SOLVEUR_MODAL= _F(METHODE=‘JACOBI’))#
Principe#
La méthode de Bathe et Wilson est une méthode d’itérations simultanées qui consiste à étendre l’algorithme des itérations inverses . On travaille à partir du problème décalé \({\mathrm{A}}^{\sigma}\mathrm{x}:=(\lambda -\sigma )\mathrm{B}\mathrm{x}\) avec \({\mathrm{A}}^{\sigma}:=\mathrm{A}-\sigma \mathrm{B}\) (cf. §5.4). On distingue quatre parties dans l’algorithme[Bat71]:
Choisir \(p\) vecteurs initiaux indépendants \({\mathrm{x}}_{1,}{\mathrm{x}}_{2,}\dots ,,{\mathrm{x}}_{p}\) et construire la matrice \(X\) qu’ils engendrent.
Calculer les éléments propres, via la méthode globale de Jacobi (cf. Annexe 3), dans le sous-espace de Ritz en résolvant
\((\stackrel{ˉ}{\mathrm{A}}-\stackrel{ˉ}{{\lambda}_{i}}\stackrel{ˉ}{\mathrm{B}}){\mathrm{u}}_{i}=0\) .où \(\stackrel{ˉ}{A}={Q}^{T}{A}^{\sigma}Q\) et \(\stackrel{ˉ}{B}={Q}^{T}BQ\)
On revient ensuite à l’espace initial (pour les vecteurs propres) via la transformation \(X=QU\) .où \(\mathrm{U}=[\lbrace {\mathrm{u}}_{i}\rbrace ]\)
Tester la convergence des modes propres \({\lambda}_{i}\) .
Tests de convergence#
La méthode de Bathe et Wilson converge vers les \(p\) plus petites valeurs propres à condition que les \(p\) vecteurs initiaux ne soient pas \(B\) -orthogonaux à l’un des vecteurs propres. Par ailleurs, les matrices \(\stackrel{ˉ}{A}\) et \(\stackrel{ˉ}{B}\) tendent vers des matrices diagonales. Pour cette raison et comme les matrices sont pleines, on utilise la méthode de Jacobi (cf. Annexe 3) pour trouver les éléments propres du sous-espace de Ritz.
Pour tester la convergence des valeurs propres, on les classe après chaque itération par ordre croissant en valeur absolue et on regarde si, pour chaque valeur propre, le test suivant est vérifié
\(\mid {\lambda}^{k+1}-{\lambda}^{k}\mid \le \text{PREC\_BATHE}\mid {\lambda}^{k+1}\mid\)
où l’exposant \(k\) indique le nombre d’itérations. Si après NMAX_ITER_BATHE itérations, on n’a pas convergé pour toutes les valeurs propres, un message d’alarme est émis dans le fichier message.
Implantation dans Code_Aster#
Dimension du sous-espace#
Si on désire calculer \(p\) valeurs propres, il est recommandé d’utiliser un sous espace de dimension \(q\) supérieure. On ne vérifiera la convergence que pour les \(r\) plus petites valeurs propres où \(p\le r\le q\) . Il semble que \(r=p\) ne soit pas suffisant: on peut trouver les bonnes valeurs propres mais les vecteurs propres ne sont pas corrects (la convergence est plus lente pour les vecteurs propres que pour les valeurs propres). \(r=(p+q)/2\) semble un bon choix. Pour \(q\) on prend habituellement[Bat71]
\(q=\min(p+8,2p)\)
Choix des vecteurs initiaux#
Pour choisir les \(q\) vecteurs initiaux, on opère de la façon suivante:
Premier vecteur tel que \({{x}_{1}}_{i}=\frac{{\mathrm{A}}_{ii}^{\sigma}}{{\mathrm{B}}_{ii}}\) ,
Pour les autres vecteurs de 2 à \((q-1)\)
\({x}_{2}=\left\lbrace \begin{array}{c}0\\ \\ 1\\ \\ 0\end{array}\right\rbrace --\text{ligne}{i}_{1}\text{}{x}_{q-1}=\left\lbrace \begin{array}{c}0\\ 1\\ 0\\ \\ 0\end{array}\right\rbrace \begin{array}{c}\\ --\text{ligne}{i}_{2}\\ \\ \end{array},...\)
où les \(i\) sont les indices correspondant aux plus petites valeurs successives de \(\frac{{\mathrm{A}}_{ii}^{\sigma}}{{\mathrm{B}}_{ii}}\) ,
Dernier vecteur \({\mathrm{x}}_{q}\) , vecteur aléatoire.
Périmètre d’utilisation#
GEP à matrices réelles symétriques .
L’utilisateur peut spécifier la classe d’appartenance de son calcul en initialisant le mot-clé TYPE_RESU. Suivant cette valeur, on renseigne le vecteur FREQ ou CHAR_CRIT.
Récapitulatif du paramétrage#
Récapitulons maintenant le paramétrage disponible de l’opérateur CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”] avec cet algorithme. Pour pouvoir utiliser la méthode de Bathe et Wilson, il faut choisir sélectionner METHODE=”JACOBI” sous le mot-clé facteur SOLVEUR_MODAL. Les deux paramètres concernant directement la convergence de la méthode sont accessibles sous ce même mot-clé facteur à l’aide des mots-clés PREC_BATHE et NMAX_ITER_BATHE. On y trouve aussi ceux gérant la méthode interne de résolution modale, PREC_JACOBI et NMAX_ITER_JACOBI.
Mot-clé facteur |
Mot-clé |
Valeur par défaut |
Références |
TYPE_RESU=”DYNAMIQUE” |
“DYNAMIQUE” |
§3.1 |
|
“MODE_FLAMB” |
|||
OPTION =‘PLUS_*’ |
‘PLUS_PETITE’” |
§5.4 |
|
‘BANDE’ |
|||
‘CENTRE’ |
|||
SOLVEUR_MODAL |
METHODE= ‘JACOBI’ |
‘SORENSEN’ |
Annexe 3 |
PREC_BATHE |
1.E-10 |
§8.2 |
|
NMAX_ITER_BATHE |
40 |
§8.2 |
|
PREC_JACOBI |
1.E-12 |
Annexe 3 |
|
NMAX_ITER_JACOBI |
12 |
Annexe 3 |
|
DIM_SOUS_ESPACE COEF_DIM_ESPACE |
Calculé |
§8.3 |
|
CALC_FREQ ou CALC_CHAR_CRIT |
FREQ ou CHAR_CRIT (si “CENTRE” ) |
§5.4 |
|
NMAX_FREQ |
10 |
§5.4 |
|
NMAX_ITER_SHIFT |
3 |
[Boi12] §3.2 |
|
PREC_SHIFT |
0.05 |
[Boi12] §3.2 |
|
SEUIL_FREQ ou SEUIL_CHAR_CRIT |
1.E-02 |
§3.7 |
|
VERI_MODE |
STOP_ERREUR=”OUI” |
“OUI” |
§3.7 |
=”NON” |
|||
PREC_SHIFT |
5.E-03 |
§3.7 |
|
SEUIL |
1.E-06 |
§3.7 |
|
STURM=‘OUI’ |
‘OUI’ |
§3.7 |
|
‘NON’ |
§3.7 |
Tableau 8.3-1. Récapitulatif du paramètrage de CALC_MODES avec OPTIONparmi [“BANDE”,”CENTRE”,”PLUS_*”] (GEP)avec SOLVEUR_MODAL=_F(METHODE=‘JACOBI’).
Remarques:
On retrouve toute la « tripaille » de paramètres liée aux pré-traitements du test de Sturm (NMAX_ITER_SHIFT, PREC_SHIFT) et aux post-traitements de vérification (SEUIL_FREQ / SEUIL_CHAR_CRIT, VERI_MODE).
Lors des premiers passages, il est fortement conseillé de ne modifier que les paramètres principaux notés en gras. Les autres concernent plus les arcanes de l’algorithme et ils ont été initialisés empiriquement à des valeurs standards.
Méthode globale QZ#
Ce solveur est sélectionné avec SOLVEUR_MODAL= _F(METHODE='QZ'))
Introduction#
La plupart des méthodes modales ont recours à une transformation spectrale de type «shift and invert» pour faciliter la recherche d’une partie du spectre et transformer le GEP initial en un SEP classique (Détermination du shift). Cette démarche est habile mais elle implique des factorisations numériques de matrices dynamiques du type \({{A}}_{\sigma}={({A}-\sigma {B})}^{-1} {B}\) (Factorisation de matrices dynamiques).
Le résultat de cette factorisation n’est qu’un intermédiaire de calcul maint fois utilisé dans l’algorithmique des solveurs modaux. Or ces factorisations sont forcément entachées d’erreurs numériques liées aux conditionnements des matrices et à l’erreur inverse (l’erreur inverse mesure la propension de l’algorithme à transmettre/amplifier les erreurs d’arrondi) du solveur direct (cf. [Généralités sur les solveurs linéaires directs et utilisation de MUMPS]). D’où l’idée, pour construire une méthode modale robuste, d’éviter ce type de mécanisme et de ne recourir qu’à:
Des transformations qui produisent/propagent peu d’erreurs d’arrondis (dites «backward stables») du type Householder ou Givens,
Des matrices canoniques faciles à manipuler (triangulaires, diagonales ou de Hessenberg) et/ou très bien conditionnées (orthogonales en réel ou unitaires en complexe).
Les GEP et la méthode QZ#
C’est le principe de la méthode QZ qui traite directement le GEP.
plutôt qu’un SEP issu de sa modification via une transformation spectrale. Cette méthode cherche en fait à construire la décomposition de Schur généralisée suivante (pendant de la décomposition de Schur standard).
Théorème 12 (Décomposition Généralisée de Schur)
Soient \(A\) et \(B\) deux matrices carrées complexes, alors il existe deux matrices carrées unitaires \(Q\) et \(Z\) telles que \({Q}^{\ast}AZ=T\) et \({Q}^{\ast}BZ=S\) soient des matrices triangulaires supérieures. Les valeurs propres du GEP eq:eq-r5.01.01-probGEP se calculent alors facilement grâce aux termes diagonaux (complexes) des matrices \(T\) et \(S\)
Pour la preuve, voir [GL89] pp. 396 et [MS73].
Ce théorème indique donc que, une fois la Décomposition Généralisée de Schur exhumée, résoudre le GEP (1710) revient à résoudre le GEP équivalent (et beaucoup plus simple car triangulaire)
Ils ont le même spectre, \(\lambda (A,B)=\lambda (T,S)\), et on passe des vecteurs propres de l’un à ceux de l’autre, via la transformation canonique
D’autre part, la manipulation de couples du type \(({\alpha}_{i},{\beta}_{i})=({T}_{ii},{S}_{ii})\), plutôt que de directement une valeur propre \({\lambda}_{i}:=\frac{{\alpha}_{i}}{{\beta}_{i}}\), est une astuce numérique permettant de mieux appréhender la complexité qu’induit la résolution directe d’un GEP. En effet, suivant par exemple le rang de la matrice \(B\), le spectre peut être:
fini: \(\lambda (A,B)=\left\lbrace {\lambda}_{1}\dots {\lambda}_{n}\right\rbrace\), avec éventuellement des valeurs propres de valeurs très grandes \(\pm \infty\),
vide: (\(\lambda (A,B)=\varnothing\)),
infini: (\(\lambda (A,B)=\setR \text{ ou } \setC\)).
Dans les deux premiers cas, le système est dit «régulier» par opposition à la dernière situation où il est dit «singulier». Pour s’en convaincre, les exemples ci-dessous illustrent les trois cas de figures:
La représentation des solutions en \((\alpha, \beta )\) permet alors de gérer plus proprement ces cas de figure. Par exemple, la valeur \(\beta \approx 0\) peut être interprétée comme une valeur propre infinie \(\lambda \approx \infty\) (probablement à ne pas retenir dans le spectre de travail!). Si de plus \(\alpha \approx 0\), on a une indétermination pour calculer la valeur propre correspondante et cela illustre un système singulier ou très mal conditionné.
Dans le cas des GEPs, ce cas de figure apparaît lorsqu’on traite les valeurs propres associées aux ddls bloqués et à ceux de Lagrange (Prise en compte des conditions limites). La décomposition \((\alpha, \beta )\) fournie alors un cadre pour filtrer ces artefacts numériques du spectre physique véritablement recherchés:
Remarques
La méthode QZ est «backward stable» pour résoudre un GEP standard. Mais elle perd cette propriété lorsqu’on l’utilise sur un GEP linéarisé, intermédiaire de calcul pour appréhender un QEP ([TM01]).
Dans le cas de matrices réelles, on a une décomposition similaire dite «Généralisée Réelle» avec des matrices carrées orthogonales \(Q\) et \(Z\) telles que \({Q}^{T}AZ=T\) soit quasi-triangulaire supérieure (.i.e. diagonale par blocs \(1\times 1\) ou \(2\times 2\) ) et \({Q}^{T}BZ=S\) soit triangulaire supérieure. La philosophie du calcul reste la même, en introduisant des couples \((\alpha, \beta )\) comme intermédiaires, avant le calcul proprement-dit des valeurs propres \(\lambda\). Une différence notable avec le cas complexe provient du fait que l’on peut, même en présence de modes complexes, continuer à travailler en arithmétique réelle. Cette stratégie exploitée par certaines routines de LAPACK a été utilisée avec la méthode QZ de [CALC_MODES] avec
OPTIONparmiBANDE,CENTRE,PLUS_*ouTOUT.
Dans certains cas (matrices SPD, structures bandes…), l’approche peut se décliner plus efficacement (c’est-à-dire avec un stockage creux, voire en mode parallèle). Par exemple, si le GEP est à matrices réelles symétriques avec \(B\) en plus définie positive (donc il existe une factorisation de Cholesky telle que \(B=LD{L}^{T}\) ), le GEP (1710) se résout directement via le SEP symétrique réel équivalent
Ce SEP canonique se résout alors de manière robuste et plus efficace via un QR adapté (cf. annexe 1). Cette stratégie exploitée par certaines routines de LAPACK a été utilisée avec la méthode QZ de [CALC_MODES] avec OPTION parmi BANDE, CENTRE, PLUS_* ou TOUT. Dans le mot-clé facteur SOLVEUR_MODAL, on prend TYPE_QZ=’QZ_QR’.
La méthode QZ#
Dans le cas général, l’algorithme de la méthode QZ peut se décomposer en trois étapes :
Via des transformations de Givens (cf. annexe 3) ou de Housholder 2x2, les deux matrices complexes \(A\) et \(B\) (resp. réelles) sont décomposées sous une forme dite «Généralisée Hessenberg Supérieure». C’est-à-dire qu’on détermine deux matrices carrées unitaires (resp. orthogonales) \({U}_{1}\) et \({V}_{1}\) telles que \(A={U}_{1}H{V}_{1}^{\ast}\) et \(B={U}_{1}R{V}_{1}^{\ast}\) (resp. \(A={U}_{1}H{V}_{1}^{T}\) et \(B={U}_{1}R{V}_{1}^{T}\) ) avec \(H\) de Hessenberg supérieure et \(R\) triangulaire supérieure. Par exemple, avec \(A:=\left[\begin{array}{ccc}10& 1& 2\\ 1& 2& -1\\ 1& 1& 2\end{array}\right]\text{ et }B:=\left[\begin{array}{ccc}1& 2& 3\\ 4& 5& 6\\ 7& 8& 9\end{array}\right]\), on trouve
En généralisant l’algorithme à double shifts implicites de Francis (à base de transformations de Householder, cf. annexe 1), on finalise la transformation. On exhume alors deux matrices carrées unitaires (resp. orthogonales) \({U}_{2}\) et \({V}_{2}\) telles que \(H={U}_{2}{TV}_{2}^{\ast}\) et \(R={U}_{2}S{V}_{2}^{\ast}\) (resp. \(H={U}_{2}T{V}_{2}^{T}\) et \(R={U}_{2}S{V}_{2}^{T}\) ) avec \(T\) et \(S\) triangulaires supérieures (resp. \(T\) quasi-triangulaire supérieure). En regroupant ces deux étapes, on établit le résultat recherché, comme le produit de transformations unitaires reste unitaire,
En utilisant les termes diagonaux des matrices triangulaires obtenues \(T\) et \(S\), on déduit (après filtrage et quelques tests de validité) les valeurs propres physiques du problème vibratoire modélisé. Les vecteurs de Schur généralisé à droite et à gauche (vecteurs colonne de \(Q\) et \(Z\) ) permettent de remonter aux vecteurs propres du GEP équivalent (1711) puis aux vecteurs propres d’origine (via la transformation (1712)).
Cette méthode QZ est préconisée lorsqu’on cherche à obtenir de manière robuste tout le spectre d’un GEP. Cependant, elle est très coûteuse en temps CPU \(\vartheta (30{n}^{3})\) contre \(\vartheta (nm(m-p))\) pour IRAM avec \(n\) la taille du problème, \(p\) le nombre de modes propres souhaités et \(m\) la taille de l’espace de projection. De plus, elle est très gourmande en capacité mémoire car elle requiert le stockage plein des matrices. D’où une complexité mémoire en \(\vartheta ({n}^{2})\) contre, par exemple, \(\vartheta (2 np+{p}^{2})\) pour IRAM. Bref, cet algorithme est à réserver aux petits GEP( inférieur à \({10}^{3}\) degrés de liberté), plutôt denses, dont on souhaite obtenir une estimation fiable du spectre. Comme pour l’algorithme QR dans Lanczos/IRAM ou pour Jacobi avec Bathe & Wilson, il est plutôt à exploiter comme brique élémentaire d’un processus algorithmique qui aura (considérablement) réduit la taille du problème initial.
Pour de plus amples informations sur la méthode, on pourra consulter G.H.Golub[GL89] ou le papier fondateur de C.B.Moler et G.W.Stewart[MS73] (1973)
Implantation#
LAPACK#
Des routines de l’excellente bibliothèque d’algèbre linéaire LAPACK [Lap] propose des routines dédiées (et des drivers les encapsulant) à la résolution de GEP directement via un QZ. Et ce, pour un large panel de problèmes: SPD, réel non symétrique, complexe hermitien ou quelconque, simple/double précision, stockage plein ou par bande. D’autre part, la librairie propose toute une panoplie de routines pour décomposer la résolution, pré et post-traiter les données manipulées voire estimer les erreurs numériques qui entachent les solutions. Elle reste cependant très liées au stockage plein des matrices, elle ne travaille qu’en In-Core et n’exploite aucun parallélisme.
D’autre part, il ne semble pas qu’il existe de package du domaine public implémentant plus efficacement que LAPACK une méthode de type QZ. C’est donc sur cette librairie que se base la méthode QZ disponible dans [CALC_MODES] avec OPTION parmi BANDE, CENTRE, PLUS_* ou TOUT. Notons que beaucoup d’autres produits ont fait le même choix de LAPACK et de son QZ : module eigenvalues de Python/linear algebra, fonctions eig et qz pour Matlab, spec pour Scilab, MSC/Nastran, …
Intégration et post-vérifications#
Dans l’implémentation qui a été retenue dans, les GEP à modes réels (matrices symétriques réelles) sont traités en arithmétique réelle via les routines DGGEV et DGGEVX. La première routine est à utiliser lors d’un run standard (TYPE_QZ=’QZ_SIMPLE’, valeur par défaut). La seconde (TYPE_QZ=’QZ_EQUI’), plus sophistiquée, est à réserver aux résolutions difficiles. En particulier, elle équilibre et permute les termes des matrices d’entrée afin d’améliorer les conditionnements spectraux et donc de diminuer l’erreur numérique sur les solutions. Parfois ce pré-traitement peut être préjudiciable en augmentant démesurément des termes proches de la précision machine, faussant ainsi les résultats. Pour cette raison, cette option n’est pas activée par défaut.
Dans le cas très particulier de GEP symétrique réel à matrice \(B\), en plus, définie positive (par exemple un calcul dynamique sans amortissement hystérétique avec des conditions limites de blocage modélisées uniquement par élimination sans le recours au double Lagrange), le recours au driver LAPACK DSYGV est plus efficace que les DGGEV/X. Il doit être activé explicitement via le mot-clé TYPE_QZ=’QZ_QR’. Pour certaines situations (flambement, double Lagrange, matrice complexe ou non symétrique, QEP linéarisé), la caractère non SPD de \(B\) peut être détecté a priori. Une erreur fatale arrête alors le calcul si la valeur QZ_EQUI a été choisie malgré tout.
Dans le troisième et dernier cas de figure de GEP à modes complexes (matrices complexes symétriques comme dans le cas de l’amortissement hystérétique et/ou réelles non symétriques), la résolution est directement effectuée en arithmétique complexe via les drivers LAPACK ZGGEV et ZGGEVX. Comme en réel, le premier est le mode standard par défaut (activé par TYPE_QZ=’QZ_SIMPLE’) et le deuxième, le mode expert (TYPE_QZ=’QZ_EQUI’).
A l’issue du calcul modal, QZ renvoie des couples \(({\alpha}_{i},{\beta}_{i})\) et leur vecteur propre associé \({u}_{i}\), que l’on va trier et filtrer suivant les préconisations suivantes :
Vérifications mécaniques : Si \(\vert {\beta}_{i}\vert\) est proche de la précision machine, le mode n’est pas retenu (il correspond sans doute à un ddls bloqué ou à un Lagrange de blocage) et un message d’alarme est émis (si
INFO=2).
Une fois tous les tris effectués, on s’assure que le nombre de modes physiquement acceptables (cf. formule (9.1-6)) correspond bien au nombre de ddls_actifs \({n}_{\text{ddl}-\text{actifs}}\). Celui-ci est déterminé dans la phase d’initialisation et est indépendant du solveur modal (Prise en compte des conditions limites). Si le GEP est à modes réels, la non vérification de ce critère entraine une erreur fatale. Dans les autres cas, il est seulement signalé par un affichage dédié. Il n’est alors pas forcément synonyme de dysfonctionnements. Tout dépend du tri ultérieur des valeurs propres complexes conjuguées!
Vérifications numériques : Si \(\vert {\alpha}_{i}\vert \ge \Vert A \Vert\) ou \(\vert {\beta}_{i}\vert \ge \Vert B \Vert\), on ne retient pas le mode et un message d’alarme est émis.
Dans le cas d’un GEP symétrique réel (avec TYPE_QZ=’QZ_SIMPLE’ ou TYPE_QZ='QZ_EQUI’), on vérifie de plus que toutes les valeurs propres ont une partie imaginaire très petite (inférieure à la valeur \({f}_{\text{corrig}}\) renseignée par SEUIL_FREQ, valeur par défaut égale à \(10^{-2}\)). Dans le cas contraire, une alarme est émise.
Dans le cas d’un GEP symétrique définie positive réel traité via QZ_QR, on exclus les valeurs propres inférieures à \(-2{f}_{\text{corrig}}\) et supérieure à \(0.5 \times {10}^{308}\) (0.5*valeur maximale représentable en machine). Ces valeurs arbitraires résultent d’expériences numériques sur des cas-tests modaux de la base de vérification. Lorsqu’on trouve une valeur propre en dehors de cette bande, une alarme est émise si INFO=2.
Puis, une fois les modes issus de QZ filtrés, ceux-ci vont être triés et réordonnés suivant les desiderata de l’utilisateur:
CALC_FREQavecOPTION='BANDE’: option licite seulement avec un GEP à modes reels. On sélectionne les valeurs propres situées dans la bande fréquentielle souhaitée par l’utilisateur (mot-cléFREQouCHAR_CRIT).CALC_FREQavecOPTION=’PLUS_PETITE’: on retient la valeur propre la plus petite en module.CALC_FREQavecOPTION=’CENTRE’: on sélectionne les valeurs propres les plus proches en module du shift paramétré par le mot-cléFREQouCHAR_CRIT. On en retientNMAX_FREQ.CALC_FREQavecOPTION=’TOUTE’: on conserve toutes les valeurs propres licites issues des filtres précédents.
Pour finir, comme pour tous les solveurs modaux du code (cf. Factorisation de matrices dynamiques), les modes retenus vont subir deux dernières vérifications:
Test sur la norme du résidu du mode \((\lambda, u)\) .
Dans le cas standard d’un GEP à modes réels, test de Sturm de comptage de valeurs propres dans la bande fréquentielle ad hoc .
Périmètre d’utilisation#
Ce solveur est utilisable pour GEP à matrices réelles quelconques (symétriques ou non) ou à matrice \(A\) complexe et \(B\) réelle symétriques.
L’utilisateur peut spécifier la classe d’appartenance de son calcul (dynamique ou flambement) en initialisant le mot-clé TYPE_RESU. Suivant cette valeur, on renseigne le vecteur FREQ ou CHAR_CRIT.
Affichage dans le fichier message#
Dans le fichier message sont mentionnées les informations relatives à la méthode choisie (ici QZ), à sa variante (ici QZ_SIMPLE) et aux modes retenus. Dans le cas le plus courant d’un GEP à modes propres réels, on précise la liste des fréquences \({f}_{i}\) retenues (FREQUENCE) et leur norme d’erreur (NORME D’ERREUR).
OPTION parmi BANDE, CENTRE, PLUS_* ou TOUT dans le fichier message avec SOLVEUR_MODAL=_F(METHODE=’QZ’)#CALCUL MODAL: METHODE GLOBALE DE TYPE QR
**ALGORITHME QZ_SIMPLE**
NUMERO **FREQUENCE (HZ)** **NORME D'ERREUR**
1 1.67638E+02 2.47457E-11
2 1.67638E+02 1.48888E-11
3 1.05060E+03 2.00110E-12
4 1.05060E+03 1.55900E-12
Pour un GEP à modes complexes, contrairement aux QEP on ne filtre pas les valeurs propres conjuguées. Il les conserve toutes et les affiche par ordre croissant de partie réelle. Ainsi, les colonnes FREQUENCE et AMORTISSEMENT regroupent, respectivement, \({f}_{i}=\frac{{\lvert}{\lambda}_{i}{\rvert}}{2\pi}\) et \({\xi}_{i}=\frac{\text{Im}({\lambda}_{i})}{{ \lvert}{\lambda}_{i}{\rvert}}\) .
OPTION parmi BANDE, CENTRE, PLUS_* ou TOUT dans le fichier message avec SOLVEUR_MODAL=_F(METHODE=’QZ’)#CALCUL MODAL: METHODE GLOBALE DE TYPE QR
ALGORITHME **QZ_EQUI**
NUMERO **FREQUENCE (HZ)** **AMORTISSEMENT** **NORME D'ERREUR**
1 6.44568E+00 5.00000E-02 1.28280E-15
2 1.55613E+01 5.00000E-02 6.26512E-16
NORME D'ERREUR MOYENNE: 0.95466E-15
Récapitulatif du paramétrage#
Récapitulons maintenant le paramétrage disponible de l’opérateur [CALC_MODES] avec OPTION parmi BANDE, CENTRE, PLUS_* ou TOUT pour cet algorithme QZ.
Mot-clé facteur |
Mot-clé |
Valeur par défaut |
Références |
|---|---|---|---|
|
|
||
|
|
||
|
|
||
|
|||
|
|||
|
|||
|
|
|
|
|
|
||
|
|||
|
|||
|
|
||
|
\(10\) |
||
|
\(0.\) |
||
|
\(3\) |
||
|
\(0.05\) |
||
|
\(0.01\) |
||
|
|
|
|
|
\(0.005\) |
||
|
|
Remarques
On retrouve toute la « tripaille » de paramètres liée aux pré-traitements du test de Sturm (
NMAX_ITER_SHIFTetPREC_SHIFT) et aux post-traitements de vérification (SEUIL_FREQ,SEUIL_CHAR_CRITetVERI_MODE).Lors des premiers passages, il est fortement conseillé de ne modifier que les paramètres principaux notés en gras. Les autres concernent plus les arcanes de l’algorithme et ils ont été initialisés empiriquement à des valeurs standards.
L’algorithme QZ est censé fournir les valeurs «les plus fiables possibles» des modes recherchés. Toutefois, lorsqu’il calcule tout le spectre d’un problème de taille non négligeable (plus de 100 degrés de liberté), il peut fournir des valeurs «approchées». N’étant pas un algorithme avec redémarrage (cf. IRAM) ou avec une étape de projection (cf. Lanczos/IRAM), l’utilisateur ne dispose d’aucun «levier» numérique pour améliorer la convergence des modes. Tout au plus, peut il changer d’option de calcul (TYPE_QZ), en rajoutant ou en enlevant les pré-traitements d’équilibrage (cf. Implantation).
Parallélisme et calcul intensif#
Opérateurs intégrés#
Les opérateurs CALC_MODES et INFO_MODE peuvent bénéficier d’un premier niveau de parallélisme: celui intrinsèque du solveur linéaire MUMPS.
Cependant, l’efficacité parallèle de MUMPS dans un calcul modal est plus limitée que pour d’autres types d’analyses. On constate, en général, une efficacité parallèle en temps de l’ordre de 0.2 à 0.3 et ce, pour une faible gamme de processeurs: de 2 à 16. Au delà on ne gagne plus rien.
Cela s’explique notamment par:
la quasi-singularité de certaines matrices dynamiques de travail,
un ratio «nombre de descente-remontées/nombre de factorisations» très défavorable,
le coût important de la phase d’analyse par rapport à celui de la factorisation,
un ratio «coût en temps/mémoire du solveur linéaire»/«coût en temps/mémoire du solveur modal» très défavorable.
Pour plus d’informations techniques et fonctionnelles, on peut consulter les documentations [R6.02.03], [U4.50.01] et [U2.08.03/06].
Afin de progresser en terme de performances, on propose de décomposer le calcul initial en sous-calculs plus performants et plus précis: c’est l’objet d’une des fonctionnalités de l’opérateur CALC_MODES avec OPTION=”BANDE” et une liste de n>2 valeurs donnée sous CALC_FREQ=_F(FREQ), détaillée dans le paragraphe suivant. De plus, cette réécriture algorithmique du problème exhibe deux niveaux de parallélisme plus pertinents et plus efficaces pour «booster» les calculs modaux de Code_Aster .
Opérateur CALC_MODES, option “BANDE’découpée en sous-bandes#
Pour traiter efficacement de gros problèmes modaux (en taille de maillage et/ou en nombre de modes recherchés), on conseille l’usage de l’opérateur CALC_MODES avec l’option “BANDE” découpée en sous-bandes. Elle décompose le calcul modal d’un GEP standard (symétrique et réel), en une succession de sous-calculs indépendants, moins coûteux, plus robustes et plus précis.
Rien qu’en séquentiel, les gains peuvent être notables : facteurs 2 à 5 en temps, 2 ou 3 en pic RAM et 10 à 104 sur l’erreur moyenne des modes.
De plus, son parallélisme multi-niveaux, en réservant une soixantaine de processeurs, peut procurer des gains supplémentaires de l’ordre de 20 en temps et 2 en pic RAM (cf. tableaux 10-1). Et ce, sans perte de précision, ni restriction de périmètre et avec le même comportement numérique.
Cas-test perf016a (N=4M, 50 modes) découpage en 8 sous-bandes |
Temps elapsed |
Pic mémoire RAM |
1 processeur |
5524s |
16.9Go |
8 processeurs |
1002s |
19.5Go |
32 processeurs |
643s |
13.4Go |
découpage en 4 sous-bandes |
||
1 processeur |
3569s |
17.2Go |
4 processeurs |
1121s |
19.5Go |
16 processeurs |
663s |
12.9Go |
Etude sismique (N=0.7M, 450 modes) découpage en 20 sous-bandes |
Temps elapsed |
Pic mémoire RAM |
1 processeur |
5200s |
10.5Go |
20 processeurs |
407s |
12.1Go |
80 processeurs |
270s |
9.4Go |
découpage en 5 sous-bandes |
||
1 processeur |
4660s |
8.2Go |
5 processeurs |
1097s |
11.8Go |
20 processeurs |
925s |
9.5Go |
Figures-Tableaux 10-1a/b. Quelques résultats de tests de CALC_MODES parallèle avec les paramètres par défaut (+ SOLVEUR=”MUMPS’en IN_COREet RENUM=”QAMD”).
Code_Aster v11.3.11 sur la machine IVANOE (1 ou 2 processus MPI par noeud).
Le principe de CALC_MODES [U4.52.02] avec l’option “BANDE” découpée en sous-bandes, repose sur le fait que les coûts calculs et mémoires des algorithmes modaux dépendent plus que linéairement du nombre de modes recherchés. Donc, comme pour la décomposition de domaines |R6.01.03], on va décomposer la recherche de centaines de modes en paquets de taille plus raisonnables.
Un paquet de l’ordre de quarante modes semble un être un optimum empirique en séquentiel. En parallèle, on peut continuer à améliorer les performances en descendant jusqu’à la quinzaine.
L’exemple de la figure 10-2 illustre ainsi un calcul CALC_MODES global dans la bande
\([{\mathit{freq}}_{min},{\mathit{freq}}_{max}]\)
qui est souvent avantageusement remplacé par dix calculs CALC_MODES ciblés sur des sous-bandes contigües équivalentes
\([{\mathit{freq}}_{1}={\mathit{freq}}_{min},{\mathit{freq}}_{2}],[{\mathit{freq}}_{2,}{\mathit{freq}}_{3}],\mathrm{...}[{\mathit{freq}}_{10,}{\mathit{freq}}_{11}={\mathit{freq}}_{max}]\) .
D’autre part, ce type de décomposition permet de:
réduire les problèmes de robustesse,
améliorer et homogénéiser les erreurs modales.
En pratique, cet opérateur modal dédié au HPC est décomposé en quatre étapes principales:
Précalibration modale ( via INFO_MODE) des sous-bandes paramétrées par l’utilisateur:
Donc potentiellement, une boucle de nb_freq calculs indépendants sur chaque position modale de fréquences (cf. [R5.01.04]).
Calcul modal effectif ( via CALC_MODES + OPTION=”BANDE” + CALC_FREQ=_F(TABLE_FREQ)) des modes contenus dans chaque sous-bande non vide (en mutualisant les calibrations modales de l’étape n°1):
Donc potentiellement, une boucle de nb_sbande_nonvide < nb_freq calculs indépendants.
Post-vérification avec un test de Sturm sur les bornes extrêmes des modes calculées ( via INFO_MODE):
Donc potentiellement, une boucle de 2 calculs indépendants.
Post-traitements sur tous les modes obtenus: normalisation ( via NORM_MODE) et filtrage ( via EXTR_MODE).
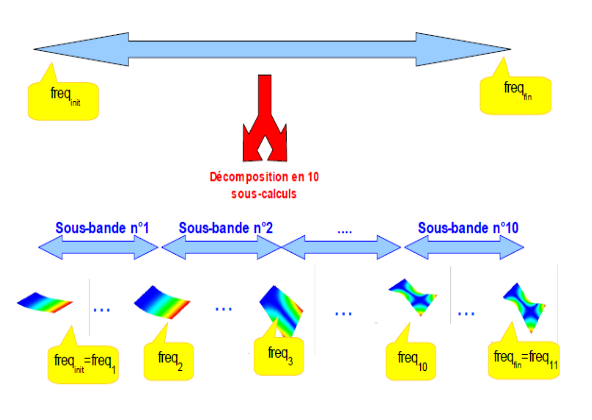
Figure 10-2. Principe de la décomposition des calculs de CALC_MODES avec l’option “BANDE’découpée en sous-bandes.
En parallèle, chacune des étapes de calcul peut dégager au moins un niveau de parallélisme:
Les deux premières en distribuant les calculs de chaque sous-bande sur le même nombre de paquets de processeurs.
La troisième, en distribuant les positions modales des bornes de l’intervalle de vérification sur deux paquets de processeurs.
La quatrième étape, peu coûteuse, reste séquentielle.
Si le nombre de processeurs et le paramétrage le permettent (notamment, si on utilise le solveur linéaire MUMPS), on peut exploiter un deuxième niveau de parallélisme.
La figure 10-3 illustre un calcul modal cherchant à tirer profit de 40 processeurs en décomposant le calcul initial en dix sous-bandes de recherche. Chacune bénéficie de l’appui de 4 occurrences MUMPS pour les inversions de systèmes linéaires intensivement requises par les solveurs modaux.
Pour une présentation exhaustive de ce parallélisme multi-niveaux, de ses enjeux et de quelques détails techniques et fonctionnels, on peut consulter les documentations [R5.01.04], [U4.52.01/02] et [U2.08.06].
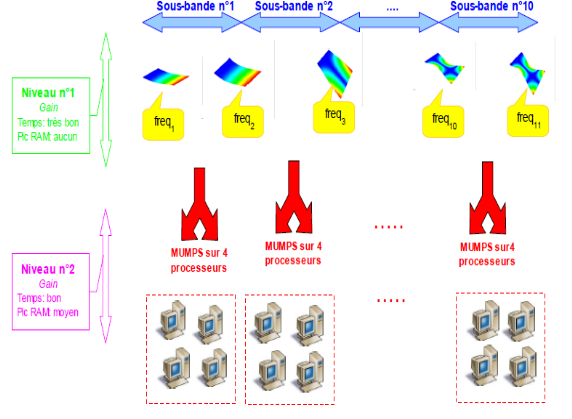
Figure 10-3. Exemple de deux niveaux de parallélisme dans l’INFO_MODE de pré-traitement
et dans la boucle des sous-bandes de CALC_MODES .
Distribution sur nb_proc=4 0 processeurs avec un découpage en 10 sous-bandes
(parallélisme dit «10x4»).
On utilise ici le solveur linéaire MUMPS et la paramétrage du parallélisme par défaut (“COMPLET”).
Remarques:
En parallélisme MPI, les principales étapes concernent la distribution des tâches et leurs communications. Pour CALC_MODES avec l’option “BANDE” découpée en sous-bandes, la distribution s’effectue dans le python de la macro ainsi que dans le fortran. Les deux communiquent par des mot-clés cachés: PARALLELISME_MACRO. Mais tous les appels MPI sont limités aux seules couches F77/F90.
Les communications globales du premier niveau, celles des valeurs et vecteurs propres, s’effectuent en fin du calcul modal sur chaque sous-bande. A un niveau intermédiaire, entre la simple communication de résultats d’algèbre linéaire (du type de ce qui est fait autour de MUMPS/PETSc) et la communication de structures de données Aster dans le python après filtrage (optimale en terme de performance mais beaucoup plus compliquée à mettre en oeuvre).
L’idéal aurait été de pouvoir équilibrer empiriquement les sous-bandes de fréquences pour limiter les déséquilibrages de charge liés à la répartition des modes par sous-bandes et ceux liés au calcul modal proprement dit. On aurait pu ainsi prévoir 2, 4 ou 8 calculs de sous-bandes par processeur. Cela permettrait aussi de bénéficier des gains de la décomposition de calcul de la macro, même sur peu de processeurs. Mallheureusement, des contingences informatiques de manipulation de concepts utilisateurs potentiellement vides n’ont pas permis de valider ce scénario plus ambitieux.
Bibliographie#
Livres/articles/proceedings/thèses…#
[AHLT05] P.Arbenz, U.L.Hetmaniuk, R.B.Lehoucq & R.S.Tuminaro. A comparison of eigensolvers for large-scale 3d modal analysis using AMG-Preconditioned Iterative Methods . Int. J. Numer. Meth. Engng, vol. 64, pp204-236 (2005).
[Arn51] W.E.Arnoldi. The principle of minimized iterations in the solution of the matrix eigenvalue problem . Quart. Appl. Math, vol 9, pp17-19 (1951).
[Bat71] K.J.Bathe Solution methods for large generalized eigenvalue problems in structural engineering. Ed. California university Berkeley (1971).
[Ber99] O.Bertrand. Procédures de dénombrement de valeurs propres . Thèse de l’université de Rennes 1 (1999).
[BDK93] Z.Bai, J.Demmel & A.M.Kenney. On computing condition numbers for the nonsymmetric eigenproblem . ACM transactions on mathematical software, vol 19, pp202-223 (1993).
[BP02] Bergamaschi & M.Putti. Numerical comparison of iterative eigensolvers for large symmetric positive definite matrices . Comput. Methods Appli. Mech. Engrg. 191 5233-5247 (2002).
[Cha88] F.Chatelin. Valeurs propres de matrices . Ed. Masson (1988).
[CW85] J.K.Cullum & R.A.Willoughby. Lanczos algorithms for large symetric eigenvalue computations . Vol 1 Theory, Ed Birkhäuser (1985).
[DMW71] A.Dubrulle, R.S.Martin & J.H.Wilkinson. The Implicit **QLAlgorithm* . Handbook for automatic computation. Vol 2, Linear algebra, Springer-Verlag (1971).
[ER80] T.Ericsson & A.Ruhe. The spectral transformation Lanczos method for the numerical solution of large sparse generalised symmetric eigenvalue problems . Mathematics of computations, vol 35, pp1251-1268 (1980).
[GL89] G.H.Golub & C.F.Van Loan. Matrix computations . The Johns Hopkins university press (1989).
[GSF92] G.Gambolati, F.Sartoretto & P.Florian. An orthogonal accelerated deflation technique for large symmetric eigenproblems . Comp. Meth. Appl. Mech. Engrg., 94 13-23 (1992).
[Hau80] Y.Haugazeau. Application du théorème de Sylsvester à la localisation des valeurs propres . RAIRO analyse numérique, vol. 14, 1, pp25-41 (1980).
[HRTV07] V.Hernandez, J.E.Roman, A.Tomas & V.Vidal. A survey of software for sparse eigenvalue problems . Rapport SLEPc disponible à http://www.grycap.upv.es/slepc.
[Imb91] J.F.Imbert. Analyse des structures par éléments finis . Ed. CEPADUES (1991).
[Kny91] A.V.Knyazev. Toward the optimal preconditioned eigensolver: locally optimal block preconditioned conjugate gradient method . SIAM J. Sci. Comput., 23 pp517-541 (2001).
[Lan50] C. Lanczos. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators . Journal. of research. of the national bureau of standards, vol 45, n°4 pp255-282 (1950).
[LS96] R.B.Lehoucq & J.A.Scott. An evaluation of software for computing eigenvalues of sparse nonsymmetric matrices . Rapport Argonne National Laboratory MCS-P547-1195.
[LT86] P.Lascaux & R.Theodor. Analyse numérique matricielle appliquée à l’Art de l’ingénieur . Masson (1986).
[MPW71] R.S.Martin, G.Peters & J.H.Wilkinson. The **QRAlgorithm for Real Hessenberg Matrices* . Handbook for automatic computation,. Vol. 2, Linear algebra, Springer-Verlag (1971).
[MS73] C.B.Moler & G.W.Stewart. An algorithm for GEP . SIAM J. Num. Anal., 10, 241-256 (1973).
[MS93] R.B.Morgan & D.S.Scott. Preconditionning the Lanczos algorithm for sparse symmetric eigenvalue problems . SIAM J. Sci. Comp, vol 14 (1993).
[NP77] M.Newmann & A.Pipano. Fast modal extraction in NASTRAN via FEER computer programs, NASTRAN, user manuel , NASA Langley Research Center pp485-506 (1977).
[Osb60] E.E.Osborne. On pre-conditioning of matrices . J.Assoc.Comput.Mach., vol 7, pp338‑345 (1960).
[Pai00] C.C.Paige. Accuracy and effectivness of the Lanczos algorithm for the symmetric eigenproblem . Linear algebra and its applications, vol 34 (1980).
[Par80] B.N.Parlett. The symetric eigenvalue problem . Prentice Hall (1980).
[PR71] B.N.Parlett & C.Reinsch. Balancing a matrix for calculation of eigenvalues and eigenvectors . Handbook for automatic computation. Vol. 2, Linear algebra, Springer-Verlag (1971).
[Saa80] Y.Saad. On the rates of convergences of the Lanczos and the Block-Lanczos methods . SIAM J. Numer. Anal., vol 17 N° 5 , pp687-706 (1980).
Y.Saad. Variation on Arnoldi’s method for computing eigenelements of large unsymetric matrices . Linear algebra and its applications, vol 34, pp269-2395 (1980).
[Saa91] Y.Saad. Numerical methods for large eigenvalue problems . Ed. Manchester university (1991).
[Sad93] M. Sadkane. A block Arnoldi-Tchebychev method for computing the leading ergenpairs of large sparse unsymmetric matrices . Numerische mathematik, vol 64, pp181-193 (1993).
[Sor92] D.C.Sorensen. Implicit applications of polynomial filters in a k-step Arnoldi method . SIAM J. Matrix Anal. Appl., vol 13, pp357-385 (1992).
[SV96] G.L.G.Sleijpen & H.Van der Vorst. A jacobi-Davidson method for linear eigenvalue problems . SIAM J. Matrix Anal. Appl., 17 pp401-425 (1996).
[TM01] F.Tisseur & K.Meerbergen. The quadratic eigenvalue problem . SIAM Review vol 43, n°2, pp235-286 (2001).
[Wat07] D.S.Watkins. The matrix eigenvalue problem . SIAM (2007).
[WR71] J.H.Wilkinson & C.Reinsch. Handbook for automatic computation , vol 2, Linear Algebra, Springer-Verlag (1971).
Rapports/compte-rendus EDF#
[Beg06] M.Begon. Implantation de solveurs modaux dans Code_Aster . Rapport de Master de l’INSTN (2006).
[BQ00] O.Boiteau & B.Quinnez. Méthode d’analyse spectrale dans Code_Aster . Fascicule du Cours de dynamique disponible sur le site internet https://www.code-aster.org ` <https://www.code-aster.org/>`_(2000).
[Boi08] O.Boiteau. Généralités sur les solveurs linéaires directs et utilisation du produit MUMPS . Documentation de Référence Code_Aster R6.02.03 (2008).
[Boi08b] O.Boiteau. Intégration d’un solveur modal de type QZ dans Code_Aster et Extension des solveurs QZ et Sorensen aux problèmes modaux non symétriques de Code_Aster . Comptes-rendu internes EDF R&D CR-I23/2008/030 et CR-I23/2008/044 (2008).
[Boi09] O.Boiteau. Résolution du problème modal quadratique (QEP) . Documentation de Référence Code_Aster R5.01.02 (2009).
[Boi09b] O.Boiteau. Généralités sur le gradient conjugué: GCPC Aster et utilisation du produit PETSc . Documentation de Référence Code_Aster R6.01.02 (2009).
[Boi12] O.Boiteau. Procédure de dénombrement de valeurs propres . Documentation de Référence Code_Aster R5.01.04 (2012).
[Boy07] E.Boyère. Opérateur DYNA_TRAN_MODAL . Documentation d’Utilisation Code_Aster U4.53.21 (2007).
[Pel01] J.Pellet. Dualisation des conditions limites . Documentation de Référence Code_Aster R3.03.01 (2001).
[Ros07] C.Rose. Méthode multifrontale . Documentation de Référence Code_Aster R6.02.02 (2007).
[Vau00] J.L.Vaudescal. Introduction aux méthodes de résolution de problèmes aux valeurs propres de grande taille . Note EDF R&D HI-72/00/01 (2000).
Ressources internet#
[Arp] Site web d’ARPACK: http://www.caam.rice.edu/software/ARPACK/ ` <http://www.caam.rice.edu/software/ARPACK/>`_.
[Lap] Site web de LAPACK: http://www.netlib.org/lapack/.
[MaMa] Site web de MatrixMarket: http://math.nist.gov/MatrixMarket/index.html ` <http://math.nist.gov/MatrixMarket/index.html>`_.
[Sca] Site web de Scalapack: http://www.netlib.org/scalapack/ ` <http://www.netlib.org/scalapack/>`_.
Annexe 1. Généralités sur l’algorithme QR#
Principe#
Les algorithmes de type QR ont été pressentis par H.Rutishauser(1958) et formalisés concurremment par J.C.Francis et V.N.Kublanovskaya(1961). Cette méthode fondamentale est souvent impliquée dans les autres approches mieux adaptées pour traiter les problèmes de grandes tailles (en particulier les méthodes de projection).
\(\begin{array}{c}\text{Pour}k=1,...\text{faire}\\ {\mathrm{H}}_{k}={\mathrm{Q}}_{k}{\mathrm{R}}_{k}(\text{factorisation}\text{QR}),\\ {\mathrm{H}}_{k+1}={\mathrm{R}}_{k}{\mathrm{Q}}_{k},\\ \text{Fin boucle}.\end{array}\)
Algorithme 1.1. QR théorique.
Le processus conduit itérativement vers une matrice \({\mathrm{H}}_{k}\) triangulaire supérieure (ou triangulaire par blocs) dont les termes diagonaux sont les valeurs propres de l’opérateur initial \(\mathrm{H}={\mathrm{H}}_{1}\) . La notation \(H\) n’est en fait pas innocente, car on a tout intérêt à préalablement transformer orthogonalement (de manière à ne modifier que la forme de l’opérateur shifté et non son spectre) l’opérateur de travail \(A\) sous forme de Hessenberg supérieur, soit en arithmétique réelle
\({\mathrm{H}}_{1}={\mathrm{Q}}_{{0}_{}}^{\mathrm{T}}{\text{AQ}}_{0}\)
Ceci peut s’effectuer via diverses transformations orthogonales (Householder, Givens, Gram‑Schmidt…) et leur coût (de l’ordre de \(O({\mathrm{10n}}^{3}/3)\) ) est négligeable comparé au gain qu’elles permettent de réaliser à chaque itération du processus global: \(O({n}^{2})\) (avec Householder ou Fast‑Givens) contre \(O({n}^{3})\) . Ce gain d’un ordre de magnitude peut même être amélioré lorsque l’opérateur est tridiagonal symétrique (c’est le cas de Lanczos avec un vrai produit scalaire): \(O(\mathrm{20n})\) .
La convergence vers une matrice triangulaire simple ne s’effectue que si toutes les valeurs propres sont de modules distincts et que si la matrice initiale n’est pas «pathologiquement» trop pauvre dans les directions propres. La convergence du \(i\) ème mode (rangés classiquement par ordre décroissant de module) s’effectue alors en:
\(\underset{\mathrm{j¹i}}{\max}\frac{\mid {\lambda}_{j}\mid }{\mid {\lambda}_{i}\mid }\)
ce qui peut s’avérer très lent si aucun processus complémentaire n’est mis en œuvre.
Remarques:
La détermination du spectre de la matrice de Rayleigh avec la variante de Newmann & Pipano est effectuée via unQR(ou un QLen symétrique) simple de ce type (avec au préalable une procédure d’équilibrage). Le seul paramètre accessible par l’utilisateur est le nombre maximum d’itérations admissibles NMAX_ITER_QR.
Pour IRAM, ce calcul est réalisé via une méthode QRavec double shift explicite alors que les filtres polynomiaux gérant les restarts utilisent un QRavec double shift implicite. Par prudence, aucun paramètre n’est accessible pour l’utilisateur dans Code_Aster!
Il ne faut pas confondre la méthode, l’algorithme QR,et un de ses outils conceptuels, la factorisation QR.
Cette classe d’algorithme est très utilisée pour déterminer le spectre complet d’un opérateur, car elle est très robuste (c’est la référence dans ce domaine). Cependant elle est très gourmande en place mémoire ce qui rend son utilisation rédhibitoire sur de grands systèmes.
Le périmètre d’application de l’algorithme QR est beaucoup plus général que celui de Jacobi (c’est le deuxième algorithme standard fournissant tout le spectre d’un opérateur pour peut que l’on soit prêt à le stocker entièrement) qui est limité aux matrices hermitiennes.
Pour accélérer la convergence de l’algorithme simple qui peut être très lente (en présence de clusters par exemple) une multitude de variantes, basées sur le choix de shifts répondant à certains critères, ont vu le jour.
La stratégie du shift#
Cette stratégie consiste à susciter artificiellement un phénomène de déflation (cf. §4.1, §6.4) au sein de la matrice de travail. Cela offre le triple avantage:
de pouvoir isoler une valeur propre réelle voire deux valeurs propres complexes conjuguées,
tout en réduisant la taille du problème à traiter,
et en accélérant la convergence .
Dans sa version avec simple shift explicite, la méthode se réécrit alors sous la forme suivante:
\(\begin{array}{c}\begin{array}{c}\text{Pour k}=1,...\text{faire}\\ \text{Choisir le shift}\mu ,\\ {\mathrm{S}}_{k}={\mathrm{H}}_{k}-\mu \mathrm{I},\end{array}\\ {\mathrm{S}}_{k}={\mathrm{Q}}_{k}{\mathrm{R}}_{k}(\text{factorisation}\text{QR}),\\ {\mathrm{H}}_{\text{k+}1}={\mathrm{R}}_{k}{\mathrm{Q}}_{k}+\mu \mathrm{I},\\ \text{Fin boucle}.\end{array}\)
Algorithme 1.2. QR avec simple shift explicite.
Remarque:
Ce processus se généralise intuitivement à plusieurs shifts. On construit alors, pour chaque itération globale \(k\) , autant de matrices auxiliaires \({\mathrm{S}}_{k}^{i}\) que de shift \({\mu}_{i}\) .
La convergence du processus est grandement améliorée dans le sens où les termes sous-diagonaux s’annulent asymptotiquement en
\(\underset{j\ne i}{\max}\frac{\mid {\lambda}_{j}-\mu \mid }{\mid {\lambda}_{i}-\mu \mid }\)
En théorie, si ce shift \(\mu\) est valeur propre du problème, alors la déflation est exacte. En pratique, les effets d’arrondi perturbent ce phénomène, c’est ce qu’on appelle la propriété d’instabilité directe de l’algorithme . La difficulté principale réside dans le choix du (ou des) shifts. D’autre part, on ne garde pas le même shift pour toutes les itérations. On doit en changer lorsqu’il est associé à une valeur propre convergée. En effet, il aura numériquement provoqué son éviction du spectre de travail en suscitant une déflation à l’itération précédente.
Depuis les années soixante toute une zoologie de shifts s’est développée . Tandis que la plus simple utilise le dernier terme diagonal \({\mathrm{H}}_{n,n}\) celle de J.H. Wilkinson [WR71] consiste à déterminer analytiquement la valeur propre \(\mu\) du bloc diagonal
\(\left[\begin{array}{cc}{\mathrm{H}}_{n-1,n-1}& {\mathrm{H}}_{n-1,n}\\ {\mathrm{H}}_{n,n-1}& {\mathrm{H}}_{n,n}\end{array}\right]\)
la plus proche de ce terme. Cette technique permet d’obtenir une convergence quadratique voire cubique (dans le cas symétrique) et elle s’avère particulièrement efficace pour capturer des modes doubles ou des valeurs propres distinctes de même module. Cependant cette stratégie peut se révéler inefficace en présence de modes propres complexes conjugués.
Le même auteur a alors proposé une variante incluant un double shift correspondant aux deux valeurs propres complexes \({\mu}_{1}\) et \({\mu}_{2}\) (déterminées préalablement) du bloc incriminé. Mais outre les difficultés numériques à réfréner l’apparition de composantes complexes envahissantes (qui en théorie n’ont pas lieu d’être), on a d’autre part beaucoup de mal à conserver le caractère de «Hessenberg supérieure» de la matrice de travail. Au mieux, cela ralentie la convergence de l’algorithme QR, au pire, cela fausse complètement son fonctionnement.
Afin de remédier à ces inconvénients numériques, J.C.Francis a mis au point une version avec double shift implicite . Elle est très bien explicitée dans [GL89](pp377-81) et on se contentera ici de la résumer.
Pour minimiser les effets d’arrondis, il faudrait constituer directement la matrice auxiliaire \({\mathrm{S}}_{k}\) résultant de l’application simultanée des deux shifts \({\mu}_{1}\) et \({\mu}_{2}\)
\({\mathrm{S}}_{k}={\mathrm{H}}_{k}^{2}-({\mu}_{1}+{\mu}_{2}){\mathrm{H}}_{k}+({\mu}_{1}{\mu}_{2})\mathrm{I}\)
avant de la factoriser sous forme QR et de construire le nouvel itéré \({\mathrm{H}}_{k+1}\)
\(\begin{array}{c}{\mathrm{S}}_{k}={\mathrm{Q}}_{k}{\mathrm{R}}_{k},\\ {\mathrm{H}}_{k+1}={\mathrm{Q}}_{k}^{T}{\mathrm{H}}_{k}{\mathrm{Q}}_{k}.\end{array}\)
Mais le seul coût de l’assemblage initial (de l’ordre de \(O({n}^{3})\) ) rend la tactique inopérante. Cette variante, basée sur le théorème \(Q\) -implicite, consiste à appliquer à la matrice de travail des transformations de Householder particulières permettant de retrouver une matrice de Hessenberg «essentiellement» égale à \({\mathrm{H}}_{k+1}\) , c’est à dire du type:
. \({\tilde{\mathrm{H}}}_{k+1}={\mathrm{E}}^{-1}{\mathrm{H}}_{k+1}\mathrm{E}\text{avec}\mathrm{E}\text{=diag}(\pm 1,...\pm 1)\)
La matrice de travail conserve ainsi, au moindre coût , sa structure particulière et son spectre .
Toutes ces variantes sont en fait très sensibles aux techniques d’équilibrage implantées pour préconditionner l’opérateur initial. Le paragraphe suivant va résumer cette technique de «mise à l’échelle» («balancing» pour les Anglo-saxons) des termes de la matrice de travail qui est très employée en calcul modal.
Équilibrage#
Il s’agit d’atténuer les effets d’arrondi en bridant le périmètre d’expansion des termes de l’opérateurde travail , c’est à dire d’éviter qu’ils ne deviennent trop petits ou, au contraire, trop grands. À ce sujet, E.E.Osborne [Osb60] (1960) a remarqué que généralement l’erreur sur le calcul des éléments propres de \(A\) est de l’ordre de \(\varepsilon {\parallel A\parallel }_{2}\) où \(\varepsilon\) est la précision machine. Il proposa alors de transformer la matrice initiale en une matrice
\(\tilde{\mathrm{A}}={\mathrm{D}}^{\text{-1}}\mathrm{A}\mathrm{D}\) (avec \(D\) une matrice diagonale),
telle que:
\({\mathrm{\parallel }\tilde{\mathrm{A}}\mathrm{\parallel }}_{2}\ll {\mathrm{\parallel }\mathrm{A}\mathrm{\parallel }}_{2}\)
En fait on calcule itérativement une succession de matrices
\({\mathrm{A}}_{k}={\mathrm{D}}_{k-1}^{\text{-1}}{\mathrm{A}}_{k-1}{\mathrm{D}}_{k-1}\)
telles que:
\({\mathrm{A}}_{k}\underset{k\to \infty }{\to }{\mathrm{A}}_{f}\)
vérifiant \({\mathrm{\parallel }{\mathrm{a}}^{i}\mathrm{\parallel }}_{2}={\mathrm{\parallel }{\mathrm{a}}_{i}\mathrm{\parallel }}_{2}\) avec \({\mathrm{a}}^{i}\) et \({\mathrm{a}}_{i}\) , respectivement, les \(i\) ème colonne et ligne de \({\mathrm{A}}_{f}\) .
Remarques:
Cette technique a été généralisée à toute norme matricielle induite par une norme discrète de [33]_
\({l}^{\mathrm{q.}}\)
Son emploi est très répandu en calcul scientifique et notamment parmi les solveurs directs de système d’équations linéaires.
La base de calcul de l’ordinateur, notée \(\beta\) , intervient dans la détermination des termes des matrices \({\mathrm{D}}_{k}\) . Afin de minimiser les erreurs d’arrondi, on choisit les éléments de \({\mathrm{D}}_{k}\) afin qu’ils soient des puissances de cette base.
Soient \({\mathrm{R}}_{k}\) et \({\mathrm{C}}_{k}\) les \(p\) normes (en pratique on prend souvent \(p=2\) ), respectivement des ligne et colonne \(i\) de la matrice \({A}_{k-1}\) (\(i\) est choisi de telle façon que \(i-1\equiv k-1[n]\) ). En supposant que \({\mathrm{R}}_{k}{\mathrm{C}}_{k}\mathrm{\ne }0\) , on montre alors qu’il existe un unique entier signé \(\sigma\) tel que:
\({\beta}^{2\sigma -1}<\frac{{\mathrm{R}}_{k}}{{\mathrm{C}}_{k}}\le {\beta}^{2\sigma +1}\)
Soit \(f={\beta}^{\sigma}\) , on définit la matrice \(\stackrel{ˉ}{{D}_{k}}\) telle que:
\({\stackrel{ˉ}{\mathrm{D}}}_{k}=\lbrace \begin{array}{cc}\mathrm{I}+(f-1){\mathrm{e}}_{i}{\mathrm{e}}_{i}^{T}& \text{si}{({\mathrm{C}}_{k}f)}^{p}+{({R}_{k}/f)}^{p}<\gamma ({\mathrm{C}}_{k}^{p}+{\mathrm{R}}_{k}^{p})\\ \mathrm{I}& \mathit{sinon}\end{array}\)
où \(0<\gamma \le 1\) est une constante et \({\mathrm{e}}_{i}\) le \(i\) ème vecteur canonique. On construit alors itérativement:
\(\lbrace \begin{array}{c}{\mathrm{D}}_{k}={\stackrel{ˉ}{\mathrm{D}}}_{k}{\mathrm{D}}_{k-1},\\ {\mathrm{A}}_{k}={\stackrel{ˉ}{\mathrm{D}}}_{k}^{\text{-1}}{\mathrm{A}}_{k-1}{\stackrel{ˉ}{\mathrm{D}}}_{k}\end{array}\)
en initialisant \({\mathrm{D}}_{0}=\mathrm{I}\) . Le processus s’arrête dès que \({\stackrel{ˉ}{\mathrm{D}}}_{k}=\mathrm{I}\) .
Remarques:
Avant d’effectuer l’équilibrage, une recherche des valeurs propres isolées est effectuée en détectant la présence de lignes et de colonnes quasi-nulles (tous les termes sont nuls, sauf celui placé sur la diagonale). Lorsqu’il en existe on peut, en effectuant des permutations idoines, mettre la matrice de travail sous la forme blocs suivante:

Il n’est alors nécessaire d’effectuer l’équilibrage que sur le bloc central \(X\) car les termes diagonaux des deux matrices triangulaires supérieures sont des valeurs propres de la matrice de travail.
Dans Code_Aster, on a choisi \(p=1\) et \(\gamma =0.95\) (cf. [PR71]).
Avant d’appliquer la méthode QR, on commence par équilibrer la matrice de travail et ensuite, on la transforme sous forme de Hessenberg supérieure. Une fois le calcul QR effectué, on remonte des vecteurs de Ritz aux vecteurs propres via l’inverse des transformations orthogonales dues à la mise sous forme Hessenberg et à l’équilibrage. C’est ce procédé qui est mis en place aussi bien dans Lanczos que dans IRAM. Cependant outre le fait qu’il nécessite le stockage de ces matrices orthogonales, il est aussi et surtout extrêmement sensible aux effets d’arrondis. Ainsi, il serait grandement préférable d’estimer les vecteurs propres via une méthode des puissances inverses initialisée par les valeurs propres exhumées.
La méthode QL#
La factorisation QL d’une matrice \(A\) consiste à orthonormaliser ses vecteurs colonnes en commençant par le dernier (contrairement à l’algorithme QR qui débute par le premier) donnant ainsi une matrice \(L\) triangulaire inférieure régulière. On montre d’ailleurs que l’algorithme QL appliqué à l’opérateur \(A\) inversible est équivalent à l’algorithme QR appliqué à \({A}^{\text{-*}}\) (matrice transposée conjuguée de l’inverse de \(A\) ).
La méthode mise en place dans Code_Aster est identique à la méthode de simple shift de J.H.Wilkinson vue précédemment en adaptant la recherche de ce shift au mineur \(2\times 2\) le plus haut.
Remarque:
Contrairement à QR qui capture les valeurs propres par ordre croissant de module, on obtient ici préférentiellement les modes dominants, puis les autres, par ordre décroissant de module.
Annexe 2. Orthogonalisation de Gram-Schmidt#
Introduction#
On a vu à plusieurs reprises dans ce document que la qualité d’orthogonalisation d’une famille de vecteurs est cruciale pour le bon déroulement des algorithmes et la qualité des modes obtenus. Cette tâche est d’ailleurs à réaliser en permanence d’où l’importance d’un algorithme rapide.
Les algorithmes d’orthonormalisation simples sont déduits du processus classique de Gram-Schmidt mais ils sont souvent «conditionnellement stables» (la qualité de leur travail dépend du conditionnement matriciel de la famille à orthonormaliser). Ce défaut de robustesse peut s’avérer problématique pour traiter des situations particulièrement mal conditionnées. On leur préfère alors des algorithmes plus onéreux mais robustes, à base de projections ou de rotations: les transformations spectrales de Householder et de Givens.
En pratique, pour l’implantation de la méthode IRA dans Code_Aster , nous avons retenu une version itérative du processus de Gram-Schmidt (l’IGSM de Kahan-Parlett[Par80]) Elle réalise un bon compromis entre la robustesse et la complexité calcul puisqu’elle est inconditionnellement stable et permet d’orthogonaliser à la précision machine près, en, au maximum, deux fois plus de temps qu’un Gram-Schmidt classique (GS).
Dans les paragraphes suivants nous allons détailler le fonctionnement de l’algorithme de base, ainsi que celui de ces deux principales variantes. La première a été mise en place dans CALC_MODES avec OPTION parmi [“PROCHE”,”AJUSTE”,”SEPARE”] et la seconde est utilisée dans CALC_MODES avec OPTION parmi [“BANDE”,”CENTRE”,”PLUS_*”,”TOUT”]. Un comparatif très percutant de ces méthodes est décliné dans [Vau00] (pp33-36) à partir d’un exemple très simple.
Algorithme de Gram-Schmidt (GS)#
Étant donné \(k\) vecteurs indépendants de \({ℝ}^{n}\) , \({({\mathrm{x}}_{i})}_{i=1,k}\) on désire obtenir \(k\) vecteurs orthonormaux (par rapport à un produit scalaire quelconque) \({({\mathrm{y}}_{i})}_{i=1,k}\) de l’espace qu’ils engendrent. En d’autres termes, on souhaite obtenir une autre famille orthonormale engendrant le même espace. Le procédé d’orthonormalisation classique de Gram-Schmidt est le suivant:
\(\begin{array}{c}\text{Pour}\text{i =}1,k\text{faire}\\ \text{Pour}\text{j =}1,i\text{-1 faire}\\ \text{calcul de}{r}_{ji}=({\mathrm{y}}_{j},{\mathrm{x}}_{i})\\ \text{Fin boucle.}\\ \text{calcul de}{\stackrel{ˆ}{\mathrm{y}}}_{i}={\mathrm{x}}_{i}-\sum_{j=1,i-1}{r}_{ji}{\mathrm{y}}_{j},\\ \text{calcul de}{r}_{ii}=\mathrm{\parallel }{\stackrel{ˆ}{\mathrm{y}}}_{i}\mathrm{\parallel },\\ \text{calcul de}{\mathrm{y}}_{i}=\frac{{\stackrel{ˆ}{\mathrm{y}}}_{i}}{{r}_{ii}}\\ \text{Fin boucle}.\end{array}\)
Algorithme 2.1. Algorithme de Gram-Schmidt (GS).
Ce procédé est simple mais très instable du fait des erreurs d’arrondi, ce qui a pour effet de produire des vecteurs non orthogonaux. En particulier lorsque les vecteurs initiaux sont presque dépendants cela crée des écarts de magnitude importants dans la deuxième étape du processus
\({\stackrel{ˆ}{\mathrm{y}}}_{i}={\mathrm{x}}_{i}-\sum_{j=1,i-1}{r}_{ij}{\mathrm{y}}_{j}\)
D’un point de vue numérique, la gestion de ces écarts est très difficile.
Remarque:
En notant \(Q\) la matrice engendrée par les \({({\mathrm{y}}_{i})}_{i=1,k}\) , on a donc construit explicitement une factorisation QR de la matrice initiale \(X\) liée aux \({({\mathrm{x}}_{i})}_{i=1,k}\) . C’est en fait le but de tout procédé d’orthogonalisation.
Algorithme de Gram-Schmidt Modifié (GSM)#
Afin d’évacuer ces instabilités numériques, on réorganise l’algorithme précédent. Mathématiquement équivalent au procédé précédent, celui-ci est alors beaucoup plus robuste car il évite les écarts de magnitude importants entre les vecteurs manipulés dans l’algorithme.
Dans le procédé initial, les vecteurs orthogonaux \({\mathrm{y}}_{i}\) sont obtenus sans tenir compte des \(i-1\) orthogonalisations précédentes. Avec le Gram-Schmidt Modifié, on orthogonalise plus progressivement en tenant compte des altérations précédentes suivant le processus ci-dessous.
\(\begin{array}{c}\text{Pour}\text{i =}1,k\text{faire}\\ \text{}{\stackrel{ˆ}{\mathrm{y}}}_{i}={\mathrm{x}}_{i}\\ \text{Pour}\text{j =}1,i\text{-1 faire}\\ \text{calcul de}{r}_{ji}=({\mathrm{y}}_{j},{\mathrm{x}}_{i}),\\ \text{calcul de}{\stackrel{ˆ}{\mathrm{y}}}_{i}={\mathrm{x}}_{i}-{r}_{ji}{\mathrm{y}}_{j},\\ \text{Fin boucle.}\\ \text{calcul de}{r}_{ii}=\mathrm{\parallel }{\stackrel{ˆ}{\mathrm{y}}}_{i}\mathrm{\parallel },\\ \text{calcul de}{\mathrm{y}}_{i}=\frac{{\stackrel{ˆ}{\mathrm{y}}}_{i}}{{r}_{ii}}\\ \text{Fin boucle}.\end{array}\)
Algorithme 2.2. Algorithme de Gram-Schmidt Modifié (GSM).
L’orthonormalité des vecteurs de base est bien meilleure avec ce procédé et elle peut même s’obtenir à la précision machine et à une constante (dépendant du conditionnement de \(X\) ) près. Cependant, pour traiter des situations particulièrement mal conditionnées, cette stabilité «conditionnelle» peut s’avérer rapidement problématique, d’où le recours à l’algorithme itératif suivant.
Remarque:
GSM est deux fois plus efficace qu’une méthode de Householder pour obtenir une factorisation QR de la matrice initiale \(X\) . Il requiert seulement \(O({\mathrm{2nk}}^{2})\) opérations (avec \(n\) le nombre de lignes de la matrice).
Algorithme de Gram-Schmidt Itératif (IGSM)#
Pour s’assurer néanmoins de l’ orthogonalitéà la précision machine près , on préconise de réaliser une seconde orthogonalisation . Et si, à l’issue de cette dernière, l’orthogonalité n’est pas assurée ce n’est plus la peine de recommencer, les quantités manipulées sont alors certainement très proches et leurs écarts oscillent autour de zéro. Cette approche est basée sur une analyse théorique due à W.Kahan et reprise par B.N.Parlett[Par80] (cf. pp105-110).

Algorithme 2.3. Algorithme de Gram-Schmidt Itératif de type Kahan-Parlett (IGSM).
Lors de l’utilisation d’IRAM dans Code_Aster , le critère \(\alpha\) est paramétré par le mot-clé PARA_ORTHO_SOREN (cf. §7.5). On montre que son intervalle de validité est \([1.2\varepsilon ,0.83-\varepsilon ]\) avec \(\varepsilon\) la précision machine et on lui attribue généralement la valeur 0.717 (par défaut).
Remarques:
Plus la valeur du paramètre est grande, moins la réorthogonalisation se déclenche, mais cela affecte la qualité du processus.
Contrairement à la version «maison» développée pour Lanczos ici les critères d’arrêts se concentrent sur les normes des vecteurs orthogonalisés plutôt que sur les produits scalaires inter-vecteurs qui ont plus tendance à répercuter les effets d’arrondi. Cela, joint à la suppression des itérations supérieures à deux, donc inutiles, peut expliquer le surcroît d’efficacité de la version de Kahan-Parlett.
D’après D.C.Sorensen la paternité de cette méthode est plutôt à attribuer à J.Daniel (papier de 1976 soumis à Mathematics of Computation, vol.30, pp772-795).
Annexe 3. Méthode de Jacobi#
Principe#
La méthode de Jacobi[LT86] permet de calculer toutes les valeurs propres d’un problème généralisé dont les matrices sont définies positives et symétriques (les matrices obtenues à chaque itération par la méthode de Bathe &Wilson vérifient ces propriétés; cf. § 8 ). Elle consiste à transformer les matrices \(A\) et \(B\) du GEP \(\mathrm{A}\mathrm{u}=\lambda \mathrm{B}\mathrm{u}\) en des matrices diagonales, en utilisant successivement des transformations semblables orthogonales (matrices de rotation de Givens). Le processus peut se schématiser de la manière suivante:


Algorithme 3.1. Processus de Jacobi
Les valeurs propres sont données par \(\lambda ={\mathrm{A}}^{d}{({\mathrm{B}}^{d})}^{\text{-1}}\) soit \(\lambda =\frac{{\mathrm{A}}_{ii}^{d}}{{\mathrm{B}}_{ii}^{d}}\) et la matrice des vecteurs propres vérifie:

Chaque matrice \({\mathrm{Q}}_{k}\) est choisie de manière à ce qu’un terme \((i,j)\) diagonal et non nul de \({\mathrm{A}}_{k}\) ou de \({\mathrm{B}}_{k}\) soit nul après la transformation.
Quelques choix#
Dans cet algorithme, on se rend compte que les points importants sont les suivants:
Comment choisir les termes à annuler ?
Comment mesurer le caractère diagonal des matrices quand \(k\) tend vers l’infini ?
Comment mesurer la convergence ?
Termes non diagonaux à annuler#
Pour le choix des termes à annuler, il existe plusieurs méthodes:
La première consiste à chaque étape \(k\) , à choisir le plus grand élément en module non diagonal de la matrice \({\mathrm{A}}_{k}\) ou \({\mathrm{B}}_{k}\) et à l’annuler en effectuant une rotation. Ce choix assure la convergence de la méthode de Jacobi mais coûte relativement cher (recherche de l’élément maximal).
La deuxième solution consiste à annuler successivement tous les éléments non diagonaux de ces matrices en suivant l’ordre naturel \({\mathrm{A}}_{13}^{k},\mathrm{....},{\mathrm{A}}_{\mathrm{1n}}^{k},{\mathrm{A}}_{23}^{k},\mathrm{....}\) . Quand on arrive à \({\mathrm{A}}_{n-1,n}^{k}\) , on recommence le cycle. Cette méthode converge lentement.
Une variante de cette méthode, consiste tout en suivant l’ordre naturel des termes, à annuler seulement ceux qui sont supérieurs à une précision \({\varepsilon}_{k}\) donnée. Au bout d’un cycle, on diminue la valeur de ce critère et on recommence. C’est cette stratégie qui est utilisée dans Code_Aster .
Test de convergence#
Pour tester la convergence et le caractère diagonal des matrices, on opère ainsi. On vérifie que tous les facteurs de couplage définis par:
\({f}_{{\mathrm{A}}_{ij}}=\frac{∣{\mathrm{A}}_{ij}∣}{\sqrt{∣{\mathrm{A}}_{ii}{\mathrm{A}}_{jj}∣}}\) \({f}_{{\mathrm{B}}_{ij}}=\frac{∣{\mathrm{B}}_{ij}∣}{\sqrt{∣{\mathrm{B}}_{ii}{\mathrm{B}}_{jj}∣}}\) \(i\ne j\)
sont inférieurs à une précision donnée (caractère diagonal des matrices). On contrôle également la convergence des valeurs propres via l’indicateur
\({f}_{\lambda}=\underset{i}{\max}\frac{∣{\lambda}_{i}^{k}-{\lambda}_{i}^{k-1}∣}{{\lambda}_{i}^{k-1}}\)
afin qu’il reste inférieur à une précision donnée \({\varepsilon}_{\mathrm{jaco}}\) .
Algorithme implanté dans Code_Aster#
L’algorithme mis en oeuvre dans Code_Aster se résume à:
Initialisation de la matrice des vecteurs propres à la matrice identité.
Initialisation des valeurs propres.
Définir la précision de convergence dynamique requise.
Définir la précision globale \({\varepsilon}_{\mathrm{glob}}\) .
Pour chaque cycle \(k=1,{\text{n\_max}}_{\mathit{jaco}}\)
Définir la tolérance dynamique : \({\varepsilon}_{k}={({\varepsilon}_{\mathrm{dyn}})}^{k}\) ,
\(l=0\) ,
Pour chaque ligne \(i=1,n\)
Pour chaque colonne \(j=1,n\)
Calcul des facteurs de couplage, \({f}_{{\mathrm{A}}_{ij}^{k,l}}=\frac{∣{\mathrm{A}}_{ij}^{k,l}∣}{\sqrt{∣{\mathrm{A}}_{ii}^{k,l}{\mathrm{A}}_{jj}^{k,l}∣}}\) \({f}_{{\mathrm{B}}_{ij}^{k,l}}=\frac{∣{\mathrm{B}}_{ij}^{k,l}∣}{\sqrt{∣{\mathrm{B}}_{ii}^{k,l}{\mathrm{B}}_{jj}^{k,l}∣}}\) \(i\ne j\)
Si \({f}_{{A}_{ij}^{k,l}}\text{ou}{f}_{{B}_{ij}^{k,l}}\ge {\varepsilon}_{k}\) alors
Calcul des coefficients de la rotation de Givens,
Transformation des matrices \({\mathrm{A}}^{k,l}\) et \({\mathrm{B}}^{k,l}\) ,
Transformation des vecteurs propres,
\(l=l+1\)
Fin si.
Fin boucle.
Fin boucle.
Calcul des valeurs propres \({\lambda}_{i}^{k}=\frac{{\mathrm{A}}_{ii}^{k,l}}{{\mathrm{B}}_{ii}^{k,l}}\) .
Calcul de \({f}_{\lambda}=\underset{i}{\max}\frac{∣{\lambda}_{i}^{k}-{\lambda}_{i}^{k-1}∣}{{\lambda}_{i}^{k-1}}\) .
Calcul des facteurs de couplage globaux
\({f}_{\mathrm{A}}=\underset{\begin{array}{c}i,j\\ i\mathrm{\ne }j\end{array}}{\mathit{Max}}\frac{∣{\mathrm{A}}_{ij}^{k,l}∣}{\sqrt{∣{\mathrm{A}}_{ii}^{k,l}{\mathrm{A}}_{jj}^{k,l}∣}}\) \({f}_{\mathrm{B}}=\underset{\begin{array}{c}i,j\\ i\mathrm{\ne }j\end{array}}{\mathit{Max}}\frac{∣{\mathrm{B}}_{ij}^{k,l}∣}{\sqrt{∣{\mathrm{B}}_{ii}^{k,l}{\mathrm{B}}_{jj}^{k,l}∣}}\)
Si \({f}_{\text{A}}\le {\varepsilon}_{\mathrm{glob}}\text{et}{f}_{\text{B}}\le {\varepsilon}_{\mathrm{glob}}\text{et}{f}_{\lambda}\le {\varepsilon}_{\mathrm{glob}}\) alors
Correction des modes propres (divisons par \(\sqrt{{\mathrm{B}}_{ii}^{k}}\) ),
Exit;
Fin si.
Fin boucle.
Algorithme 3.1. Méthode de Jacobi implantée dans Code_Aster.
On note \({\text{n\_max}}_{\mathrm{jaco}}\) le nombre maximum d’itérations permises.
Remarque:
Les matrices \(\mathrm{A}\) et \(B\) étant symétriques, seulement la moitié des termes est stockée sous forme d’un vecteur.
Matrice de rotation de Givens#
On cherche à chaque étape à annuler les termes se trouvant en position \(i\) et \(j\) \((i\ne j)\) des matrices \({A}^{k,l}\) et \({B}^{k,l}\) en les multipliant par une matrice de rotation qui a la forme suivante:
\({\mathrm{G}}_{ll}=1l=1,n;{\mathrm{G}}_{ij}=a;{\mathrm{G}}_{ji}=b\)
les autres termes étant nuls. On souhaite avoir \({\mathrm{A}}_{ij}^{k,l+1}={\mathrm{B}}_{ij}^{k,l+1}=0\) ce qui conduit à:
\(\lbrace \begin{array}{c}a{\mathrm{A}}_{ii}^{k,l}+(1+\mathit{ab}){\mathrm{A}}_{ij}^{k,l}+b{\mathrm{A}}_{jj}^{k,l}=0\\ a{\mathrm{B}}_{ii}^{k,l}+(1+\mathit{ab}){\mathrm{B}}_{ij}^{k,l}+b{\mathrm{B}}_{jj}^{k,l}=0\end{array}\)
car \({\mathrm{A}}^{k,l+1}={\mathrm{G}}^{T}{\mathrm{A}}^{k,l}\mathrm{G}\) et \({\mathrm{B}}^{k,l+1}={\mathrm{G}}^{T}{\mathrm{B}}^{k,l}\mathrm{G}\) . Si les deux équations sont proportionnelles on a:
\(a=0\) et \(b=\frac{-{\mathrm{A}}_{ij}^{k,l}}{{\mathrm{A}}_{jj}^{k,l}}\)
sinon:
\(a=\frac{{c}_{2}}{d}b=\frac{-{c}_{1}}{d}\)
avec:
\({c}_{1}={\mathrm{A}}_{ii}^{k,l}{\mathrm{B}}_{ij}^{k,l}-{\mathrm{B}}_{ii}^{k,l}{\mathrm{A}}_{jj}^{k,l}\) \({c}_{2}={\mathrm{A}}_{jj}^{k,l}{\mathrm{B}}_{ij}^{k,l}-{\mathrm{B}}_{jj}^{k,l}{\mathrm{A}}_{ij}^{k,l}\)
\({c}_{3}={\mathrm{A}}_{ii}^{k,l}{\mathrm{B}}_{jj}^{k,l}-{\mathrm{B}}_{ii}^{k,l}{\mathrm{A}}_{jj}^{k,l}\) \(d=\frac{{c}_{3}}{2}+\mathrm{sign}({c}_{3})\sqrt{{(\frac{{c}_{3}}{2})}^{2}+{c}_{1}{c}_{2}}\)
Remarque:
Si \(d=0\) alors on est dans le cas proportionnel.