r4.03.06 Algorithmes de recalage#
Résumé:
Dans ce document on présente les algorithmes de recalage implémentés dans MACR_RECAL. Il s’agit d’abord d’un algorithme de Levenberg-Marquardt avec bornes et ensuite d’un algorithme évolutionnaire.
Pour le premier on décrit dans un premier temps la méthode générale avant d’en préciser certains éléments. Sont détaillés le calcul de la fonctionnelle, de la matrice Jacobienne, la détermination du paramètre initial de régularisation ainsi que son évolution, la gestion des bornes et le critère de convergence.
Les principes généraux des algorithmes génétiques, et en particulier l’algorithme évolutionnaire, ainsi que la mise en œuvre dans Code_Aster , sont présentés dans la deuxième partie du document.
Algorithme de Levenberg-Marquardt#
Position du problème#
Il existe plusieurs familles d’algorithmes de minimisation [bib1]. Pour les problèmes relativement réguliers, les plus utilisées sont les méthodes de descente. Leur principe est de générer de manière itérative une suite \({({c}^{k})}_{k\in N}\) définie par:
\(({c}^{k+1})={c}^{k}+{\alpha}^{k}{g}^{k}\) éq 2.1-1
telle que, pour \(f(x)=J({c}^{k}+x{g}^{k}),x\in {R}_{+}^{\text{*}}\)
\(f(x)\) est décroissante au voisinage de \({0}^{+}\)
\(f({\alpha}^{k})=\underset{x>0}{\text{Min}}f(x)\)
\({g}^{k}\) est la direction de descente au pas \(k\) . C’est la méthode de détermination de \({g}^{k}\) qui conditionne la nature donc l’efficacité de l’algorithme utilisé, sachant que ces techniques sont principalement basées sur des approximations de \(J\) à l’ordre 1 ou à l’ordre 2. Pour l’algorithme de Levenberg-Marquardt, on manipule une approximation à l’ordre 2 de la fonctionnelle.
Résolution#
Dans le cadre du recalage, on manipule des fonctionnelles coût moindre carré du type:
\(J(c)=\sum_{n=1}^{N}{j}_{n}^{2}(c)\) éq 2.2-1
où par exemple \({j}_{n}(c)=({F}_{n}^{\text{calc}}(c)-{F}_{n}^{\exp})\) , avec des notations évidentes.
La particularité de ces fonctionnelles coût réside dans le fait que l’on connaît la forme de leurs dérivées premières et secondes:
\(({\nabla}_{c}J(c)){}_{i}\text{}=2\sum_{n=1}^{N}{j}_{n}(c)\frac{\partial {j}_{n}}{\partial {c}_{i}}\) éq 2.2-2
\((H(c)){}_{ij}\text{}=2\sum_{n=1}^{N}(\frac{\partial {j}_{n}}{\partial {c}_{i}}.\frac{\partial {j}_{n}}{\partial {c}_{j}}+{j}_{n}(c)\frac{{\partial}^{2}{j}_{n}}{\partial {c}_{i}\partial {c}_{j}})\) éq 2.2-3
Alors, en supposant que le deuxième terme de l’équation précédente est négligeable devant le premier (ce qui est vrai quand les \({j}_{k}\) sont linéaires en \(c\) : ce terme est nul), on peut réécrire:
\((H(c)){}_{ij}\text{}\approx 2\sum_{n=1}^{N}\frac{\partial {j}_{n}}{\partial {c}_{i}}.\frac{\partial {j}_{n}}{\partial {c}_{j}}\) éq 2.2-4
Il est intéressant à ce niveau d’introduire la matrice de sensibilité ou matrice Jacobienne définie par:
\(A=\left[\begin{array}{cccc}\frac{\partial {j}_{1}}{\partial {c}_{1}}& \frac{\partial {j}_{1}}{\partial {c}_{2}}& ...& \frac{\partial {j}_{1}}{\partial {c}_{n}}\\ \frac{\partial {j}_{2}}{\partial {c}_{1}}& \frac{\partial {j}_{2}}{\partial {c}_{2}}& ...& ...\\ ...& ...& ...& ...\\ ...& ...& ...& ...\\ \frac{\partial {j}_{N}}{\partial {c}_{1}}& \frac{\partial {j}_{N}}{\partial {c}_{2}}& ...& \frac{\partial {j}_{N}}{\partial {c}_{n}}\end{array}\right]\) éq 2.2-5
On peut ainsi exprimer le gradient et le Hessien par:
\({\nabla}_{c}J({c}^{k})=2{A}^{T}j\) éq 2.2-6
\(H({c}^{k})\approx 2{A}^{T}A\) éq 2.2-7
avec \(j={\left[{j}_{1},...,{j}_{N}\right]}^{T}\) .
Écrivons alors le développement limité à l’ordre 2 de \(J\) :
\(J(c)\approx J({c}^{k})+{(c-{c}^{k})}^{T}.{\nabla}_{c}J({c}^{k})+\frac{1}{2}{(c-{c}^{k})}^{T}H({c}^{k}).(c-{c}^{k})\) éq 2.2-8
Soit \({g}^{k}=c-{c}^{k}\) , le pas de descente au point \({c}^{k}\) , il doit vérifier la condition de stationnarité de l’approximation quadratique:
\({\nabla}_{c}J({c}^{k})+H({c}^{k}){g}^{k}=0\) éq 2.2-9
D’après l’expression du gradient et du Hessien de \(J\) , on peut écrire :
\(({A}^{T}A){g}^{k}=-{A}^{T}j\) éq 2.2-10
La résolution de cette équation mène à un algorithme connu sous le nom de Gauss-Newton, très efficace mais qui présente néanmoins quelques inconvénients:
\(({A}^{T}A)\) peut être quasiment singulière et causer la non-existence de solution.
On n’a aucun contrôle sur \({g}^{k}\) , qui peut être trop grand et donc sortir les paramètres de l’espace admissible.
Pour pallier ces inconvénients, on préfère utiliser l’algorithme de Levenberg-Marquardt qui propose une régularisation de l’algorithme de Gauss-Newton:
\(({A}^{T}A+\lambda I){g}^{k}=-{A}^{T}j\) éq 2.2-11
où \(\lambda\) est un scalaire et \(I\) la matrice identité.
On remarque que si \(\lambda =0\) , on retrouve la direction donnée par Gauss-Newton et si \(\lambda \to +\infty\) , on retrouve la direction donnée par l’opposée du gradient de \(J\) i.e. la plus grande pente.
L’algorithme de Levenberg-Marquardt consiste donc, en partant d’une valeur de \(\lambda\) «assez élevée», de la diminuer d’un facteur 10 par exemple, à chaque décroissance de \(J\) . On passe ainsi graduellement d’un algorithme de plus grande pente à l’algorithme de Gauss-Newton. On peut donc présenter cette procédure sous la forme:
Choix d’un point de départ \({c}^{0}\) et d’une valeur initiale de \(\lambda\)
A l’itération \(k\) , résoudre
\(\begin{array}{}({A}^{T}A+\lambda I){g}^{k}=-{A}^{T}j\\ {c}^{k+1}={c}^{k}+{g}^{k}\end{array}\)
Si \(J({c}^{k+1})<J({c}^{k})\) , alors \(\lambda =\lambda /10\) sinon \(\lambda =\lambda \ast 10\)
Test de convergence
Remarque:
Nous avons considéré ci-dessus l’algorithme de Levenberg-Marquardt sous l’angle de la régularisation de l’algorithme de Gauss-Newton. Il est possible de donner un éclairage différent à cette algorithme en le considérant comme un algorithme de région de confiance [bib *2*]. En effet, on peut montrer aisément que le système [éq 2.2-11] est la condition de stationnarité du problème de minimisation:
Déterminer \({g}^{k}\) tel que \({g}^{k}=\text{ArgMin}({g}^{kT}.{A}^{T}j+\frac{1}{2}{g}^{kT}{A}^{T}A{g}^{k})\) soumis à \(\parallel {g}^{k}\parallel \le {D}^{k}\) .
Où \({D}^{k}=-{({A}^{T}A+\lambda I)}^{-1}{A}^{T}j\text{et}\lambda \ge 0\) .
Il s’agit là d’une implantation très simple de l’algorithme de Levenberg-Marquardt au sein de laquelle différentes questions ne sont pas abordées:
Comment définir la fonctionnelle \(J\) quand on dispose de plusieurs essais?
Comment choisir la valeur initiale de \(\lambda\) ?
Comment faire évoluer \(\lambda\) de manière plus fine?
Comment définir le domaine d’évolutions de chaque paramètre?
Nous allons préciser ces différents points dans la suite.
Mise en œuvre pratique#
Définition de la fonctionnelle#
Lors d’un recalage, l’utilisateur dispose souvent de plusieurs mesures différentes; il s’agit de grandeurs physiques discrètes, éventuellement de natures différentes, mesurées au cours d’un ou plusieurs essais. Ce sont des fonctions d’un paramètre donné noté \(t\) (temps, abscisse, …) que l’on peut donc représenter par:
\({F}_{1}^{\exp}=\left[\begin{array}{cc}{t}_{1}& {f}_{1}^{\exp}({t}_{1})\\ ⋮& ⋮\\ {t}_{N}& {f}_{1}^{\exp}({t}_{N})\end{array}\right]{F}_{2}^{\exp}=\left[\begin{array}{cc}{t}_{1}& {f}_{2}^{\exp}({t}_{1})\\ ⋮& ⋮\\ {t}_{M}& {f}_{2}^{\exp}({t}_{M})\end{array}\right]{F}_{L}^{\exp}=\left[\begin{array}{cc}{t}_{1}& {f}_{L}^{\exp}({t}_{1})\\ ⋮& ⋮\\ {t}_{P}& {f}_{L}^{\exp}({t}_{P})\end{array}\right]\) éq 3.1-1
Chacune de ces mesures expérimentales dispose de son pendant
\({F}_{1}^{\text{calc}}({c}^{k})=\left[\begin{array}{cc}{\tilde{t}}_{1}& {f}_{1}^{\text{calc}}({c}^{k},{\tilde{t}}_{1})\\ ⋮& ⋮\\ {\tilde{t}}_{I}& {f}_{1}^{\text{calc}}({c}^{k},{\tilde{t}}_{I})\end{array}\right]{F}_{2}^{\text{calc}}({c}^{k})=\left[\begin{array}{cc}{\tilde{t}}_{1}& {f}_{2}^{\text{calc}}({c}^{k},{\tilde{t}}_{1})\\ ⋮& ⋮\\ {\tilde{t}}_{J}& {f}_{2}^{\text{calc}}({c}^{k},{\tilde{t}}_{J})\end{array}\right]{F}_{L}^{\text{calc}}({c}^{k})=\left[\begin{array}{cc}{\tilde{t}}_{1}& {f}_{L}^{\text{calc}}({c}^{k},{\tilde{t}}_{1})\\ ⋮& ⋮\\ {\tilde{t}}_{K}& {f}_{L}^{\text{calc}}({c}^{k},{\tilde{t}}_{K})\end{array}\right]\) éq 3.1-2
calculé pour un jeu de paramètre \({c}^{k}\) donné. Remarquons que les grandeurs calculées ne sont pas forcément en même nombre que les grandeurs mesurées ni évaluées pour la même valeur du paramètre \(t\) . On peut alors définir la fonctionnelle moindres carrés à minimiser par:
\(J({c}^{k})=\frac{\sum_{i=1}^{N}{(\frac{{f}_{1}^{\exp}({t}_{i})-{f}_{1}^{\text{calc}}({c}^{k},{t}_{i})}{{f}_{1}^{\exp}({t}_{i})})}^{2}+\sum_{i=1}^{M}{(\frac{{f}_{2}^{\exp}({t}_{i})-{f}_{2}^{\text{calc}}({c}^{k},{t}_{i})}{{f}_{2}^{\exp}({t}_{i})})}^{2}+...+\sum_{i=1}^{P}{(\frac{{f}_{L}^{\exp}({t}_{i})-{f}_{L}^{\text{calc}}({c}^{k},{t}_{i})}{{f}_{L}^{\exp}({t}_{i})})}^{2}}{J({c}^{0})}\) éq 3.1-3
Il est important de remarquer que:
si une mesure calculée \({f}_{j}^{\text{calc}}\) n’est pas définie à un instant \({t}_{i}\) , alors on interpole linéairement sa valeur
si une mesure expérimentale \({f}_{j}^{\exp}\) est nulle, on ne divise pas la quantité \({f}_{j}^{\exp}({t}_{i})-{f}_{j}^{\text{calc}}({c}^{k},{t}_{i})\) et elle est présente telle quelle dans l’expression de la fonctionnelle
la fonctionnelle \(J\) est normalisée de manière à valoir 1. au début des itérations de recalage
Expression de la matrice Jacobienne#
Pour le calcul de la matrice Jacobienne, on définit le vecteur \(j\) des erreurs par:
\(j=\left[\begin{array}{c}\frac{{f}_{1}^{\exp}({t}_{1})-{f}_{1}^{\text{calc}}({c}^{k},{t}_{1})}{{f}_{1}^{\exp}({t}_{1})}\\ ⋮\\ \frac{{f}_{1}^{\exp}({t}_{N})-{f}_{1}^{\text{calc}}({c}^{k},{t}_{N})}{{f}_{1}^{\exp}({t}_{N})}\\ \frac{{f}_{2}^{\exp}({t}_{1})-{f}_{2}^{\text{calc}}({c}^{k},{t}_{1})}{{f}_{2}^{\exp}({t}_{1})}\\ ⋮\\ ⋮\\ \frac{{f}_{P}^{\exp}({t}_{L})-{f}_{P}^{\text{calc}}({c}^{k},{t}_{L})}{{f}_{P}^{\exp}({t}_{L})}\end{array}\right]\) éq 3.2-1
Soit:
\({j}_{i}^{K}=\frac{{f}_{K}^{\exp}({t}_{i})-{f}_{K}^{\text{calc}}({c}^{k},{t}_{i})}{{f}_{K}^{\exp}({t}_{i})}\) éq 3.2-2
On retrouve alors l’expression de la matrice Jacobienne de [éq 2.2-5]:
\({\rm A}=\left[\begin{array}{cccc}\frac{\partial {j}_{1}^{1}}{\partial {c}_{1}}& \frac{\partial {j}_{1}^{1}}{\partial {c}_{2}}& \cdots & \frac{\partial {j}_{1}^{1}}{\partial {c}_{n}}\\ \cdots & \cdots & \cdots & \cdots \\ \frac{\partial {j}_{N}^{1}}{\partial {c}_{1}}& \frac{\partial {j}_{N}^{1}}{\partial {c}_{2}}& \cdots & \frac{\partial {j}_{N}^{1}}{\partial {c}_{n}}\\ \frac{\partial {j}_{1}^{2}}{\partial {c}_{1}}& \frac{\partial {j}_{1}^{2}}{\partial {c}_{2}}& \cdots & \cdots \\ \cdots & \cdots & \cdots & \cdots \\ \cdots & \cdots & \cdots & \cdots \\ \frac{\partial {j}_{L}^{P}}{\partial {c}_{1}}& \frac{\partial {j}_{L}^{P}}{\partial {c}_{2}}& \cdots & \frac{\partial {j}_{L}^{P}}{\partial {c}_{n}}\end{array}\right]\) éq 3.2-3
Où les termes sont calculés par différences finies directes:
\(\frac{\partial {j}_{1}^{1}}{\partial {c}_{i}}({c}_{1},...,{c}_{i},...,{c}_{n})\approx \frac{{j}_{1}^{1}({c}_{1},...,{c}_{i}+{\mathrm{\alpha c}}_{i},...,{c}_{n})-{j}_{1}^{1}({c}_{1},...,{c}_{i},...,{c}_{n})}{{\mathrm{\alpha c}}_{i}}\) éq 3.2-4
Régularisation du système linéaire#
Nous abordons ici le problème de la détermination et de l’évolution du paramètre de régularisation \(\lambda\) . On définit pour ce faire:
\({\lambda}_{\max}=\text{Max}(\text{Valeurs propres de}{A}^{T}A)\) , \({\lambda}_{\min}=\text{Min}(\text{Valeurs propres de}{\mathrm{A}}^{\mathrm{T}}\mathrm{A})\) , \(\mathrm{cond}={\lambda}_{\max}/{\lambda}_{\min}\) si \({\lambda}_{\min}\ne 0\)
\(Q(c)=J({c}^{k})+{(c-{c}^{k})}^{T}.{A}^{T}j+\frac{1}{2}{(c-{c}^{k})}^{T}.({A}^{T}A+\lambda I).(c-{c}^{k})\)
Valeur initiale de \(\lambda\)#
Connaissant les grandeurs ci-dessus, on définit l’algorithme suivant:
Si \({\lambda}_{\min}=0\) , alors \(\lambda =1.E-3{\lambda}_{\max}\)
Sinon
Si \(\mathrm{cond}<1.E5\) , alors \(\lambda =1.E-16{\lambda}_{\max}\)
Sinon \(\lambda =∣(1.E5{\lambda}_{\min}-{\lambda}_{\max})∣/10001\)
Remarque:
Dans le dernier cas, la valeur attribuée à \(\lambda\) a pour effet de ramener le conditionnement de \({A}^{T}A\) à \(1.E5\)
Évolution de la valeur de \(\lambda\)#
Pour faire évoluer \(\lambda\) , on définit le ratio \({R}^{k}=\frac{J({c}^{k})-J({c}^{k+1})}{Q({c}^{k})-Q({c}^{k+1})}\) , qui permet d’évaluer la validité de l’approximation quadratique de \(J\) : plus il est proche de 1, plus cette approximation est valable. On en déduit l’algorithme suivant [bib2] :
Si \({R}^{k}<0.25\) , alors \(\lambda =\lambda \times 10\)
Si \({R}^{k}>0.75\) , alors \(\lambda =\lambda /15\)
Limitations du domaine d’évolution des paramètres#
Pour des raisons diverses telles que pour garantir la validité physique des paramètres (module d’Young strictement positif, coefficient de Poisson compris entre \(0\) et \(0.5\) , …), il est nécessaire de limiter leur domaine d’évolution. On impose donc que \(c\) reste dans un domaine admissible \(O\) , convexe fermé de \({R}^{n}\) . Ceci impose donc des contraintes sur les paramètres:
\({c}_{\sup}>{c}^{k}+{g}^{k}>{c}_{\inf}\)
Après dualisation de ces conditions par introduction des multiplicateurs de Lagrange \({\mu}_{\inf}\) et \({\mu}_{\sup}\) , on résout le système:
Trouver \({g}^{k}\) \({\mu}_{\inf}\) \({\mu}_{\sup}\) tels que
\(\begin{array}{c}({A}^{T}A+\lambda I){g}^{k}+{\mu}_{\inf}+{\mu}_{\sup}=-{A}^{T}j\\ \lbrace \begin{array}{}{c}^{k}+{g}^{k}>{c}_{\inf}\\ {\mu}_{\inf}>0\\ {({c}^{k}+{g}^{k}-{c}_{\inf})}_{i}{({\mu}_{\inf})}_{i}=0\forall i=[1,n]\end{array}\\ \lbrace \begin{array}{}{c}^{k}+{g}^{k}<{c}_{\sup}\\ {\mu}_{\sup}<0\\ {({c}^{k}+{g}^{k}-{c}_{\sup})}_{i}{({\mu}_{\sup})}_{i}=0\forall i=[1,n]\end{array}\end{array}\)
Cette résolution s’effectue à l’aide d’un algorithme de contraintes actives. Pour toute précision sur cet algorithme, se reporter à [bib3] ou [bib4].
Adimensionnement#
On est souvent amenés à identifier des paramètres de natures physiques diverses. Les ordres de grandeur de ces paramètres peuvent être extrêmement différents. Ceci peut engendrer de très fortes différences dans les ordres de grandeur des composantes du gradient et du Hessien de la fonctionnelle coût et compromettre la résolution.
Pour pallier cette difficulté, il est impératif d’adimensionner les inconnues avant de débuter la résolution. Voici une procédure simple et efficace.
Soit \({c}^{0}={}^{T}\text{}\left[{c}_{1}^{0},{c}_{2}^{0},...,{c}_{n}^{0}\right]\) , le vecteur initial des grandeurs à reconstruire. On définit la matrice d’adimensionnement \(D\) :
\(D=\left[\begin{array}{ccccc}{c}_{1}^{0}& & & & \\ & {c}_{2}^{0}& & & \\ & & & & \\ & & & {c}_{n-1}^{0}& \\ & & & & {c}_{n}^{0}\end{array}\right]\) éq 3.5-1
Alors, si les \({c}_{i}^{0}\) sont tous non nuls, on peut définir les inconnues adimensionnelles par:
\({\tilde{c}}^{0}={D}^{-1}.{c}^{0}\) éq 3.5-2
De même, on introduit une fonctionnelle coût adimensionnelle:
\(\tilde{\mathrm{J}}(\tilde{\mathrm{c}})=\mathrm{J}(\mathrm{D}.\tilde{\mathrm{c}})=\mathrm{J}(\mathrm{c})\) éq 3.5-3
Ainsi que son gradient:
\({\nabla}_{\tilde{\mathrm{c}}}\tilde{\mathrm{J}}(\tilde{\mathrm{c}})=\frac{\partial \tilde{\mathrm{J}}(\tilde{\mathrm{c}})}{\partial \tilde{\mathrm{c}}}=\frac{\partial \mathrm{J}(\mathrm{D}.\tilde{\mathrm{c}})}{\partial \tilde{\mathrm{c}}}=\frac{\partial \mathrm{J}(\mathrm{c})}{\partial \mathrm{c}}.\frac{\partial \mathrm{c}}{\partial \tilde{\mathrm{c}}}=\mathrm{D}.{\nabla}_{c}\mathrm{J}(\mathrm{c})\) éq 3.5-4
Et sa matrice Jacobienne:
\({\tilde{A}}_{ij}={A}_{ij}\times {c}_{j}^{0}\) éq 3.5-5
D’un point de vue algorithmique, le calcul de la matrice Jacobienne se fait classiquement avec la fonctionnelle \(J\) , puis elle est adimensionnée ainsi que les paramètres courants \(c\) , avant d’être transmis à l’algorithme de minimisation. À la sortie de ce dernier, les paramètres \(\tilde{c}\) sont redimensionnés pour permettre le calcul de la fonctionnelle \(J\) .
Critère de convergence#
Le critère de convergence utilisé dans MACR_RECAL consiste à tester la décroissance du gradient de la fonctionnelle. On rappelle que l’utilisation de ce critère se justifie naturellement par le fait que l’objectif de l’algorithme de recalage est d’annuler ce gradient.
\(\frac{\mid \mid {\nabla}_{c}J({c}^{k})\mid \mid }{\mid \mid {\nabla}_{c}J({c}^{0})\mid \mid }<\mathrm{Prec.}\) éq 3.6-1
Où \(\mathrm{Prec}\) est par défaut pris égal à 1.E-3.
Algorithme global#
De manière à expliciter l’enchaînement des diverses opérations décrites ci-dessus, on présente formellement l’algorithme du recalage:
Initialisations
\(k=0\)
calcul de \(A\) , adimensionnement de \(A\)
Calcul de \(\lambda\) initial
Itérations globales
Adimensionnement de \({c}^{k}\)
Résolution de l’équation de Levenberg-Marquardt
Imposition du respect des bornes
Redimensionnement de \({c}^{k+1}\)
Calcul de \(J({c}^{k+1})\)
Actualisation de \(\lambda\)
Calcul de \(A\) , adimensionnalisation de \(A\)
Test de convergence
\(k=k+1\)
Fin
Algorithme évolutionnaire#
Principes générales#
Les algorithmes évolutionnaires font partie de méthodes stochastiques d’optimisation globale basées sur les principes de l’évolution darwinienne des populations biologiques, méthodes communément nommées algorithmes génétiques. On commence d’ailleurs par rappeler les principales phases d’un algorithme génétique simple :
codage : chaque paramètre à recaler est codé en base binaire ; on crée la population ;
évaluation : chaque individu de la population se voit attribuer une mesure de son adaptation, calculée à partir de la fonction coût à minimiser ;
sélection : les individus qui vont produire la prochaine génération de la population sont sélectionnés, on retient naturellement les meilleurs au sens de l’adaptation ;
croisement : de nouveaux individus sont créés par les parents désignés à la phase précédente. En pratique il s’agit d’échanger une partie de la chaîne binaire entre deux parents ;
mutation : mécanisme aléatoire qui perturbe un ou plusieurs bits de la chaîne binaire des enfants afin de maintenir un certain niveau de diversité dans la population;
remplacement : une nouvelle population, de la même taille, est constituée en remplaçant les parents avec les enfants
Même si, par abus de langage, on utilise souvent le terme génétique à la place d’évolutionnaire, il faut rappeler les quelques différences qui particularisent les algorithmes évolutionnaires [5]:
les individus de la population sont représentés par des vecteurs de nombres réels et non plus dans le codage binaire ;
le processus de sélection est différent : alors que les algorithmes génétiques sélectionnent \(n\) parents pour créer \(n\) enfants qui les remplacent totalement dans la population, les programmes évolutionnaires génèrent m enfants à partir de \(n\) parents puis sélectionnent la nouvelle population en gardant les \(n\) meilleurs parmi l’ensemble \(n+m\) ;
les probabilités de croisement et de mutation peuvent varier au cours des générations.
L’intérêt de l’introduction d’un algorithme évolutionnaire dans Code_Aster tient dans sa capacité d’exploration multi-directionnelle de l’espace topologique des paramètres en évitant aussi que possible les minima locaux de la fonctionnelle à minimiser.
L’implémentation de cet algorithme dans Code_Aster est le fruit du partenariat entre le département AMA et Politecnico di Milano.
On note également que le défaut le plus critiqué des algorithmes évolutionnaires, celui d’être gourmands en temps CPU, peut être facilement éliminé par les nombreuses variantes de parallélisation possibles.
Fonctionnement de l’algorithme#
L’algorithme est lancé en choisissant METHODE= “GENETIQUE” ou “HYBRIDE” dans les options de la commande MACR_RECAL. Dans le deuxième cas, l’algorithme évolutionnaire va réaliser une recherche grossière suivie d’une optimisation par l’algorithme de Levenberg-Marquardt.
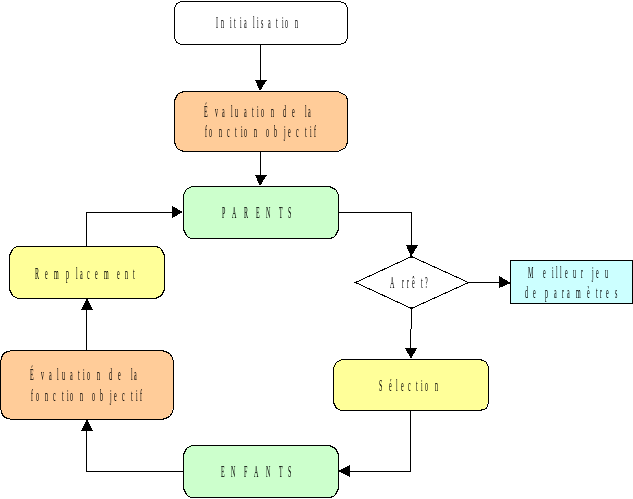
Figure 3.2-a Schéma logique du fonctionnement de l’algorithme évolutionnaire
Le fonctionnement global de l’algorithme est illustré sur le schéma logique de la Figure 3.2-a et on décrit dans ce qui suit les étapes:
Initialisation : une population de jeux de paramètres est générée et tous les individus sont initialisés avec les valeurs initiales des paramètres à recaler. La taille de cette population est donnée par la valeur du paramètre NB_PARENTS imposée par l’utilisateur. Cette valeur dépend de plusieurs facteurs comme l’incertitude sur la solution: plus cette incertitude est grande plus la population doit être grande. On conseille donc de démarrer une étude de recalage en prenant pour cette valeur 10 et de l’affiner en fonction de résultats.
Évaluation de la fonctionnelle : il s’agit de la fonctionnelle présentée dans l’équation 3.1-3. Dans un premier temps, après l’étape d’initialisation, une seule évaluation est faite car tous les individus de la population sont identiques. Ensuite, dans la boucle de recalage, on fait autant d’évaluations de la fonctionnelle lors une itération que le nombre d’enfants (NB_FILS) imposé par l’utilisateur. Plus ce paramètre qui gère le taux de renouvellement de la population est grand, plus l’algorithme est gourmand en temps CPU dans cette étape. Par défaut le nombre d’enfants est fixé à 5 (moitié de la taille de la population imposée aussi par défaut).
Critère d’arrêt : une fois la population des \(n\) parents constituée et chaque individus ayant sa valeur de la fonctionnelle, on vérifie:
la meilleure valeur de la fonctionnelle;
le nombre d’itérations déjà réalisée par l’algorithme
Si la meilleure valeur de la fonctionnelle est inférieure au résidu relatif imposée par l’utilisateur (1.E-3 par défaut) ou si le nombre maximal d’itérations est atteint, le meilleur individus de la population est fourni comme solution.
Sélection : le meilleur individu de la population est sélectionné et c’est le seul (dans cette implémentation) qui a le droit de se reproduire et de générer les \(m\) enfants. Cette génération est quasi-aléatoire, autour du meilleur individu, avec un écart type imposée par l’utilisateur (mot-clé ECART_TYPE). Lors de cette étape, l’algorithme gère les bornes imposées aux paramètres par l’utilisateur. Les individus ainsi générés ne sont acceptés comme enfants que si ils sont à l’intérieur des bornes.
Remplacement : après avoir généré les m enfants, la population globale à ce stade de l’itération est de \(n+m\) (NB_PARENTS + NB_FILS). L’opérateur de remplacement réalise ici une hiérarchie des individus en fonction des valeurs associées de la fonctionnelle et remplace les individus de la population PARENTS avec les \(n\) meilleurs parmi les \(n+m\) .
Une des particularités de cette implémentation de l’algorithme évolutionnaire dans Code_Aster est l’absence, pour l’instant, des mécanismes de mutation et croisement.
Technique hybride de recalage#
En choisissant METHODE=”HYBRIDE” dans MACR_RECAL, l’utilisateur a la possibilité de combiner les avantages des algorithmes stochastiques (celui évolutionnaire ici) avec ceux des algorithmes déterministes (Levenberg-Marquardt en occurrence dans notre cas). Il s’agit donc de réaliser une première recherche «grossière» dans l’espace topologique des paramètres ce qui permettra à l’algorithme de Levenberg-Marquardt de démarrer l’optimisation avec un point de départ plus proche de la solution globale de la fonctionnelle.
Le dosage entre stochastique et déterministe est à fixer par l’utilisateur compte-tenu de son expertise. Une grande incertitude sur les valeurs optimales des paramètres à recaler doit imposer:
plus d’itérations de l’algorithme évolutionnaire;
un écart type plus grand pour les tirages au sort;
une taille de la population plus importante.
Ces sont les trois leviers que l’utilisateur a à sa disposition pour réaliser un recalage de qualité avec un niveau de performance (temps CPU et mémoire utilisée) satisfaisant.
Bibliographie#
J.C. CULIOLI : «Introduction à l’optimisation», Ellipses, 1994
BAZARAA, H.D. SHERALI & C.M. SHETTY : «Nonlinear Programming, Theory and Algorithms», Wiley & Sons, 1979
«Formulation discrète du contact-frottement», Document Code_Aster [R5.03.50]
KUNISCH & F. RENDL ; «An infeasible active set method for quadratic programming with simple bounds», SIAM Journal on Optimization, Volume 14, Number 1, 2003
Z.Michalewicz. «Genetic Algorithms+Data Structures = Evolution Programs». Springer Verlag, 1992–1996.
Description des versions du document#
Version Aster |
Auteur(s) Organisme(s) |
Description des modifications |
7.1 |
N.TARDIEU-R&D/AMA |
Texte initial |
10.1 |
I.NISTOR - R&D/AMA |