r6.02.03 Généralités sur les solveurs linéaires directs et utilisation de MUMPS#
Résumé
Dans le cadre des simulations thermo-mécaniques avec Code_Aster , l’essentiel des coûts calcul provient souvent de la construction et de la résolution des systèmes linéaires . Pour effectuer plus efficacement ces résolutions, Code_Astera fait le choix d’intégrer la méthode directe déployée dans le package MUMPS (‘Multifrontal Massively Parallel sparse direct Solver; P.R.Amestoy, J.Y.L’Excellent et al; CERFACS/CNRS/ENS LyonIRIT/INRIA/Université de Bordeaux). Ceci en complément de sa multifrontale «maison» (C.Rose) et de ses autres solveurs: ‘LDLT’, ‘GCPC’ et ‘PETSC’.
En mode parallèle distribué et en Out-Of-Core, le couplage Aster +MUMPS procure des gains en CPU de l’ordre de la douzaine sur 32 processeurs. Et ce, pour des consommations RAM , un comportement/périmètre fonctionnel et une précision des résultats au moins aussi bons que ceux de la multifrontale native du code.
Sur les gros problèmes, en activant les compressions BLR, on peut même gagner un facteur deux ou trois supplémentaires. Ce produit, via le parallélisme qu’il exhibe et ses fonctionnalités avancées (pivotage, pré/post-traitements, qualité de la solution…) facilite grandement le passage des études standards. De plus, Il reste souvent la seule alternative viable pour exploiter certaines modélisations/analyses (quasi-incompressible, X-FEM…) ou passer de très grosses études (en tant que solveur direct précis ou en tant que préconditionneur, cf. option “LDLT_SP” de “GCPC”/”PETSC”).
Dans la première partie du document nous résumons la problématique générale de résolution de systèmes linéaires, puis nous abordons les grandes familles de solveurs directs creux et leurs déclinaisons dans les bibliothèques du domaine public.
Toutes choses qu’il faut avoir à l’esprit avant d’aborder, dans la seconde partie , le package MUMPS au travers de ses principales caractéristiques et de ses fonctionnalités avancées. Puis nous détaillons les aspects numériques, informatiques et fonctionnels de son intégration dans Code_Aster . Enfin, nous concluons par quelques résultats numériques.
Pour plus de détails et de conseils sur l’emploi des solveurs linéaires on pourra consulter les notices d’utilisation spécifiques [U4.50.01]/[U2.08.03]. Les problématiques connexes d’amélioration des performances (RAM/CPU) d’un calcul et, de l’utilisation du parallélisme, font aussi l’objet de notices détaillées: [U1.03.03] et [U2.08.06].
Le package MUMPS#
Historique#
Le package MUMPS implémente une multifrontale «massivement» parallèle (‘ MUltifrontal Massively Parallel sparse direct Solver ’[Mum]) mise au point durant le Projet européen PARASOL (1996-1999) par les équipes de trois laboratoires: CERFACS, ENSEEIHT-IRIT et RAL (I.S.Duff, P.R.Amestoy, J.Koster et J.Y.L’Excellent…).
Depuis cette version finalisée (MUMPS 4.04 22/09/99) et public (libre de droit), une quarantaine d’autres versions ont été livrées. Ces développements corrigent des anomalies, étendent le périmètre d’utilisation, améliorent l’ergonomie et surtout, enrichissent les fonctionnalités. MUMPS est donc un produit pérenne, développé et maintenu par une dizaine de personnes appartenant à des entités académiques réparties entre Bordeaux, Lyon et Toulouse: IRIT, CNRS, CERFACS, INRIA/ENS Lyonet Université de Bordeaux I.


Figure 2.1-1._ Logos des principaux contributeurs à MUMPS [Mum].
Le produit est public et téléchargeable sur son site web: http://graal.ens-lyon.fr/MUMPS . On recense environ 1000 utilisateurs directs (dont 1/3 Europe + 1/3 USA) sans compter ceux qui l’utilisent via les librairies qui le référence: PETSc, TRILINOS, Matlab et Scilab… Son site propose de la documentation (théorique et d’utilisation), des liens, des exemples d’application, ainsi qu’un forum de discussion (en anglais) traçant le retour d’expérience sur le produit (bugs, problèmes d’installation, conseils…).
Chaque année une dizaine de travaux algorithmiques/informatiques aboutissent à des améliorations du package (thèse, post-doc, travaux de recherche…). D’autre part il est utilisé régulièrement pour des études industrielles (EADS, CEA, BOEING, GéoSciences Azur, SAMTECH, Code_Aster… ).
Figure 2.1-2._ La page d’accueil du site web de MUMPS [Mum].
Depuis 2015, un consortium entre équipes académiques, industriels et éditeurs de logiciels s’est monté autour du produit : le consortium MUMPS[MUC]. Il doit permettre de mieux assurer son développement, sa diffusion et sa pérennité.
Il géré par l’INRIA et regroupe fin 2015: EDF, ALTAIR, MICHELIN, LSTC, SIEMENS, ESI, TOTAL (membres) et CERFACS, INPT, INRIA, ENS Lyon et Université de Bordeaux (membres fondateurs).
Figure 2.1-3._ La page d’accueil du site web dédié au consortium[MUC].
Principales caractéristiques#
MUMPS implémente une multifrontale [ADE00][ADKE01][AGES06] effectuant une factorisation \(LU\) ou \(LD{L}^{T}\) (cf. §1.4). Ses principales caractéristiques sont:
Large périmètre d’utilisation : SPD, symétrique quelconque, non symétrique, réel/complexe, simple/double précision, matrice régulière/singulière(tout ce périmètre est exploité dans Code_Aster );
Admet trois modes de distribution des données : par élément, centralisé ou distribué (les deux derniers modes sont exploités dans Code_Aster );
Interfaçage en Fortran (exploité), C, matlab et scilab.
Paramétrage par défaut et possibilité de laisser le package choisir certaines de ses options en fonction du type de problème, de sa nature et du nombre de processeurs (exploité).
Modularité (3 phases distinctes interchangeables cf. §1.5 et figure 2.2.1) et ouverture de certaines arcanes numériques de MUMPS. L’utilisateur (très) avancé peut ainsi sortir du produit le résultat de certains prétraitements (scaling, pivotage, renumérotation), les modifier ou les remplacer par d’autres et les réinsérer dans la chaîne de calculs propre à l’outil;
Différentes stratégies de résolutions : multiples seconds membres, résolutions simultanées et compléments de Schur (seules les deux premières sont exploitées);
Différents renuméroteurs embarqués ou externes: (PAR)METIS, AMD, QAMD, AMF, PORD, (PT)SCOTCH, ‘fourni par l’utilisateur’ (exploités sauf le dernier);
Fonctionnalités connexes : détection de petits pivots/calcul de rang (exploités), calcul de noyaux (bientôt exploité), analyse d’erreur et amélioration de la solution (exploitée), calcul du critère d’inertie pour le test Sturm en calcul modal (exploité), compression low-rank (exploitée); usage du caractère creux du second membre et résolution simultanées de plusieurs systèmes linéaires (pas exploité), calcul de quelques termes de l’inverse (pas exploité), procédure de rédémarrage (pas encore exploité), manipulation des entiers longs (pas encore exploité)?
Pré et post-traitements : mise à l’échelle, permutation ligne/colonne et scalaire/bloc 2x2, raffinement itératif (exploités);
Parallélisme : potentiellement à 2 niveaux (MPI+OpenMP), gestion asynchrone des flots de tâches/données et leur réordonnancement dynamique, recouvrement calcul/communication; Distribution des données associée à la distribution des tâches; Ce parallélisme ne commence qu’au niveau de la phase de factorisation, sauf si l’un des renuméroteurs parallèles (PARMETIS ou PTSCOTCH) a été choisis.
Mémoire : déchargement sur disque ou non de la factorisée (modes In-Core ou Out-Of-Core) avec estimation préalable des consommations RAM par processeur dans les deux cas (exploité).
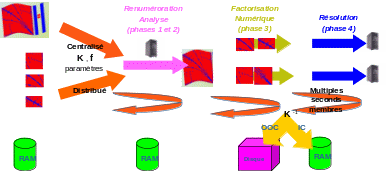
Figure 2.2-1._ Organigramme fonctionnel de MUMPS: ses trois étapes en parallèle centralisé/distribué et IC/OOC.
Remarque:
En terme de parallélisme, MUMPS exploite deux niveaux (cf. [R6.01.03] §2.6.1): l’un externe lié à l’élimination concurrente de fronts (via MPI), l’autre interne, au sein de chaque front (via des BLAS «threadées» ou autour des algorithmes de compression low-rank).
La méthode multifrontale native de Code_Aster n’exploite que le second niveau et en parallélisme à mémoire partagée (via OpenMP). Donc sans recouvrement, réordonnancement dynamique et distribution des données entre les processeurs. Par contre, par ses connections fines avec Code_Aster, elle exploite toutes les facilités du gestionnaire mémoire JEVEUX(OOC, redémarrage, diagnostic…) et les spécificités de modélisation du code (éléments de structures, Lagranges).
Zooms sur quelques points techniques#
Pivotage#
La technique de pivotage consiste à choisir un terme \({\tilde{A}}_{k}(k,k)\) adapté (dans la formule 1.4-3) pour éviter de diviser par un terme trop petit (ce qui amplifierait la propagation des erreurs d’arrondi lors du calcul des termes \({\tilde{A}}_{k+1}(i,j)\) suivants). Pour ce faire, on permute des lignes (pivotage partiel) et/ou des colonnes (resp. total) pour trouver le dénominateur de (1.4-3) adapté. Par exemple, dans le cas d’un pivotage partiel, on choisit comme «pivot» le terme \({\tilde{A}}_{k}(r,k)\) tel que
\({\tilde{\mathrm{A}}}_{k}(r,k)\ge u\underset{i}{\max}\mid {\tilde{\mathrm{A}}}_{k}(i,k)\mid \text{avec}u\in ]0,1]\) (2.3-1)
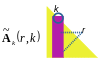
Figure 2.3-1._ Choix du pivot partiel à l’étape k.
D’où une amplification des erreurs d’arrondi au maximum de (\(1+\) )à cette étape. Ce qui est important ici ce n’est pas tant de choisir le terme le plus grand possible en valeur absolu ( u =1) que d’éviter de choisir le plus petit! L’inverse de ces pivots intervient aussi lors de la phase de descente-remontée, donc il faut ménager ces deux sources d’amplification d’erreurs en choisissant un u médian. MUMPS, comme beaucoup de package, propose par défaut u =0.01 (paramètre MUMPSCNTL(1)).
Pour pivoter on utilise généralement des termes diagonaux scalaires mais aussi des blocs de termes (des blocs diagonaux 2x2).
Dans MUMPS, deux types de pivotage sont mis en œuvre, l’un dit ‘statique’ (lors de la phase d’analyse), l’autre dit ‘numérique’ (resp. factorisation numérique). Ils sont paramétrables et activables séparément (cf. paramètres MUMPS CNTL(1), CNTL(4)et ICNTL(6)). Pour des matrices SPD ou à diagonale dominante, ces facultés de pivotage peuvent être désactivées sans risque (le calcul y gagnera en rapidité), par contre, dans les autres cas de figure, il faut les initialiser pour gérer les éventuels pivots très petits ou nuls. Cela implique en général un surcroît de remplissage de la factorisée mais accroît la stabilité numérique.
Remarques:
Cette fonctionnalité de pivotage rend MUMPS indispensable pour traiter certaines modélisations de Code_Aster (éléments quasi-incompressibles, formulations mixtes, X-FEM…). Du moins tant que d’autres solveurs directs incluant du pivotage ne seront pas disponibles dans le code.
L’utilisateur Aster n’a pas accès directement au paramétrage fin de ces facultés de pivotage. Elles sont activées avec les valeurs par défaut. Il peut juste les débrancher partiellement en posant SOLVEUR/PRETRAITEMENTS=’SANS’(par défaut=’AUTO’).
Le surcroît de remplissage du au pivotage numérique doit s’ordonnancer au plus tôt dans MUMPS (dès la phase d’analyse). Et ce, en prévoyant arbitrairement un pourcentage de surconsommation mémoire par rapport au profil prévu. Ce chiffre doit être renseigné en pourcents dans le paramètre MUMPS ICNTL(14)(accessible à l’utilisateur Aster via le mot-clé SOLVEUR/PCENT_PIVOT initialisé par défaut à 20%). Par la suite, si cette évaluation s’avère insuffisante, suivant le type de gestion mémoire choisie (mot-clé SOLVEUR/GESTION_MEMOIRE), soit le calcul s’arrête en ERREUR_FATALE, soit on retente plusieurs fois une factorisation numérique en doublant à chaque fois la taille de cet espace réservé au pivotage.
Certains produits restreignent leur périmètre/robustesse en ne proposant pas de stratégie de pivotage (SPRSBLKKT, MULT_FRONT_Aster…), d’autres se limitent à des pivots scalaires (CHOLMOD, PaStiX, TAUCS, WSMP…) ou proposent des stratégies particulières (méthode de perturbation+correction de Bunch-Kaufmann pour PARDISO, de Bunch-Parlett pour SPOOLES…).
Raffinement itératif#
En fin de résolution, ayant obtenu la solution \(u\) du problème, on peut évaluer facilement son résidu \(r:=\text{Ku}-f\) . Connaissant déjà la factorisée de la matrice, ce résidu peut alors alimenter à peu de frais le processus itératif d’amélioration suivant (dans le cas général non symétrique):
\(\begin{array}{c}\text{Boucle en}i\\ (1){\mathrm{r}}^{i}=\mathrm{f}-{\text{Ku}}^{i}\\ (2)\text{LU}\delta {\text{u}}^{i}={\mathrm{r}}^{i}\\ (3){\mathrm{u}}^{i+1}\mathrm{\Leftarrow }{\mathrm{u}}^{i}+\delta {\text{u}}^{i}\end{array}\) (2.3-2)
Ce processus est «indolore» [21]_ puisqu’il ne coûte principalement que le prix des descente-remontées de l’étape (2). Il peut ainsi s’itérer jusqu’à un certain seuil ou jusqu’à un nombre d’itérations maximum. Si le calcul de résidu ne comporte pas trop d’erreur d’arrondi, c’est-à-dire si l’algorithme de résolution est plutôt fiable (cf. paragraphe suivant) et que le conditionnement du système matriciel est bon, ce processus de raffinement itératif [22]_ est très bénéfique sur la qualité de la solution.
Dans MUMPS ce processus est activable ou non (paramètre ICNTL(10)<0) et borné par un nombre d’itérations maximum \({N}_{\mathit{err}}\) (ICNTL(10)). Le processus (2.3-2) se poursuit tant que le «résidu équilibré» \({B}_{\mathrm{err}}\) est supérieur à un seuil paramétrable seuil (CNTL(2), fixé par défaut à \(\sqrt{\varepsilon}\) avec \(\varepsilon\) précision machine)
\({\mathrm{B}}_{\text{err}}:=\underset{j}{\max}\frac{\mid {\mathrm{r}}_{j}^{i}\mid }{{(\mid \mathrm{K}\mid \mid {\mathrm{u}}^{i}\mid +\mid \mathrm{f}\mid )}_{j}}<\text{seuil}\) (2.3-3)
ou qu’il ne décroît pas d’un facteur au moins 5 (non paramétrable). En général, une ou deux itérations suffisent. Si ce n’est pas le cas, c’est souvent révélateur d’autres problèmes: mauvais conditionnement ou erreur inverse (cf. paragraphe suivant).
Remarques:
Pour l’utilisateur Code_Aster ces paramètres MUMPS ne sont pas directement accessibles. La fonctionnalité est activable ou non via le mot-clé POSTTRAITEMENTS.
Cette fonctionnalité est présente dans de nombreux packages: Oblio, PARDISO, UFMPACK, WSMP…
Fiabilité des calculs#
Pour estimer la qualité de la solution d’un système linéaire[ADD89][Hig02], MUMPS propose des outils numériques déduits de la théorie de l’analyse inverse des erreurs d’arrondi initiée par Wilkinson (1960). Dans cette théorie, les erreurs d’arrondi dues à plusieurs facteurs (troncature, opération en arithmétique finie..) sont assimilées à des perturbations sur les données initiales. Cela permet de les comparer à d’autres sources d’erreurs (mesure, discrétisation…) et de les manipuler plus facilement via trois indicateurs obtenus en post-traitement:
Le conditionnement \(\mathrm{cond}(K,f)\) : il mesure la sensibilité du problème aux données (problème instable, mal formulé/discrétisé…). C’est-à-dire, le facteur multiplicatif que la manipulation des données va opérer sur le résultat. Pour l’améliorer, on peut essayer de changer la formulation du problème ou d’équilibrer les termes de la matrice, en dehors de MUMPS ou via MUMPS (SOLVEUR/PRETRAITEMENTS=’OUI’ dans Code_Aster ).
L’erreur inverse \(\mathrm{be}(K,f)\) (‘backward error’): elle mesure la propension de l’algorithme de résolution à transmettre/amplifier les erreurs d’arrondi . Un outil est dit «fiable» lorsque ce chiffre est proche de la précision machine. Pour l’améliorer, on peut essayer de changer d’algorithme de résolution ou de modifier une ou plusieurs de ses étapes (dans Code_Aster on peut jouer sur les paramètres SOLVEUR/TYPE_RESOL, PRETRAITEMENTS et RENUM).
L’erreur directe \(\mathrm{fe}(K,f)\) (‘forward error’): elle est le produit des deux chiffres précédents et fournit un majorant de l’erreur relative sur la solution .
\(\frac{\parallel \delta \text{u}\parallel }{\parallel u\parallel }<\underset{\text{fe}(K,f)}{\underset{\underbrace{}}{\text{cond}(K,f)\times \text{be}(K,f)}}\) (2.3-4)
On peut donner une représentation graphique (cf. figure 2.3-2) de ces notions en exprimant l’erreur inverse comme l’écart entre «les données initiales et les données perturbées», tandis que l’erreur directe mesure l’écart entre «la solution exacte et la solution réellement obtenue» (celle du problème perturbé par les erreurs d’arrondi).
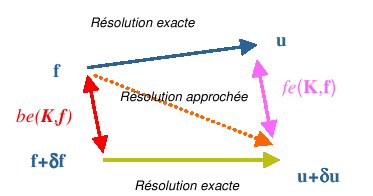
Figure 2.3-2._ Représentation graphique de la notion d’erreurs directe et inverse.
Dans le cadre des systèmes linéaires, l’erreur inverse se mesure via le résidu équilibré
\(\text{be}(K,f):=\underset{j\in J}{\max}\frac{{\mid f-\text{Ku}\mid }_{j}}{{(\mid K\mid \mid u\mid +\mid f\mid )}_{j}}\) (2.3-5)
On ne peut pas toujours l’évaluer sur tous les indices (\(J\ne {\left[1,N\right]}_{{\rm N}}\) ). En particulier lorsque le dénominateur est très petit (et le numérateur non nul), on lui préfère la formulation (avec \({J}^{\text{*}}\) tel que \(J\cup {J}^{\text{*}}={\left[1,N\right]}_{{\rm N}}\) )
\({\text{be}}^{\text{*}}(\mathrm{K},\mathrm{f}):=\underset{j\in {J}^{\text{*}}}{\max}\frac{{\mid \mathrm{f}-\text{Ku}\mid }_{j}}{{(\mid \mathrm{K}\mid \mid \mathrm{u}\mid )}_{j}+{\mathrm{\parallel }{\mathrm{K}}_{j.}\mathrm{\parallel }}_{\infty}{\mathrm{\parallel }\mathrm{u}\mathrm{\parallel }}_{\infty}}\) (2.3-6)
où \({K}_{j}\) . représente la \({j}^{\mathrm{ième}}\) ligne de la matrice \(K\) . A ces deux indicateurs, on associe deux estimations du conditionnement matricel (l’un lié aux lignes retenues dans l’ensemble \(J\) et l’autre à son complémentaire \({J}^{\text{*}}\) ): \(\mathrm{cond}(K,f)\) et \({\mathrm{cond}}^{\text{*}}(K,f)\) .La théorie nous fournit alors les résultats suivant:
La solution approchée uest la solution exacte du problème perturbé
\(\begin{array}{c}(\mathrm{K}+\delta \mathrm{K})\mathrm{u}=(\mathrm{f}+\delta \mathrm{f})\\ \text{avec}\delta {\mathrm{K}}_{ij}\le \max(\text{be},{\text{be}}^{\text{*}})\mid {\mathrm{K}}_{ij}\mid \\ \text{et}\delta {\mathrm{f}}_{i}\le \max(\text{be}.\mid {\mathrm{f}}_{i}\mid ,{\text{be}}^{\text{*}}.{\mathrm{\parallel }{\mathrm{K}}_{i.}\mathrm{\parallel }}_{\infty}{\mathrm{\parallel }\mathrm{u}\mathrm{\parallel }}_{\infty})\end{array}\) (2.3-7)
On a la majoration suivante ( via l’erreur directe \(\mathrm{fe}(K,f)\) ) sur l’erreur relative en solution
\(\frac{\parallel \delta \text{u}\parallel }{\parallel u\parallel }<\underset{\text{fe}(K,f)}{\underset{\underbrace{}}{\text{cond}\times \text{be}+{\text{cond}}^{\text{*}}\times {\text{be}}^{\text{*}}}}\) (2.3-8)
En pratique, on scrute surtout cette dernière estimation \(\mathrm{fe}(K,f)\) et ses composantes. Son ordre de grandeur indique grosso modo le nombre de décimales «vraies» de la solution calculées. Pour les problèmes mal conditionnés, une tolérance de \({10}^{\text{-3}}\) n’est pas rare, mais elle doit être prise au sérieux car ce type de pathologie peut sérieusement perturber un calcul.
Même dans le cadre très précis de la résolution de système linéaire, il existe de nombreuses façons de définir la sensibilité aux erreurs d’arrondis du problème considéré (c’est-à-dire son conditionnement). Celle retenue par MUMPS et, qui fait référence dans le domaine (cf. Arioli, Demmel et Duff 1989), est indissociable de la “backward error” du problème. La définition de l’un n’a pas de sens sans celle de l’autre. Il ne faut donc pas confondre ce type de conditionnement avec la notion de conditionnement matriciel classique.
D’autre part, le conditionnement fourni pas MUMPS prend en compte le SECOND MEMBRE du système ainsi que le CARACTERE CREUX de la matrice . En effet, ce n’est pas la peine de tenir compte d’éventuelles erreurs d’arrondis sur des termes matriciels nuls et donc non fournis au solveur ! Les degrés de liberté correspondant ne «se parlent pas» (vu de la lorgnette élément fini). Ainsi, ce conditionnement MUMPS respecte la physique du problème discrétisé. Il ne replonge pas le problème dans l’espace trop riche des matrices pleines.
Ainsi, le chiffre de conditionnement affiché par MUMPS est beaucoup moins pessimiste que le calcul standard que peut fournir un autre produit (Matlab, Python…). Mais martelons, que ce n’est que son produit avec la “backward error”, appelée “forward error”, qui a un intérêt. Et uniquement, dans le cadre d’une résolution de système linéaire via MUMPS.
Remarques:
Cette analyse de la qualité de la solution n’est pas limitée aux solveurs linéaires. Elle se décline aussi, par exemple, pour les solveurs modaux[Hig02].
Dans MUMPS, les estimateurs \(\mathrm{fe},\mathrm{be},{\mathrm{be}}^{\text{*}}\) , \(\mathrm{cond}\) et \({\mathrm{cond}}^{\text{*}}\) sont accessibles via, respectivement, les variables RINFO(9/7/8/10et 11). Ces post-traitements sont un peu coûteux (~jusqu’à 10% du temps calcul) et donc désactivables (via ICNTL(11)).
Pour l’utilisateur Code_Aster ces paramètres MUMPS ne sont pas directement accessibles. Ils sont affichés dans un encart spécifique du fichier de message (libellé «monitoring MUMPS») si on renseigne le mot-clé INFO=2dans l’opérateur. D’autre part, cette fonctionnalité n’est activée que si il choisit d’estimer et de tester la qualité de sa solution via le paramètre SOLVEUR/RESI_RELA. Suivant les opérateurs Aster, ce paramètre est par défaut débranché (valeur négative) ou fixé à 10-6. Lorsqu’il est activé (valeur positive), on teste si l’erreur directe \(\mathit{fe}(\mathrm{K},\mathrm{f})\) est bien inférieure à RESI_RELA. Si cela n’est pas le cas, le calcul s’arrête en ERREUR_FATALE en précisant la nature du problème et les valeurs incriminées.
L’activation de cette fonctionnalité n’est pas indispensable (mais souvent utile) lorsque la solution recherchée est elle-même corrigée par un autre processus algorithmique (algorithme de Newton, schéma de Newmark): bref, dans les opérateurs linéaires THER_LINEAIRE, MECA_STATIQUE, STAT_NON_LINE, DYNA_NON_LINE…
Ce type de fonctionnalité semble peu présent dans les librairies: LAPACK, Nag, HSL…
Gestion mémoire (In-Core versus Out-Of-Core)#
On a vu que l’inconvénient majeur (cf. §1.7) des méthodes directes réside dans la taille de la factorisée. Pour permettre de passer en mémoire vive des systèmes plus grands, MUMPS propose de décharger cet objet sur disque : c’est le mode Out-Of-Core (mot-clé GESTION_MEMOIRE=”OUT_OF_CORE”) par opposition au mode In-Core (mot-clé GESTION_MEMOIRE=”IN_CORE”) où toutes les structures de données résident en RAM (cf. figures 2.2-1 et 2.3-3). Ce mode d’économie de la RAM est complémentaire de la distribution de données qu’induit naturellement le parallélisme. La plus-value de l’OOC est donc surtout prégnante pour des nombres de processeurs modérés (<32 processeurs).
D’autre part, l’équipe MUMPS a été très attentive au surcoût CPU engendré par cette pratique. En retravaillant dans l’algorithmique du code les manipulations des entités déchargées, ils ont pu limiter au strict minimum ces surcoûts (quelques pourcents et surtout dans la phase de résolution).
Figure 2.3-3._ Deux types de gestion mémoire standards:entièrement en RAM ( “IN_CORE” ) et RAM/disque (” OUT_OF_CORE” ).
Ces deux modes de gestion mémoire sont «sans filet» . Aucune correction ne sera opérée ultérieurement en cas de problème. Si on ne sait a priori pas lesquels de ces deux modes choisir et si on veux limiter, autant que faire se peut, les problèmes dus à des défauts de place mémoire, on peut choisir le mode automatique: GESTION_MEMOIRE=”AUTO”. Des heuristiques internes à Code_Aster gèrent alors toutes seules les contingences mémoire de MUMPS en fonction de la configuration informatique (machine, parallélisme) et des difficultés numériques du problème.
Dans le même ordre d’idée, une option du même mot-clé, GESTION_MEMOIRE=”EVAL”, permet de calibrer les besoins d’un calcul en affichant dans le fichier message les ressources mémoires requises par le calcul Code_Aster +MUMPS.
Taille du système linéaire: 500000
Mémoire RAM minimale consommée par Code_Aster : 200 Mo
Estimation de la mémoire Mumps avec GESTION_MEMOIRE=”IN_CORE” :3500 Mo
Estimation de la mémoire Mumps avec GESTION_MEMOIRE=”OUT_OF_CORE” : 500 Mo
Estimation de l’espace disque pour Mumps avec GESTION_MEMOIRE=”OUT_OF_CORE”:2000 Mo
===> Pour ce calcul, il faut donc une quantité de mémoire RAM au minimum de
3500 Mo si GESTION_MEMOIRE=”IN_CORE”,
500 Mo si GESTION_MEMOIRE=”OUT_OF_CORE” .
En cas de doute, utilisez GESTION_MEMOIRE=”AUTO”.
Figure 2.3-4._Extrait de fichier de message avec GESTION_MEMOIRE=”EVAL”.
Remarques:
Les paramètres MUMPS ICNTL(22)/ICNTL(23)permettent de gérer ces options mémoire. L’utilisateur Aster les active indirectement via le mot clé SOLVEUR/GESTION_MEMOIRE.
Le déchargement sur disque est entièrement contrôlé par MUMPS (nombre de fichiers, fréquence déchargement/rechargement…). On renseigne juste l’emplacement mémoire: c’est tout naturellement le répertoire de travail de l’exécutable Aster propre à chaque processeur (%OOC_TMPDIR=’.’). Ces fichiers sont automatiquement effacés par MUMPS lorsqu’on détruit l’occurrence MUMPS associée. Cela évite donc un engorgement du disque lorsque différents systèmes sont factorisés dans une même résolution.
D’autres stratégies d’OOC seraient envisageables voire sont déjà codées dans certains packages (PaStiX, Oblio, TAUCS…). On pense en particulier au fait de pouvoir moduler le périmètre des objets déchargés (cf. phase d’analyse parfois coûteuse en RAM) et de pouvoir les réutiliser sur disque lors d’une autre exécution (cf. POURSUITEau sens Aster ou factorisation partielle).
Gestion des matrices singulières#
Un des gros point fort du produit est sa gestion des singularités . Il est non seulement capable de détecter les singularités numériques [23]_ d’une matrice et d’en synthétiser l’information pour un usage externe (calcul de rang, avertissement à l’utilisateur, affichage d’expertise..), mais en plus, malgré cette difficulté, il calcule une solution «régulière [24]_ » voire tout ou partie du noyau associé .
Ces nouveaux développements étaient un des livrables de l’ANR SOLSTICE[SOL]. Nous les avions demandés à l’équipe MUMPS (en partenariat avec l’équipe Algo du CERFACS) pour rendre ce produit iso-fonctionnel par rapport aux autres solveurs directs de Code_Aster .
Et en pratique, comment MUMPS procède t’il?
A gros traits , lors de la construction de la matrice factorisée, il détecte les lignes comportant des pivots [25]_ très petits (par rapport au un critère CNTL(3) [26]_ ). Il les répertorie dans le vecteur PIVNUL_LIST(1:INFOG(28)) et, suivant le cas de figure, soit il les remplace par une valeur pré-fixée ( via CNTL(5) [27]_ ), soit il les stocke à part. Le bloc ainsi constitué (de plus petite taille) subira ultérieurement un algorithme QR ad hoc .
Et pour finir , les itérations de raffinement itératifs viennent compléter cet écheveau. Comme elles n’utilisent cette factorisée «retouchée» uniquement que comme préconditionneur, et qu’elles bénéficient, par contre, de l’information exacte du produit matrice-vecteur, elles ramènent [28]_ la solution «biaisée» dans le bon chemin!
Remarques:
Les paramètres MUMPS ICNTL(13)/ICNTL(24)/ICNTL(25)et CNTL(3)/CNTL(5)permettent d’activer ces fonctionnalités. Ils ne sont pas modifiables par l’utilisateur. Par prudence, on garde la fonctionnalité activée en permanence.
Cette fonctionnalité peut aussi s’avérer utile en calcul modal (filtrage des modes rigides).
Compression “Block Low-Rank” (BLR)#
Cette technique de compression vise à faciliter les grosses études en réduisant leurs coûts en temps et en mémoire. Elle est complémentaire du parallélisme et de la panoplie algorithmique/fonctionnelle du produit *. Son périmètre d’utilisation est quasi-complet.* On n’a pas à choisir entre le parallélisme, tel ou tel raffinement numérique et ces compressions BLR! Toutes ces fonctionnalités sont compatibles et leurs gains souvent se cumulent [29]_ .
A la manière des formats mp3, zip ou pdf de nos usages domestiques et bureautiques, ces compressions permettent de réduire, avec peu de pertes, les étapes coûteuses de MUMPS [30]_ . Et cette approximation ne perturbe généralement pas la précision et le comportement des calculs mécaniques englobants.
Elle n’est cependant intéressante que sur des problèmes de grandes tailles (N au moins > 2.106ddls ). Car comme ces compressions impliquent un surcoût, il ne faut comprimer que les blocs de données suffisamment grands et donc susceptibles de compenser rapidement ce surcoût.
Les gains constatés sur quelques études Code_Aster varient de 20% à 80% (cf. figures 7.3-5/7.3-6). Ils augmentent avec la taille du problème et son caractère massif.
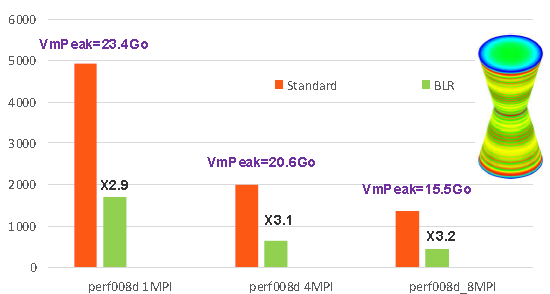
Figure 7.3-5: Exemple de gains procurés par les compressions low-rank sur le cas test de performance perf008d (paramètres par défaut, gestion mémoire en OOC, N=2M, NNZ=80M, Facto_METIS4=7495M, conditionnement=10 7 ). On trace, en fonction du nombre de processus MPI activés, les temps elapsed consommés par toute l’étape de résolution de système linéaire dans Code_Aster v13.1, son pic mémoire RAM, ainsi que le facteur d’accélération procuré par BLR.
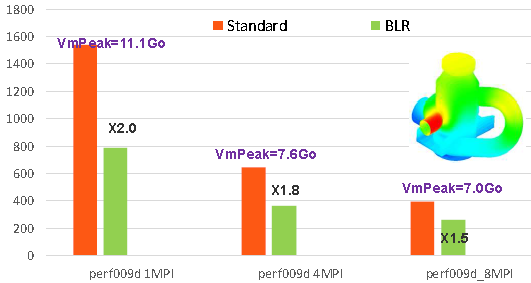
Figure 7.3-6: Exemple de gains procurés par les compressions low-rank sur le cas test de performance perf009d (paramètres par défaut, gestion mémoire en OOC, N=5.4M, NNZ=209M, Facto_METIS4=5247M, conditionnement=10 8 ). On trace, en fonction du nombre de processus MPI activés, les temps elapsed consommés par toute l’étape de résolution de système linéaire dans Code_Aster v13.1, son pic mémoire RAM, ainsi que le facteur d’accélération procuré par BLR.
A grands traits , cette stratégie cherche à compresser les gros blocs de données les plus manipulés par la multifrontale de MUMPS: les gros blocs denses de son arbre d’élimination . Cette technique repose sur l’hypothèse (souvent vérifiée empiriquement) qu’il est possible de renuméroter [31]_ les variables au sein de ces blocs denses afin de dégager une structure matricielle plus avantageuse: décomposer ces blocs comme produit de deux matrices denses beaucoup plus petites .
L’objectif est donc de décomposer les grosses matrices denses A (de cette arbre d’élimination), par exemple de taille m x n , sous la forme

(7.3-9)
avec U et V des matrices beaucoup plus petites (respectivement m x k et k x n avec k <min(m,n) ) et E une matrice m x n «négligeable» (

).
Lors des manipulations ultérieures MUMPS fait alors l’approximation

(7.3-10)
en pariant que celle-ci aura peu d’impact sur la qualité du résultat (grâce au raffinement itératif ou aux algorithmes non linéaires englobants) et sur les “outputs” connexes du solveur (détection de singularité, calcul de déterminant, critère de Sturm).
Et c’est la plupart du temps vérifié tant que le paramètre de compression est assez petit (e<10-9). Si celui est plus grand, l’approximation ne peut plus être négligée et MUMPS ne peut plus être utilisé en tant que solveur direct «exacte»: seulement en tant que solveur direct «relaxé» (en non linéaire) ou en tant que préconditionneur (par exemple pour le GCPC de Code_Aster out les solveurs de Krylov de PETSc).
Cette fonctionnalité maintenant disponible dans l es versions consortium du produit résulte d’un partenariat EDF-INPT (2010-13) autour de la travaux de thèse de C.Weisbecker [CW13/15]. Celle-ci a été récompensée par un des prix L.Escande de l’année 2014. Pour plus de détails sur les aspects techniques de ces travaux on pourra consulter le document de thèse proprement dit ou le résumé fourni à l’annexe n°1 de ce document.
Remarque:
Suivant les versions de MUMPS, différents paramètres permettent de gérer cette stratégie de compression. L’utilisateur Code_Aster les active indirectement via les mots-clés ACCELERATION/LOW_RANK_SEUIL.
Implantation dans Code_Aster#
Contexte/synthèse#
Pour améliorer les performances des calculs réalisés, la stratégie retenue par Code_Aster [Dur08], comme par la plupart des grands codes généralistes en mécanique des structures, consiste notamment à diversifier son panel de solveurs linéaires [32]_ afin de mieux cibler les besoins et les contraintes des utilisateurs: machine locale, cluster ou centre de calcul; encombrement mémoire et disque; temps CPU; étude industrielle ou plus exploratoire…
Coté parallélisme et solveur linéaire, une voie est particulièrement prospectée [33]_ :
le « parallélisme numérique » de librairies de solveurs externes tellesque MUMPS et PETSc, éventuellement complété par un «parallélisme informatique» (interne au code) pour les calculs élémentaires et les assemblages matriciels/vectoriels;
Nous nous intéressons ici au premier scénario au travers de MUMPS. Ce solveur externe est «plugé» dans Code_Asteret accessible aux utilisateurs depuis la v8.0.14 . Il nous permet ainsi de bénéficier, «à moindre frais», du Rex d’une large communauté d’utilisateurs et des compétences très pointues d’équipes internationales. Le tout en conjuguant efficacité, performance, fiabilité et large périmètre d’utilisation.
Ce travail a d’abord été réalisé en exploitant le mode séquentiel In-Core du produit. En particulier, grâce à ses facultés de pivotage, il rend de précieux services en traitant de nouvelles modélisations (éléments quasi-incompressibles, X-FEM…) qui peuvent s’avérer problématiques pour les autres solveurs linéaires.
Depuis, MUMPS est quotidiennement utilisé sur des études [GM08][Tar07][GS11]. Notre Rex s’est bien sûr étoffé et nous entretenons une relation partenariale active avec l’équipe de développement de MUMPS (notamment via l’ANR SOLSTICE[SOL] et une thèse en cours). D’autre part, son intégration dans Code_Aster bénéficie d’un enrichissement continu: parallélisme centralisé IC[Des07] (depuis la v9.1.13), parallélisme distribué IC[Boi07] (depuis la v9.1.16) puis mode IC et OOC[BD08] (depuis la v9.3.14).
En mode parallèle distribué, l’usage de MUMPS procure des gains en CPU (par rapport à la méthode par défaut du code) de l’ordre de la douzaine sur 32 processeurs de la machine Aster . Sur des cas très favorables ce résultat peut être bien meilleur et, pour des «études frontières», MUMPS reste parfois la seule alternative viable (cf. internes de cuve [Boi07]).
Quant aux consommations RAM, on a vu aux chapitres précédents que c’est la principale faiblesse des solveurs directs. Même en mode parallèle, où l’on a pourtant naturellement une distribution des données entre les processeurs, ce facteur peut s’avérer handicapant. Pour surmonter ce problème il possible d’activer dans Code_Aster , une fonctionnalité récente de MUMPS (développée dans le cadre de l’ANR pré-citée): l’«Out-Of-Core» (OOC), pendant du «In-Core» (IC) par défaut. Elle permet de réduire ce goulot d’étranglement en déchargeant sur disque bon nombre de données. Grâce à l’OOC, on peut ainsi s’approcher des consommations RAM de la multifrontale native de Code_Aster (même en séquentiel), voire descendre en dessous en conjuguant les efforts du parallélisme et de ce déchargement sur disque. Les premiers essais montrent un gain en RAM entre l’OOC et l’IC d’au moins 50% (voire plus sur des cas favorables) pour un surcoût en CPU limité (<10%).
Le solveur MUMPS permet donc, non seulement de résoudre des problèmes numériquement difficiles, mais, inséré dans un processus de calcul Aster déjà partiellement parallèle, il en démultiplie les performances. Il procure au code un cadre parallèle performant, générique, robuste et grand public. Il facilite ainsi le passage des études standards (< million de degrés de liberté) et rend accessible au plus grand nombre le traitement de gros cas (~ plusieurs millions de degrés de liberté).
Deux types de parallélisme: centralisé et distribué#
Principe#
MUMPS est un solveur linéaire parallélisé. Ce parallélisme peut être activé de plusieurs manières notamment suivant les aspects séquentiels ou parallèles du code qui l’utilise. Ainsi, ce parallélisme peut être limité aux flots de données/traitements internes à MUMPS , ou, a contrario s’intégrer à un flot de données/traitements parallèles déjà organisés en amont du solveur , dès les phases de calculs élémentaires de Code_Aster . Le premier mode (‘CENTRALISE’) a pour lui la robustesse et un plus large périmètre d’utilisation, le second (‘GROUP_ELEM’/”MAIL_***” et ‘SOUS_DOMAINE’) est moins générique mais plus efficace.
Car les phases souvent les plus coûteuses en temps CPU d’une simulation sont: la construction du système linéaire (purement Code_Aster , découpée en trois postes: factorisation symbolique, calculs élémentaires et assemblages matriciels/vectoriels) et sa résolution (dans MUMPS, cf. §1.6: renumérotation + analyse, factorisation numérique et descente-remontée). Le premier mode de parallélisation ne profite que du parallélisme des étapes 2 et 3 de MUMPS, alors que les trois autres parallélisent aussi les calculs élémentaires et les assemblages de Code_Aster ( cf. figure 2.2-1 et 3.2-1 ) .
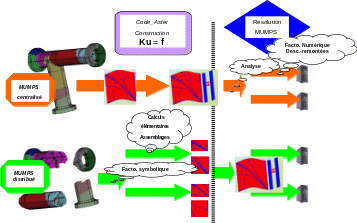
Figure 3.2-1._ Flots de données/traitements parallèles de MUMPS centralisé/distribué.
Différents modes de distribution#
On décrit dans ce paragraphe les différents choix de distribution des calculs élémentaires aux processeurs participant au calcul. Cette distribution se paramètre lors de la construction du modèle élément fini.
Un premier choix consiste à ne pas répartir les calculs élémentaires entre processeurs. Si l’on souhaite distribuer les calculs élémentaires, on peut s’appuyer sur une répartition des éléments finis ou bien une répartition des mailles (indépendamment des éléments finis portés par ces mailles) . On peut enfin combiner répartition par élément fini et par maille. Détaillons chaque mode:
CENTRALISE: Les mailles ne sont pas distribuées (comme en séquentiel). Les calculs élémentaires ne sont pas parallélisés. Le parallélisme ne commence qu’au niveau de MUMPS. Chaque processeurconstruit et fournit au solveur linéaire l’intégralité du système à résoudre. Ce mode d’utilisation est utile pour les tests de non-régression. Dans tous les cas de figure où les calculs élémentaires représentent une faible part du temps total (par ex. en élasticité linéaire), cette option peut être suffisante.
“ GROUP_ELEM”: Un second type de répartition consiste à constituer des groupes homogènes d’éléments finis (par type d’élément fini) puis à distribuer les calculs élémentaires entre les processeurs pour équilibrer au mieux la charge (en terme de nombre de calculs élémentaires de chaque type). Chaque processeur alloue la matrice entière mais n’effectue et n’assemble que les calculs élémentaires qui lui ont été attribués.
“MAIL_DISPERSE/MAIL_CONTIGU’ :
On effectue une distribution des mailles du modèle soit par paquets de mailles contiguës (‘MAIL_CONTIGU’), soit par distribution cyclique (‘MAIL_DISPERSE’). Cette distribution est indépendante du type d’élément fini porté par les mailles. Par exemple, avec un modèle comportant 8 mailles et pour un calcul sur 4 processeurs, on a les répartitions de charge suivantes:
Mode de distribution |
Maille 1 |
Maille 2 |
Maille 3 |
Maille 4 |
Maille 5 |
Maille 6 |
Maille 7 |
Maille 8 |
MAIL_CONTIGU |
Proc. 0 |
Proc. 0 |
Proc. 1 |
Proc. 1 |
Proc. 2 |
Proc. 2 |
Proc. 3 |
Proc. 3 |
MAIL_DISPERSE |
Proc. 0 |
Proc. 1 |
Proc. 2 |
Proc. 3 |
Proc. 0 |
Proc. 1 |
Proc. 2 |
Proc. 3 |
Chaque processeur alloue la matrice entière mais n’effectue et n’assemble que les calculs élémentaires qui lui ont été attribués.
“SOUS_DOMAINE”(défaut) : Ce type de distributionest une distribution hybride des calculs élémentaires qui s’appuie sur unerépartitiondesmailles (à partir d’un partitionnement du maillage global en sous-domaines) puis sur une répartition des éléments finis par type à l’intérieur de chaque sous-domaine. Chaque processeur alloue la matrice entière mais n’effectue et n’assemble que les calculs élémentaires qui lui ont été attribués.
Équilibrage de charge#
La distribution par mailles est très simple mais peut conduire à des déséquilibres de charge car elle ne tient pas explicitement compte des mailles spectatrices, des mailles de peau (cf. figure 3.2-2 sur un exemple comportant 8 mailles volumiques et 4 mailles de peau), de zones particulières (non linéarités…). La distribution par sous-domaines est plus souple et peut s’avérer plus efficace en permettant d’adapter son flot de données à sa simulation.
Une autre cause de déséquilibrage peut provenir des conditions de Dirichlet par dualisation (DDL_IMPO, LIAISON_*** …). Par soucis de robustesse, leur traitement est affecté seulement au processeur maître. Cette surcharge de travail, souvent négligeable, introduit cependant dans certains cas, un déséquilibrage plus marqué. L’utilisateur peut le compenser en renseignant un des mot-clés CHARGE_PROC0_MA/SD. Ce traitement différencié concerne en fait tous les cas de figures impliquant des mailles dites «tardives» (Dirichlet via des multiplicateurs de Lagrange mais aussi force nodale, contact méthode continue…).
Pour plus de détails sur les spécifications informatiques et les implications fonctionnelles de ce mode de parallélisme on pourra consulter les documentations [U2.08.03] et [U4.50.01].
Remarques:
Sans l’option MATR_DISTRIBUEE(cf. paragraphe suivant), les différente stratégies sont équivalentes en terme d’occupation mémoire. On tarit le plus tôt possible le flot de données et d’instructions. Il s’agit de traiter sélectivement des blocs matriciels/vectoriels du problème global, que MUMPS va rassembler.
En mode distribué, chaque processeur ne manipule que des matrices partiellement remplies. Par contre, afin d’éviter d’introduire trop de communications MPI dans le code (critères d’arrêt, résidu…), ce scénario n’a pas été retenu pour les seconds membres. Leur construction est bien parallélisé, mais en fin d’assemblage, les contributions de tous les processeurs sont sommées et envoyées à tous. Ainsi tous les processeurs connaissent entièrement les vecteurs impliqués dans le calcul.
De même, la matrice est pour l’instant dupliquée: dans l’espace JEVEUX (RAM ou disque) et dans l’espace F90 de MUMPS (RAM). A terme, du fait du déchargement sur disque de la factorisée, elle va devenir un objet dimensionnant de la RAM. Il faudra donc la construire directement via MUMPS.
Retailler les objets Code_Aster#
En mode parallèle, lorsqu’on distribue les données JEVEUX en amont de MUMPS, on ne redécoupe pas forcément les structures de données concernées. Avec l’option MATR_DISTRIBUEE=”NON”, tous les objets distribués sont alloués et initialisés à la même taille (la même valeur qu’en séquentiel). Par contre, chaque processeur ne va modifier que les parties d’objets JEVEUX dont il a la charge. Ce scénario est particulièrement adapté au mode parallèle distribué de MUMPS (mode par défaut) car ce produit regroupe en interne ces flots de données incomplets. Le parallélisme permet alors, outre des gains en temps calcul, de réduire la place mémoire requise par la résolution MUMPS mais pas celle nécessaire à la construction du problème dans JEVEUX.
Ceci n’est pas gênant tant que l’espace RAM pour JEVEUX reste très inférieur à celui requis par MUMPS. Comme JEVEUX stocke principalement la matrice et MUMPS, sa factorisée (généralement des dizaines de fois plus grosse), le goulet d’étranglement RAM du calcul est théoriquement sur MUMPS. Mais dès qu’on utilise quelques dizaines de processeurs en MPI et/ou qu’on active l’OOC, comme MUMPS distribue cette factorisée par processeur et décharge ces morceaux sur disque, la «balle revient dans le camp de JEVEUX».
D’où l’option MATR_DISTRIBUEE qui retaille la matrice, au plus juste des termes non nuls dont a la responsabilité le processeur. L’espace JEVEUX requis diminue alors avec le nombre de processeurs et descend en dessous de la RAM nécessaire à MUMPS. Les résultats de la figure 3.2-2 illustrent ce gain en parallèle sur deux études: une Pompe RIS et une modèle de cuve de l’étude «Epicure».
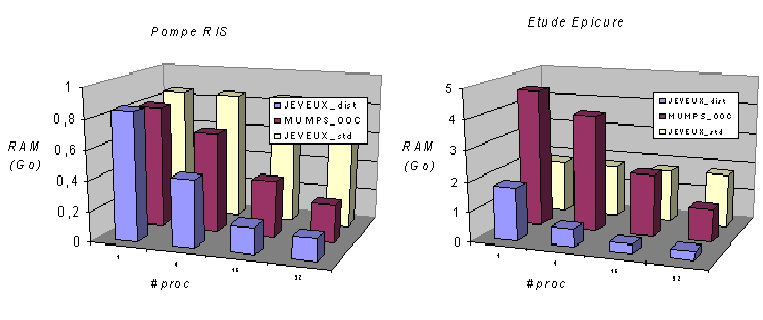
Figure 3.2-2._Evolution des consommations RAM (en Go) en fonction du nombre de processeurs, de Code_Aster v11.0 ( JEVEUX standard MATR_DISTRIBUE=”NON” et distribué, resp. “OUI” ) et de MUMPS OOC. Résultats effectués sur une Pompe RIS et sur la cuve de l’étude Epicure.
Remarques:
On traite iciles données résultant d’un calcul élémentaire (RESU_ELEM et CHAM_ELEM) ou d’un assemblage matriciel (MATR_ASSE). Les vecteurs assemblés (CHAM_NO) ne sont pas distribués car les gains mémoire induits seraient faibles et, d’autre part, comme ils interviennent dans l’évaluation de nombreux critères algorithmiques, cela impliquerait trop de communications supplémentaires.
En mode MATR_DISTRIBUE, pour faire la jointure entre le bout de MATR_ASSE local au processeur et la MATR_ASSE globale (que l’on ne construit pas), on rajoute un vecteur d’indirection sous la forme d’un NUME_DDLlocal.
Gestion de la mémoire MUMPS et Code_Aster#
Pour activer ou désactiver les facultés OOC de MUMPS (cf. figure 3.3-1) , l’utilisateur renseigne le mot-clé SOLVEUR/GESTION_MEMOIRE=’IN_CORE’/’OUT_OF_CORE’/”AUTO”(défaut). Cette fonctionnalité est bien sûr cumulable avec le parallélisme d’où une plus grande variété de fonctionnement pour éventuellement s’adapter aux contingences d’exécution: «séquentiel IC ou OOC», «parallélisme centralisé IC ou OCC», «parallélisme distribué par sous-domaines IC ou OOC»…
Pour un petit cas linéaire, le mode «séquentiel IC» suffit; pour un plus gros cas toujours en linéaire, le mode «parallèle centralisé IC» (ou mieux OOC) amène véritablement un gain en CPU et en RAM; en non linéaire, avec réactualisation fréquente de la matrice tangente, le mode «parallèle distribué OOC» est conseillé.
Pour plus de détails sur les spécifications informatiques et les implications fonctionnelles de ce mode de gestion de la mémoire MUMPS on pourra consulter les documentations [BD08] et [U2.08.03/U4.50.01].
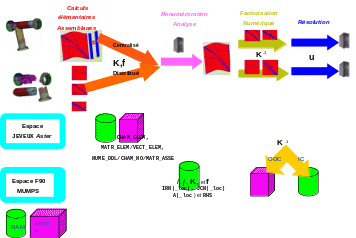
Figure 3.3-1._ Schémafonctionnel du couplage Code_Aster/MUMPS (avec une rénuméroteur séquentiel)
vis-à-vis des principales structures de données et de l’occupation mémoire (RAM et disque).
Gestion particulière des double multiplicateurs de Lagrange#
Historiquement, les solveurs linéaires directs de Code_Aster (‘MULT_FRONT’ et ‘LDLT’) ne disposaient pas d’algorithme de pivotage (qui cherche à éviter les accumulations d’erreurs d’arrondis par division par des termes très petits). Pour contourner ce problème, la prise en compte des conditions limites par des multiplicateurs de Lagrange (AFFE_CHAR_MECA/THER…) a été modifiées en introduisant des doubles-multiplicateurs de Lagrange. Formellement, on ne travaille pas avec la matrice initiale K 0
\({\mathrm{K}}_{0}=\left[\begin{array}{cc}\mathrm{K}& \mathrm{blocage}\\ \mathrm{blocage}& 0\end{array}\right]\begin{array}{c}\mathrm{u}\\ \mathrm{lagr}\end{array}\)
mais avec sa forme doublement dualisée K 2
\({\mathrm{K}}_{2}=\left[\begin{array}{ccc}\mathrm{K}& \mathrm{blocage}& \mathrm{blocage}\\ \mathrm{blocage}& -1& 1\\ \mathrm{blocage}& 1& -1\end{array}\right]\begin{array}{c}\mathrm{u}\\ {\mathrm{lagr}}_{1}\\ {\mathrm{lagr}}_{2}\end{array}\)
D’où un surcoût mémoire et calcul.
Comme MUMPS dispose de facultés de pivotage, ce choix de dualisation des conditions limites peut être remis en cause. En initialisant le mot-clé ELIM_LAGR à ‘LAGR2’, on ne tient plus compte que d’un Lagrange, l’autre étant spectateur [34]_ . D’où une matrice de travail \({K}_{1}\) simplement dualisée
\({\mathrm{K}}_{1}=\left[\begin{array}{ccc}\mathrm{K}& \mathrm{blocage}& 0\\ \mathrm{blocage}& 0& 0\\ 0& 0& -1\end{array}\right]\begin{array}{c}\mathrm{u}\\ {\mathrm{lagr}}_{1}\\ {\mathrm{lagr}}_{2}\end{array}\)
plus petite car les termes extra-diagonaux des lignes et des colonnes associées à ces multiplicateurs de Lagrange spectateurs sont alors initialisées à zéro. A contrario , avec la valeur ‘NON’, MUMPS reçoit les matrices dualisées usuelles.
Pour les problèmes comportant de nombreux multiplicateurs de Lagrange (jusqu’à 20% du nombres d’inconnues totales) , l’activation de ce paramètre est souvent payante (matrice plus petite). Mais lorsque ce nombre explose (>20%) , ce procédé peut-être contre-productif. Les gains réalisés sur la matrice sont annulés par la taille de la factorisée et surtout le nombre de pivotages tardifs que MUMPS doit effectuer. Imposer ELIM_LAGR=”NON” peut être alors très intéressant (gain de 40% en CPU sur le cas-test mac3c01).
Périmètre d’utilisation#
A priori , tous les opérateurs/fonctionnalités utilisant la résolution d’un système linéaire sauf une configuration de calcul modal [35]_ . Pour plus de détails on pourra consulter les documentations Utilisateur [U4.50.01].
Paramétrage et exemples d’utilisation#
Récapitulons le paramétrage principal permettant de piloter MUMPS dans Code_Aster et illustrons son utilisation via un cas-test officiel (mumps05b) et une géométrie d’étude (pompe RIS). Pour plus d’informations on pourra consulter les documentations Utilisateur associées [U2.08.03/U4.50.01], les notes EDF [BD08][Boi07][Des07] ou les cas-tests utilisant MUMPS.
Paramètres d’utilisation de MUMPS viaCode_Aster#
Opérande |
Mot-clé |
Valeur par défaut |
Détails/conseils |
Réf. |
SOLVEUR/ METHODE= ’MUMPS’ |
||||
Paramètres fonctionnels |
TYPE_RESOL |
‘AUTO’ (‘NONSYM’ si la matrice est non symétrique, ‘SYMGEN’sinon) |
‘AUTO’, ‘NONSYM’, ‘SYMGEN’et ‘SYMDEF’. Paramètre permettant de préciser la nature du problème à traiter. |
§1 |
PCENT_PIVOT |
10% |
Surcoût mémoire prévu pour les pivotages. |
§2.3 |
|
ELIM_LAGR |
‘LAGR2’ |
‘LAGR2’/’NON’. |
§3.4 |
|
RESI_RELA |
-1 (non linéaire) 10-6 (linéaire) |
Paramètre en lien avec le mot-clé POSTTRAITEMENTS. Si ce paramètre est positif, MUMPS effectue des itérations de raffinement itératif et examine la qualité de la solution. Si l’erreur relative en solution est inférieures à cette valeur, Aster s’arrête en ERREUR_FATALE. CAS PARTICULIER: POSTTRAITEMENTS=”MINI”. |
§2.3 |
|
Paramètres numériques |
PRETRAITEMENTS |
‘AUTO’ |
‘AUTO’et ‘SANS’. |
§1.6 §2.3 |
RENUM |
‘AUTO’ |
‘AUTO’, ’AMD’, ‘AMF’, ‘QAMD’, ‘PORD’, “(PT)SCOTCH’et ‘(PAR)METIS’. Dans le premier cas de figure MUMPS choisit le meilleur renuméroteur disponible, dans les autres, on lui impose. Si ce renuméroteur n’est pas disponible: ERREUR_FATALE ou ALARME et on le remplace par un autre du même type. |
§1.6 |
|
FILTRAGE_MATRICE/MIXER_PRECISION |
Options pour «relaxer» les résolutions effectuées via MUMPS. |
[U4.50.01] |
||
POSTTRAITEMENTS |
“AUTO” |
‘AUTO’, “MINI”, FORCE’et ‘SANS’. |
§2.3 |
|
ACCELERATION/LOW_RANK_SEUIL |
“AUTO”/0.0 |
Utile principalement sur de gros problèmes (N> 2.106ddls). Utiliser en complément POSTTRAITEMENTS=”MINI”. |
§2.3 et annexe n°1 |
|
Mémoire |
GESTION_MEMOIRE |
‘AUTO’ |
‘IN_CORE’, “OUT_OF_CORE”, “AUTO’ou ‘EVAL’. |
§3.3 |
MATR_DISTRIBUEE |
“NON” |
‘OUI’ou ‘NON’. |
§3.2 |
Tableau 3.6-1._ Récapitulatif du paramétrage spécifique de MUMPS dans Code_Aster.
Monitoring#
En positionnant le mot-clé INFOà 2 et en utilisant le solveur MUMPS , l’utilisateur peut faire afficher dans le fichier de message un monitoring synthétique des différentes phases de la construction et de la résolution du système linéaire: répartition par processeur du nombre de mailles, des termes de la matrice et de sa factorisée, l’analyse d’erreur (si demandée) et un bilan de leur éventuel déséquilibrage. A ce monitoring orienté CPU, on rajoute quelques informations sur les consommations RAM de MUMPS : par processeur, estimation (d’après la phase d’analyse) des besoins en RAM en IC, en OOC et la valeur effectivement utilisée avec rappel de la stratégie choisie par l’utilisateur.Les temps consommés pour chacune des étapes du calcul suivant les processeurs peuvent apparaître aussi. Ils sont gérés par un mécanisme plus global qui n’est pas spécifique à MUMPS (cf. §4.1.2 [U1.03.03] ou la documentation Utilisateur de l’opérateur DEBUT/POURSUITE).
<MONITORING MUMPS >
TAILLE DU SYSTEME 803352
CONDITIONNEMENT/ERREUR ALGO 2.2331D+07 3.3642D-15
ERREUR SUR LA SOLUTION 7.5127D-08
RANG NBRE MAILLES NBRE TERMES K LU FACTEURS
N 0 : 54684 7117247 117787366
N 1 : 55483 7152211 90855351
…
EN % : VALEUR RELATIVE ET DESEQUILIBRAGE MAX
: 1.45D+01 2.47D+00 2.38D+00 1.50D+01 4.00D+01 2.57D+01
: 1.40D-01 -1.09D+00 -5.11D+00 -9.00D-02 1.56D+00 -4.16D-01
MEMOIRE RAM ESTIMEE ET REQUISE PAR MUMPS EN Mo(FAC_NUM + RESOL)
RANG ASTER : ESTIM IN-CORE | ESTIM OUT-OF-CORE | RESOL. OUT-OF-CORE
N 0 : 1854 512 512
N 1 : 1493 482 482
…
#1 Resolution des systemes lineaires CPU (USER+SYST/SYST/ELAPS): 105.68 3.67 59.31
#1.1 Numerotation, connectivite de la matrice CPU (USER+SYST/SYST/ELAPS): 3.26 0.04 3.26
#1.2 Factorisation symbolique CPU (USER+SYST/SYST/ELAPS): 3.13 1.20 4.11
#1.3 Factorisation numerique (ou precond.) CPU (USER+SYST/SYST/ELAPS): 45.22 0.83 23.48
#1.4 Resolution CPU (USER+SYST/SYST/ELAPS): 54.07 1.60 28.46
#2 Calculs elementaires et assemblages CPU (USER+SYST/SYST/ELAPS): 3.44 0.03 3.42
#2.1 Routine calcul CPU (USER+SYST/SYST/ELAPS): 2.20 0.01 2.20
#2.1.1 Routines te00ij CPU (USER+SYST/SYST/ELAPS): 2.07 0.00 2.06
#2.2 Assemblages CPU (USER+SYST/SYST/ELAPS): 1.24 0.02 1.22
#2.2.1 Assemblage matrices CPU (USER+SYST/SYST/ELAPS): 1.22 0.02 1.21
#2.2.2 Assemblage seconds membres CPU (USER+SYST/SYST/ELAPS): 0.02 0.00 0.01
Figure 3.5-1._Extrait de fichier de message en INFO=2.
Exemples d’utilisation#
Concluons ce chapitre par deux séries de tests illustrant les écarts de performance suivant le cas de figure et le critère observé (cf. figures 3.5-2/3). Le cas-test canonique du cube en linéaire se parallélise très bien. En centralisé (resp. en distribué), plus de 96% (resp. 98%) des phases de construction et d’inversion du système linéaire sont parallélisés. Soit un speed-up théorique proche de 25 (resp. 50). En pratique, sur les nœuds parallèles de la machine centralisée Aster , on obtient d’assez bonnes accélérations: speed-up effectif de 14 sur 32 processeurs au lieu des 17 théoriques.
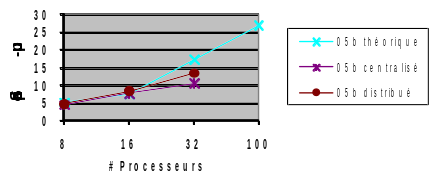
\(N=0.7M/\mathit{nnz}=27M\)
%parallèle centralisé/distribué: 96/98
Speed-ups théoriques cent./dist. <25/50
32 proc (x1): ~3min
Conso. RAM IC: 4Go (1 proc)/1.3Go (16)
Conso. RAM OOC: 2Go (1 proc)/1.2Go (16)
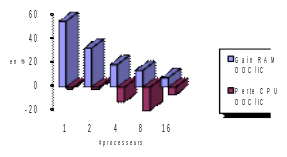
Figure 3.5-2._ Calcul mécanique linéaire (op. MECA_STATIQUE) sur le cas-test officiel du cube (mumps05b). On construit et résout un seul système linéaire. Simulation effectuée sur la machine centralisée Aster avec Code_Aster v11.0. Consommations RAM Aster+MUMPS mesurées.
Sur l’étude non linéaire de la pompe, les gains que l’on peut espérer sont plus faibles. Compte-tenu de la phase d’analyse séquentielle de MUMPS, seulement 82% des calculs sont parallèles. D’où des speed-ups théoriques et effectifs appréciables mais plus modestes. D’un point de vue mémoire RAM, la gestion OOC de MUMPS procure des gains intéressants dans les deux cas, mais plus marqués pour la pompe: en séquentiel, gain IC vs OOC de l’ordre de 85%, contre 50% pour le cube. En augmentant le nombre de processeurs, la distribution de données qu’induit le parallélisme rogne progressivement ce gain. Mais il reste prégnant sur la pompe jusqu’à 16 processeurs et disparaît quasiment avec le cube.
\(N=0.8M/\mathit{nnz}=28.2M\)
%parallèle centralisé/distribué: 55/82
Speed-ups théoriques cent./dist. <3/6
16 proc ~15min
Conso. RAM IC: 5.6Go (1 proc)/0.6Go (16)
Conso. RAM OOC: 0.9Go (1 proc)/0.3Go (16)
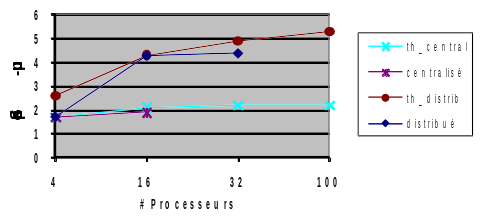
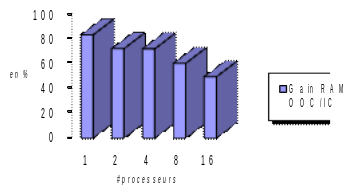
Figure 3.5-3._ Calcul mécanique non linéaire (op. STAT_NON_LINE) sur une géométrie plus industrielle (pompe RIS). On construit et résout 12 systèmes linéaires (3 pas de temps x 4 pas de Newton). Simulation effectuée sur la machine centralisée Aster avec Code_Aster v11.0. Consommations RAM MUMPS estimées.
Conclusion#
Dans le cadre des simulations thermo-mécaniques avec Code_Aster , l’essentiel des coûts calcul provient souvent de la construction et de la résolution des systèmes linéaires . Depuis 60 ans, deux types de techniques se disputent la suprématie dans le domaine, les solveurs directs et ceux itératifs. Code_Aster , comme bon nombre de codes généralistes, a fait le choix d’une offre diversifiée dans le domaine. Avec toutefois une orientation plutôt solveurs directs creux . Ceux-ci sont plus adaptés à ses besoins que l’on peut résumer sous le triptyque «robustesse/problèmes de type multiples seconds membres/parallélisme modéré». Le code s’appuyant désormais sur de nombreux «middlewares» optimisés et pérennes (MPI, BLAS, LAPACK, METIS…) et s’utilisant principalement sur des clusters de SMP (réseaux rapides, grande capacité de stockage RAM et disque), on cherche à optimiser le traitement des solveurs linéaires dans cette optique.
Compte-tenu de la technicité requise [36]_ et d’une offre internationale riche [37]_ , pour effectuer efficacement ces résolutions, la question durecourt à un produit externe est désormais incontournable . Cela permet d’acquérir, à moindre frais, une fonctionnalité souvent efficace, fiable, performante et bénéficiant d’un large périmètre d’utilisation. On peut ainsi bénéficier du retour d’expérience d’une large communauté d’utilisateurs et des compétences (très) pointues d’équipes internationales.
Ainsi Code_Astera fait le choix d’intégrer la multifrontale parallèle du package MUMPS . Ceci en complément, notamment, de sa multifrontale «maison». Mais si celle-ci bénéficie d’une adaptation de longue haleine aux modélisations Aster, elle reste moins riche en fonctionnalités (pivotage, pré/post-traitements, qualité de la solution…) et moins performantes en parallèle (pour des consommations RAM du même ordre). Pour exploiter certaines modélisations (éléments quasi-incompressibles, X-FEM…) ou passer des «études frontières» (cf. internes de cuves), ce couplage « Code_Aster +MUMPS» devient parfois la seule alternative viable.
Depuis, son intégration dans Code_Aster bénéficie d’un enrichissement continu et MUMPS (SOLVEUR/METHODE=’MUMPS’) est quotidiennement utilisé sur des études . Notre Rex s’est bien sûr étoffé et nous entretenons une relation partenariale active avec la «core-team» de MUMPS (notamment via l’ANR SOLSTICE et une thèse).
En mode parallèle , l’usage de MUMPS procure des gains en CPU (par rapport à la méthode par défaut du code, la multifrontale «maison») de l’ordre de la douzaine sur 32 processeurs de la machine Aster . Sur des cas plus favorables ou en exploitant un deuxième niveau de parallélisme ou les compressions BLR, ce gain CPU peut-être bien meilleur.
Le solveur MUMPS permet donc, non seulement de résoudre des problèmes numériquement difficiles, mais, inséré dans un processus de calcul Aster déjà partiellement parallèle, il en démultiplie les performances. Il procure au code un cadre parallèle performant, générique, robuste et grand public . Il facilite ainsi le passage des études standards (<million de degrés de liberté) et rend accessible au plus grand nombre le traitement de gros cas (~ plusieurs millions de degrés de liberté).
Bibliographie#
Livres/articles/proceedings/thèses…#
[ADD89] M.Arioli, J.Demmel et I.S .Duff. Solving sparse linear systems with sparse backward error. SIAM journal on matrix analysis and applications . 10, 165:190 ( 1989 ).
[ADE00] P.R.Amestoy, I.S.Duff et J.Y.L’Excellent. Multifrontal parallel distributed symmetric and unsymmetric solvers . Comput. Methods in Appl. Mech. Eng. 184, 501:520 ( 2000 ).
[ADKE01] P.R.Amestoy, I.S.Duff, J.Koster et J.Y.L’Excellent. A fully asynchronous multifrontal solveur using distributed dynamic scheduling . SIAM journal of matrix analysis and applications, 23, 15:41 ( 2001 ).
[AGES06] P.R.Amestoy, A.Guermouche, J.Y.L’Excellent et S.Pralet. Hybrid scheduling for the parallel solution of linear systems . Parallel computing. 32, 136:156 ( 2006 ).
[Che05] K.Chen. Matrix preconditioning techniques and applications . Ed. Cambridge University Press ( 2005 ).
[CW13] C.Weisbecker. Improving Multifrontal Solvers by Means of Algebraic Block Low-Rank Representations . PhD thesis of Toulouse University ( 2013 ). 2013 Leopold Escande thesis award.
[CW15] P.Amestoy, C.Ashcraft, O.Boiteau, A.Buttari, J.Y.L’Excellent and C.Weisbecker. Improving Multifrontal Methods by Means of Block Low-Rank Representations . SIAM J.Sci. Comput., 37 (3), A1451-1474 ( 2015 ).
[Dav06] T.A.Davis. Direct methods for sparse linear systems . Ed. SIAM ( 2006 ).
[Duf06] I.S.Duff et al. Direct methods for sparse matrices Ed. Clarendon Press ( 2006 ).
[Gol96] G.Golub & C.Van Loan. Matrix computations . Ed. Johns Hopkins University Press ( 1996 ).
[Hig02] N.J.Higham. Accuracy and stability of numerical algorithms . Ed. SIAM ( 2002 ).
[Las98] P.Lascaux & R.Théodor. Analyse numérique matricielle appliquée à l’art de l’ingénieur . Ed. Masson ( 1998 ).
[Liu89] J.W.H.Liu. Computer solution of large sparse positive definite systems . Prentice Hall ( 1981 ).
[Meu99] G.Meurant. Computer solution of large linear systems . Ed. Elsevier ( 1999 ).
[Saa03] Y.Saad. Iterative methods for sparse matrices . Ed. PWS ( 2003 ).
Rapports/compte-rendus EDF#
[Anf03] N.Anfaoui. Une étude des performances de Code_Aster: proposition d’optimisation . Stage de DESS de mathématiques appliquées de PARIS VI ( 2003 ).
[BD08] O.Boiteau et C.Denis. Activation des fonctionnalités «Out-Of-Core» de MUMPS dans Code_Aster . Compte-rendu EDF R&D CR-I23/08/047 ( 2008 ).
[Boi07] O.Boiteau. Intégration de MUMPS parallèle distribué dans Code_Aster . Note EDF R&D HI-I23/07/03167 ( 2007 ).
[Boi13] O.Boiteau. Solveur linéaire MUMPS: chantiers logiciels dans Code_Aster, thèse de C.Weisbecker sur les compressions low-rank et partenariat EDF/INPT . Note EDF R&D H-I23-2013-03942 ( 2013 ).
[Boi15] O.Boiteau. Partenariats et animations scientifiques dans le domaine des bibliothèques HPC d’algèbre linéaire: consortium MUMPS, mini-symposium SOLVER et semestre CIMI . Note EDF R&D H-I23-2015-04879 ( 2015 ).
[Boi16] O.Boiteau. MUMPS: dernières avancées du produit et actualités du consortium . Note EDF R&D 6125-1106-2016-14581 (2016).
[Des07] T.DeSoza. Evaluation et développement du parallélisme dans Code_Aster . Stage de Master ENPC ( 2007 ) et note EDF R&D HT-62/08/01464 ( 2008 ).
[Dur08] C.Durand et al. HPC avec Code_Aster: états des lieux et perspectives . Note EDF R&D HT-62/08/0139 ( 2008 ).
[GM08] S.Géniaut et F.Meissonnier. Faisabilité d’une étude de nocivité de fissure dans une vanne MP par la méthode X-FEM et avec la plate-forme SALOME . Compte-rendu EDF R&D CR-AMA/08/0255 ( 2008 ).
[GS11] V.Godard et N.Sellenet. Calcul HPC avec Code_Aster: état des lieux et perspectives . CR-AMA-11.042 ( 2011 ).
[Tar07] N.Tardieu. GCP+MUMPS, une solution simple pour la résolution de problèmes avec contact en parallèle . Compte-rendu EDF R&D CR-AMA/07/0257 ( 2007 ).
[SOL] O.Boiteau. Suivi de l’ANR SOLSTICE. Comptes-rendus EDF R&D ( 2007-2010 ).
Ressources internet#
[Dav] T.A.Davis. Pointeur sur les packages de solveurs creux directs: http://www. cise.ufl.edu/research/sparse/codes/.
[Don] J.Dongarra. Pointeur sur les packages de solveurs: http://www.netlib.org/utk/people/JackDongarra/la-sw.html .
[MaMa] Site web de MatrixMarket: http://math.nist.gov/MatrixMarket/index.html.
- [Mum] Site web officiel de MUMPS:
[MUC] Site web officiel du consortium MUMPS: http://mumps-consortium.org.
Historique des versions du document#
VersionAster |
Auteur(s) ou contributeur(s), organisme |
Description des modifications |
9.4 |
O.BOITEAU EDF R&D SINETICS |
Texte initial |
V10.4 |
O.BOITEAU EDF R&D SINETICS |
Corrections formelles dues au portage .doc/.odt; Mise à jour sur le parallélisme; Prise en compte des rqs de l’équipe MUMPS ; Rajout de nouveaux mot-clés (ELIM_LAGR2, LIBERE_MEMOIRE, MATR_DISTRIBUEE); Amaigrissement de la partie conseil/périmètre d’utilisation maintenant dévolue à la note U2.08.03 . |
V11.3 |
O.BOITEAU EDF R&D SINETICS |
Rajout du nouveau mot-clé GESTION_MEMOIREà la place de OUT_OF_COREet LIBERE_MEMOIRE. Rajout du paragraphe sur la prise en compte de systèmes singuliers. |
V13.1 |
O.BOITEAU EDF R&D SINETICS |
Mise à jour et suppression de quelques paragraphes obsolètes. Rajout des éléments sur le consortium et sur BLR. |
V13.3 |
O.BOITEAU EDF R&D SINETICS |
Nouveaux éléments liés à l’usage des threads et aux renuméroteurs parallèles PARMETISet PTSCOTCH. |
V13,4 |
O.BOITEAU EDF R&D/PERICLES |
Nouveau mot-clé ACCELERATION. |
Annexe n°1: Principe des compressions BLR dans MUMPS#
Ce paragraphe résume les différents aspects techniques des travaux de thèse de Clément Weisbecker sur les compressions low-rank[CW15][Boi13]. Ces travaux ont été poursuivis et améliorés par l’équipe MUMPS et ils sont en partie disponibles dans la version consortium[MUC] du produit.
Pour plus de détails on pourra consulter le document de thèse proprement dit [CW13]. Les figures réutilisées ici proviennent d’ailleurs, soit de ce document, soit du jeu de slides de sa soutenance.
Principe de la méthode multifrontale
La méthode multifrontale est une classe de méthode directe utilisée pour résoudre des systèmes linéaires . C’est cette méthode qui est implantée dans le produit MUMPS et c’est elle qui est en général utilisée dans les grands codes commerciaux en mécanique des structures (ANSYS, NASTRAN…). Même si il existe d’autres stratégies (supernodale…) et qu’elles commencent à être implémentées dans des packages publics (SuperLU, PastiX…), ce travail de thèse s’est exclusivement focalisé sur cette stratégie standard qu’est la multifrontale. Néanmoins beaucoup de ses résultats peuvent sans doute s’étendre ou s’adapter à ces autres méthodes de résolution.
La méthode multifrontale , mise au point par I.S.Duff et J.K.Reid (1983), consiste notamment à utiliser la théorie des graphes [38]_ pour construire, à partir d’une matrice creuse, un arbre d’élimination organisant efficacement les calculs (cf. figures 7.1.1). Les carrés noirs matérialisent les termes matriciels non nuls. Pour manipuler, «par graphes interposés», ce type de données on impose usuellement la règle suivante: un point du graphe représente une inconnue et, une arête entre deux points, un terme matriciel non nul.
Ainsi dans l’exemple ci-dessous, les variables 1 et 2 doivent être reliées par une arête (dans la numérotation initiale). Généralement, la numérotation initiale de la matrice n’est pas optimale . Afin de réduire l’encombrement mémoire de la factorisée [39]_ , le nombre de flop des manipulations ultérieures et afin d’essayer de garantir un bon niveau de précision du résultat, on renumérote cette matrice initiale . On voit ainsi que le nombre de termes supplémentaires (‘fill-in’) créés par la factorisation passe de 16 à 10.
C’est à partir de cette matrice renumérotée que l’on construit l’arbre d’élimination propre à la multifrontale. Cette vision arborescente a la grand mérite d’organiser concrètement les tâches: on détermine précisément leur dépendance ou non (pour ménager du parallélisme), leur précédenc e (pour opérer des regroupements afin d’optimiser les performances BLAS); on peut prévoir certaines consommations (en temps et en mémoire) voire essayer de limiter les problèmes numériques.
Ainsi dans l’exemple ci-dessous, le traitement de la variable 1 n’a aucune incidence sur les variables 2, 4 et 5. Par contre, il va impacter les variables 3 et 7 qui occupent les niveaux supérieurs de l’arbre (ils sont ses ascendants).
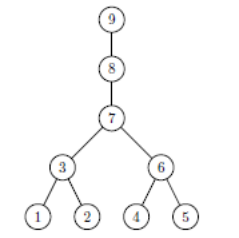
Figure 7.1.1_ Première ligne, de gauche à droite : une matrice creuse initiale, la même matrice réordonnée et l’arbre d’élimination associé à cette dernière. Deuxième ligne, de gauche à droite : les factorisées correspondant aux matrices initiale et renumérotée.
La deuxième idée forte de la méthode multifrontale est de réunir un maximum de variables (on parle d’ amalgamation ) afin de constituer des «fronts» (denses) dont le traitement numérique sera beaucoup plus efficace ( via des routines de type BLAS).
Quitte à remplir le sous-bloc matriciel correspondant par des vrais zéros et à les manipuler tel quels [40]_ . C’est par exemple ce qui est fait dans l’arbre de la figure 7.1.2 entre les variables amalgamées 7, 8 et 9. Il existe de nombreuses techniques d’amalgamation basée sur des critères de graphe, des aspects numériques ou des considérations informatiques (par ex. parallélisme distribué).
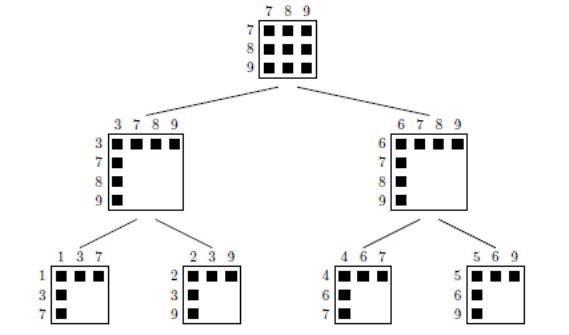
Figure 7.1.2_ Arbre d’élimination avec ses blocs matriciels et un choix de « fronts ».
Remarque:
Par soucis de simplification, on n’abordera pas dans ce résumé les autres traitements numériques qui interviennent souvent dans le processus: mise à l’échelle des termes (‘scaling’), permutation des colonnes et pivotage statique/dynamique. Comme le « diable est souvent dans les détails », ce sont pourtant ces traitements connexes qui ont complexifié les travaux numériques et les développements informatiques de Clément. Ils sont essentiels au bon déroulement de beaucoup de nos simulations industrielles avec Code_Aster.
Arbre d’élimination#
Le traitement algorithmique de l’arbre commence du bas (au niveau des «feuilles») vers le haut (vers «la racine»). Au sein de chaque feuille ou de chaque «nœud» de branche on associe un front dense . Dans un front on distingue deux types de variables :
les ‘Fully Summed’ (FS) qui comme leur nom l’indique sont complètement traitées et ne vont plus être mises à jour;
les ‘Non Fully Summed’ (NFS) qui elles attendent toujours des contributions d’autres branches de l’arbre.
Le premier type de variables peut être complètement « éliminé »: les termes de la matrice factorisée les concernant (lignes de U et colonnes de L ) sont calculés et stockés [41]_ une fois pour toute. Le second type produit un bloc de contributions [42]_ (noté CB pour ‘Contribution Blocks’) qui va s’additionner au niveau supérieur de l’arbre avec d’autres CBs associés aux mêmes variables (cf. figure 7.2.1).
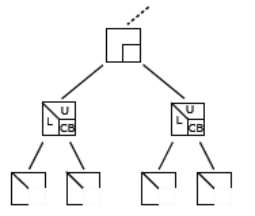
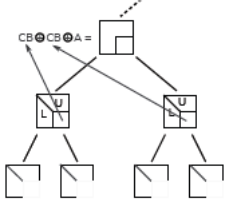
Figure 7.2.1_ Structure générale d’un « front » avant et après son traitement.
A leur tour, certaines variables associées à ces blocs vont être éliminées et d’autres, au contraire, vont continuer à participer activement au processus en fournissant à nouveaux des CBs. Et ainsi de suite… jusqu’à la racine de l’arbre. A ce dernier stade, il n’y a plus que des variables éliminées et plus aucun CB !
Ainsi dans les fronts associés aux feuilles de gauche de la figure 7.2.1, les variables 1 et 2 sont FS, tandis que les variables 3, 7 et 9 sont NFS. Ces dernières fournissent des CBs qui vont être cumulés dans le front du niveau supérieur regroupant les variables 3, 7, 8 et 9. Ce dernier va « soulager » le processus algorithmique de la variable FS 3 (elle va être éliminée), tandis que les NFS 7, 8 et 9 vont continuer leur cheminement dans l’arbre.
Traitements algorithmiques#
Dans le cas d’une matrice dense générale A , la factorisation de Gauss conduit à construire itérativement les termes de L et ceux de U suivant un algorithme du type 1.1 (cf. figure 7.3.1). Ici, pour simplifier, on ne tient ni compte des termes nuls (ou trop petits), ni d’aspects numériques type pivotage, permutation ou scaling.
A chaque étape k correspond un pivot (supposé non nul) qui va conduire la mise à jour du bloc

sous-jacent, ainsi que la construction de la colonne et de la ligne correspondante de L et de U .
Cet algorithme requiert donc deux types d’opérations:
Une étape de factorisation (notée ‘ Factor ’) qui utilise le pivot diagonal

pour construire la k -ième partie de la factorisée et ainsi éliminer la k -ième variable (elle sera dite FS).
Une étape de mise à jour (notée ‘ Update ’) qui construit le bloc de contribution (CB).
La complexité algorithmique de l’ensemble et son coût mémoire sont respectivement en

et en

. Ces seuls chiffres illustrent l’impact de cette étape sur les performances de nos simulations (même si celles-ci sont effectuées en “sparse”).


Algorithmes 7.3.1_ Exemples d’algorithmes de factorisation denses, en scalaire et par blocs.
Afin d’optimiser les coûts on travaille généralement sur des blocs et non sur des scalaires (cf. algorithme 1.3). Les données à rassembler en mémoire RAM, au même instant, sont de plus petites tailles et les opérations algébriques vectorielles et matricielles sont beaucoup plus efficaces ( via des routines de type BLAS optimisées).
Les types d’opérations à effectuer restent inchangés:
Factorisations locales de blocs diagonaux (‘ Factor ’),
Descente-remontées (notée ‘ Solve ’) pour construire effectivement les blocs colonnes/lignes de la factorisée,
Mise à jour (‘ Updat e’) par blocs de la sous-matrice.
Dans les arbres d’élimination présentés précédemment, c’est ce type d’opération qui est conduit au sein de chaque front , puis entre chaque front et son « père ». La compression low-rank va avoir pour objectif de réduire leur complexité algorithmique ainsi que leur empreinte mémoire (pic RAM et consommation disque).
Gestion de la mémoire#
Sur ce dernier point, souvent le plus crucial pour nos études, t out le problème réside dans la «gestion différée des CBs» . Lors de l’étape k de l’algorithme 1.3, on doit garder en RAM non seulement le front «actif», mais aussi les CBs en attente de traitement et les (éventuels) facteurs non déchargés sur disque (si l’OOC est activé). Ils constituent la mémoire active du processus (zone bleue et verte de la figure 7.4.1).
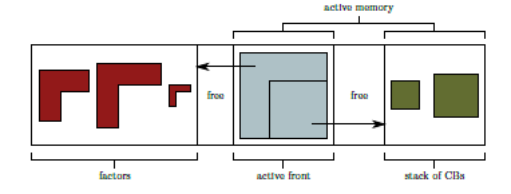
Figure 7.4.1_ Gestion mémoire des différents éléments manipulés par la multifrontale.
Cette mémoire active est gérée comme une pile (‘stack’). Elle fluctue constamment . Elle croit lorsqu’un front est chargé. Puis elle décroit au fur et à mesure que des CBs associés à ce front sont consommés. Enfin elle recroit avec les nouveaux facteurs et le nouveau CB résultant de ce front.
Les nouveaux facteurs sont ensuite éventuellement recopiés sur disque. L’empreinte mémoire de ces facteurs (zone rouge à gauche du graphique) est plus simple à analyser : elle ne fait qu’enfler au fur et à mesure de la remontée de l’arbre !
Dans tous les cas, ces deux zones mémoire ne sont pas faciles à prédire a priori . Elles dépendent notamment de la renumérotation, de la construction de l’arbre d’élimination mais aussi des prétraitements numériques. C’est une des tâches effectuées par l’étape d’analyse de MUMPS. Elle est utile à la fois à la multifrontale pour allouer efficacement ses zones mémoire, mais aussi pour le code appelant afin de gérer au mieux ses propres objets internes [43]_ . La gestion optimisée de ces éléments se complique encore du fait des traitements numériques qui sont effectués dynamiquement en cours de factorisation: par exemple, l’organisation du pivotage et la distribution des données en parallèle.
C’est le pic de cette mémoire active qui constitue l’enjeu essentiel de cette thèse . Il est souvent très supérieur à la taille de la factorisée. Pourtant celle-ci est déjà souvent en 500N dans nos études actuelles (avec N la taille du problème). Ainsi le traitement d’un matrice comportant 1 million d’inconnues requiert au moins 500*1*12 [44]_ =6Go de RAM (en réel double précision). Et ce chiffre a tendance à augmenter avec la taille du problème (on passe de 500N à 1000N voire plus).
On peut donc atteindre des pics RAM que même la distribution parallèle des données combinée à l’OOC ne pourra pas gérer efficacement [45]_ . Donc toute réduction significative de ce pic serait un gain très appréciable pour nos grosses études actuelles et futures .
Approximation low-rank#
Une matrice dense A , de taille m x n , est dite « de rang faible » (‘low-rank’) d’ordre k (< min(m,n) ) lorsqu’elle peut se décomposer sous la forme
(7.5-1)
avec U et V des matrices beaucoup plus petites (respectivement m x k et k x n ) et E une matrice m x n «négligeable» (
). Cette notion de «rang numérique» ne doit pas être confondue avec la notion de rang algébrique
Lors des manipulations ultérieures on fait alors l’approximation
(7.5-2)
en pariant (souvent sous contrôle), qu’elle aura peu d’incidence sur le processus global. Cette approximation est donc dépendante du paramètre de compression e .
C’est ce paramètre que l’on va faire varier, en pratique, pour adapter les gains du low-rank à la situation. Par exemple:
avec e<10-9 on a compression avec une perte de précision légère et pilotable. On peut bien sûr continuer à utiliser la multifrontale en tant que solveur direct . Pour retrouver une précision identique au cas full-rank, une ou deux itérations de raffinement itératif sont suffisants [46]_
.
avec e>10-9 la compression est meilleure mais la perte de précision peut être importante [47]_
. On peut alors utiliser la factorisée pour construire un préconditionneur, plus ou moins «frustre», accélérant un solveur itératif de Krylov.
D’autre part, hormis des gains évidents en terme de stockage, la manipulation de telles matrices peut s’avérer très avantageuse: le rang de la somme est inférieur (au pire) à la somme des rangs et le rang du produit est inférieur au minimum des rangs. Une fois décomposées, la manipulation de matrices low-rank peut donc être (relativement) contrôlée afin d’optimiser la compression du résultat .
Ainsi le produit de deux matrices dense de taille n x n et de rang k , avec

, réduit la une complexité algorithmique de l’opération de

à

; son empreinte mémoire passant elle de

à

.
Une matrice transformée sous forme low-rank est dite «rétrogradée» (‘ demoted ’) ou compressée . La transformation inverse, aux approximations près, «promeut» la matrice (‘ promoted’ ) ou la décompresse .
Pour garder la même terminologie lorsqu’on manipule de manière standard une matrice (sans exhiber une décomposition du type (7.5-1)), on dit que celle-ci est de rang plein (‘full-rank’) .
La «décomposition low-rank» d’une matrice peut être effectuée de différentes manières:
SVD ,
Rank-Revealing QR ( RRQR ),
Adaptative Cross Approximation ( ACA ),
Echantillonnage aléatoire .
Dans cette thèse Clément utilise principalement la deuxième solution, moins précise qu’une classique SVD mais bien moins coûteuse. Le tout étant que cette compression soit mutualisée entre différents traitements et qu’elle permette une compression maximale. Idéalement il faudrait donc que le rang obtenu vérifie une condition du type :

(7.5-3)
Une partie du travail de Clément a consisté à mettre au point des heuristiques adaptées à la multifrontale afin d’essayer de respecter le plus souvent possible ce critère.
Multifrontale “Block Low-Rank” (BLR)#
L’objectif de cette thèse est d’exploiter ce type de compression en décomposant sous forme low-rank les plus gros fronts de l’arbre d’élimination d’une multifrontale . Car ce sont ces sous-blocs matriciels denses qui génèrent le plus de flop et qui grèvent le pic RAM (du fait de tous les CBs qu’ils vont agglomérer). En général ces gros fronts se situent dans les derniers niveaux de l’arbre d’élimination.
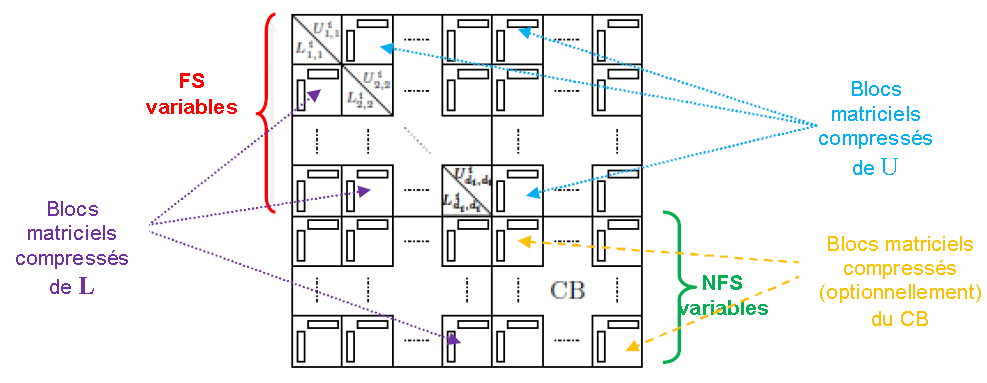
Figure 7.6.1_ Structure d’un front compressé après sa factorisation.
Comme illustré ci-dessous (cf. figure 7.6.1) on va donc, premièrement, décomposer en colonnes et en lignes de sous-blocs (décomposition par ‘panels’), les blocs matriciels correspondant aux quatre types de termes des fronts (suivant la terminologie de la figure 7.2.1):
FSxFS (‘block (1,1)’),
FSxNFS (‘block (1,2)’),
NFSxFS (‘block (2,1)’),
NFSxNFS (‘block (2,2)’).
Puis chacun de ces sous-blocs va être compressé en low-rank suivant la formule (7.5-1). Du moins lorsque cette compression est licite [48]_ . Sauf les sous-blocs diagonaux de la sous-partie FSxFS qui restent en full-rank (pour optimiser leurs manipulations ultérieures).
On adapte la taille des panels de manière à ce qu’elle soit :
Suffisamment grande pour tirer parti de la performance des noyaux BLAS (invariant de boucle, minimisation des défauts de caches et gestion optimisée de la hiérarchie mémoire);
Pas trop grande pour ménager de la souplesse dans les manipulations numériques (pivotage, scaling) et informatiques (parallélisme distribué) ultérieures;
De taille moyenne afin d’optimiser les coûts des communications MPI (latence versus bande-passante).
De taille moyenne afin de ménager de la souplesse dans le regroupement de variables qui va suivre (le ‘clustering’). Cette réorganisation devant générer un maximum de compression.
Pas trop grande pour ne pas coûter trop cher en SVD ou en RRQR.
Mais tout le problème réside dans le fait que ces sous-blocs matriciels n’ont aucune raison d’être low-rank ! Même si ils sont de grosse taille, les parties de fronts ‘demoted’ peuvent s’avérer de rang plein. Les coûts des SVDs ou des RRQRs ne seront alors pas compensés et l’objectif de compression s’avérera compromis !
En s’inspirant des travaux déjà effectués par d’autres techniques de compression (matrices hiérarchique de type H, H2, HSS/SSS…), il a été mis au point des critères pour décomposer les variables composant un front et les renuméroter afin qu’elles génèrent des sous-blocs matriciels low-ranks. Ce critère est basé sur la constatation empirique suivante :
Plus deux blocs de variables sont distants, plus le rang numérique du bloc matriciel qu’il implique devient faible.
Cette condition dite «d’admissibilité» a été testée sur certains problèmes modèles issus de discrétisation d’EDP elliptique et elle est illustrée à la figure 7.6.2. Avec la terminologie de la théorie des graphes elle peut se reformuler sous la forme suivante :

(7.6-1)
avec diam et dist , les notions usuelles de diamètre et de distance dans le graphe associé au front traité.
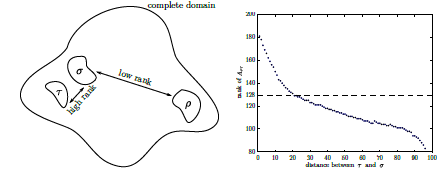
Figure 7.6.2_ Evolution du rang «numérique» de deux groupes de variables de taille homogène en fonction de la distance (au sens des graphes) qui les sépare.
Ainsi, sur l’exemple de la figure ci-dessous (cf. fig. 7.6.3), on obtient avec le découpage des variables du front en tranches un gain en nombre de termes de 17%. C’est-à-dire que, en moyenne, chaque sous-bloc admet un rang numérique k tel que

.
Tandis qu’avec le découpage en damier, le gain atteint 47%:

. Cet écart est dû à la plus grande régularité du second sur le premier. Les sous-blocs homogènes en forme de carré ont des diamètres rapidement plus faibles que la distance entre les sous-blocs. Avec leur forme allongée, ce n’est évidemment pas le cas des sous-blocs résultant du découpage en tranche !
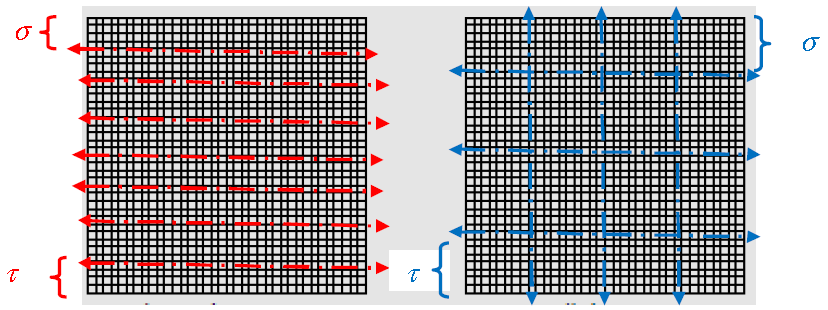
Figure 7.6.3_ Exemple de deux types de clustering sur un front dense: en tranche et en damier.
Quelques éléments complémentaires#
C’est donc sur un critère d’admissibilité de ce type que MUMPSt va baser son clustering des variables composant un front . Il a beaucoup travaillé pour rendre cette «opération clé» de la méthode compatible avec les contraintes numérico-informatiques de la multifrontale et de l’outil MUMPS ; tout en veillant à ménager un maximum de compression et en limitant son surcoût (en temps).
Figure 7.7.1_ Clustering de type «hérité» entre les variables NFS d’un front
et celles FS d’un front antérieur.
Exemple de sophistication: ce clustering est opéré séparément sur les deux types de variables, les FS et les NFS . Comme en parcourant l’arbre d’élimination, les variables NFS d’un front deviennent les FS des fronts des niveaux supérieurs, on décompose cette tâche. D’autre part on ne recommence pas complètement ces découpages à chaque front. On mutualise certaines informations afin de limiter les surcoûts (en temps). Cet algorithme particulier de clustering est appelé « hérité » (‘inherit’) par opposition à l’ algorithme standard dit «explicite» (‘explicit’) pour lequel on recommence les deux clusterings à chaque manipulation de nouveau front.
Le surcoût de la variante « explicite » de clustering peut être prohibitif sur les très gros problèmes (plusieurs fois le coût de la totalité de la phase d’analyse !) alors que le coût du clustering optimisé reste raisonnable : seulement quelques pourcents de cette phase d’analyse. Les gains low-rank des deux variantes sont très proches par contre l’implémentation de la version optimisée est plus complexe.
Enfin ces clusterings sont effectués par des outils standards, METIS ou SCOTCH . Mais on ne les applique pas directement sur les variables des fronts mais sur des halos les englobant. Cette astuce permet d’orienter convenablement ces découpages afin qu’ils produisent des groupes de nœuds homogènes contigües.
D’autre part, pour être plus précis, le traitement d’un front comporte cinq étapes (déjà évoquées dans les algorithmes de la fig. 7.3.1). On commence par découper les variables en deux niveaux emboîtés de panels:
le premier niveau, le plus grand, celui qui est à l’extérieur (appelé ‘ outer panel ’ ou ‘ BLR panel ’), résulte du clustering low-rank;
tandis que le second, celui qui est à l’intérieur du précédent (‘ inner panel ’ ou ‘ BLAS panel ’) regroupe les variables par sous-paquets de 32, 64 ou 96 variables contigües afin de nourrir plus efficacement les noyaux de calculs (et réduire le coût des communications MPI et des I/Os).
Puis, on a deux boucles emboîtées : la première sur les panels BLR et la seconde sur les panels BLAS. Pour un panel BLAS donné, on effectue :
l’étape de Factorisation ( F ),
l’étape de Solve ( S ),
l’Upgrade Interne ( UI ) entre tous les sous-panels suivants du panel BLR,
l’Upgrade Externe ( UE ) entre tous les panels BLR suivants.
L’ordre standard des opérations peut donc être noté grossièrement FSUU . Suivant le niveau auquel on fait intervenir la Compression low-rank ( C ) on distingue alors 4 variantes :
FSUUC,
FSUCU,
FSCUU,
FCSUU.

Tableau 7.7.2_ Comparaison des coûts des différentes étapes
en dense (full-rank) et en low-rank.
C’est la variante n°3, FSCUU, qui est industrialisée les versions consortium de MUMPS.
Compte-tenu des coûts relatifs de chacune des opération s (cf. tableau 7.7.2) et des contraintes de robustesse de l’outil, c’est cette variante qui a été privilégiée . Elle permet de réduire significativement les coûts globaux tout en ménageant un maximum de précision dans les deux premières étapes (F et S). Car celles-ci sont cruciales dans la gestion de plusieurs ingrédients numériques sophistiqués (scaling, pivotage, détection de singularité, calcul de déterminant, test de Sturm…). Dans un premier temps, on a donc préféré les impacter le moins possible par cette compression. Aussi celle-ci est effectuée juste après. Et ses gains (et ses approximations éventuelles) n’impacteront ainsi que les updates internes et externes (UI et UE).