d4.02.06 Structure de données FORMAT_IDEAS#
Résumé:
On décrit ici la structure de données FORMAT_IDEAS. Cette SD est utilisée lors de l’exécution de la commande LIRE_RESU, elle permet de repérer et d’extraire du fichier universel «unv»d‘ IDEAS, les résultats souhaités par l’utilisateur.
Table des matières
Arborescence#
FORMAT_IDEAS(K16) :: = record ♦ “.FID_NOM” : OJB S V K16 Long = nbnoch ♦ “.FID_NUM” : OJB S V I Long = nbnoch ♦ “.FID_PAR” : OJB S V I Long = nbnoch*800 ♦ “.FID_LOC” : OJB S V I Long = nbnoch*10 ♦ “.FID_CMP” : OJB S V K8 Long = nbnoch*1000 ♦ “.FID_NBC” : OJB S V I Long = nbnoch
Contenu des objets#
Convention : nbnoch = nombre de champs à lire
“.FID_NOM “ : S V K16#
Cet objet contient le nom des champs à lire.
Pour \(i=1\) ,nbnoch
→ v(i): nom du ièmechamp à lire
ex: ‘DEPL’, ‘VITE’, …,’SIEF_ELNO’
“.FID_NUM” : S V I#
Cet objet contient pour chacun des champs à lire le numéro du dataset associé.
Pour \(i=1\) ,nbnoch
→ v(i): numéro du dataset associé au ièmechamp à lire
ex: 55, 57, 2414
“.FID_PAR” : S V I#
Cet objet contient pour chacun des champs à lire les caractéristiques de l’entête du dataset recherché. Cet entête est composé au maximum de 20 “records” constitué de 40 “fields” chacun.
V(1) |
1erfield du record 1 du champ 1 |
… |
|
V(48) |
8èmefield du record 2 du champ 1 |
… |
|
V(800) |
40èmefield du record 20 du champ 1 |
… |
|
V(6401) |
1erfield du record 1 du champ 9 |
… |
|
V(7200) |
40èmefield du record 20 du champ 9 |
… |
|
v((ich-1)*800+(irec-1)*40+ifield) |
valeur associée au champ ich située à l’enregistrement irec et pour le champ ifield |
“.FID_LOC” : S V I#
Cet objet contient pour chaque champ, 5 couples de valeurs entières permettant de localiser à l’intérieur du dataset, le numero d’ordre, l’instant, la fréquence … La première valeur indique le n° de l’enregistrement où est stockée l’information et la deuxième valeur indique sa position.
v(1)v(2) |
= N° de l’enregistrement = Position |
Numéro d’ordre |
|
v(3)v(4) |
= N° de l’enregistrement = Position |
Instant |
Champ n°1 |
v(5)v(6) |
= N° de l’enregistrement = Position |
Fréquence |
|
v(7)v(8) |
= N° de l’enregistrement = Position |
Nume_mode |
|
v(9)v(10) |
= N° de l’enregistrement = Position |
Mass_gene |
|
v(11)v(13) |
= N° de l’enregistrement = Position |
Numéro d’ordre |
|
v(13)v(14) |
= N° de l’enregistrement = Position |
Instant |
Champ n°2 |
… |
“.FID_CMP” : S V K8#
Cet objet contient pour chaque champ les composantes de la grandeur à lire.
v(1) |
DX |
|
v(2) |
DY |
|
v(3) |
DZ |
Champ n°1 |
v(4) |
DRX |
|
v(5) |
DRY |
|
v(6) |
DRZ |
|
v(1001) |
EPXX |
|
v(1002) |
EPYY |
|
v(1003) |
EPZZ |
Champ n°2 |
v(1004) |
EPXY |
|
v(1005) |
EPXZ |
|
v(1006) |
EPYZ |
|
… |
||
… |
“.FID_NBC” : S V I#
Cet objet contient pour chaque champ le nombre de composantes à lire.
Structure des datasets#
La structure générale des datasets résultats 55, 57et 2414exploités par la commande LIRE_RESU est composée de 2 parties :
Partie A : entête contenant des informations générales,
Partie B : contient les valeurs.
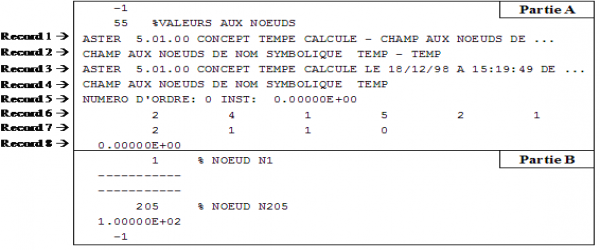
Figure 4-a : Dataset 55 (exemple)
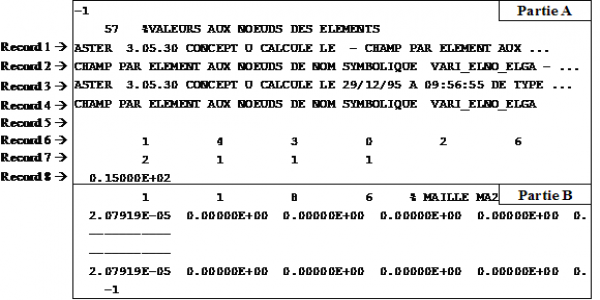
Figure 4-b : Dataset 57 (exemple)

Figure 4-c : Dataset 2414 (exemple)
Valeurs par défaut#
Les valeurs par défaut stockées dans la structure de données FORMAT_IDEAS sont présentées dans le document d’utilisation [U2.26.03].
Exemples#
Dans ce paragraphe, nous présentons deux exemples :
Exemple A : utilisation des critères de recherche par défaut pour lire les résultats,
Exemple B : utilisation des critères de recherche utilisateur pour lire les résultats.
Pour chacun de ces exemples nous donnons la syntaxe de la commande LIRE_RESU ainsi que le contenu de la structure de données FORMAT_IDEAS.
Exemple A : critères de recherche par défaut
Syntaxe de la commande LIRE_RESU
INIT = LIRE_RESU ( MAILLAGE = m ,
UNITE = 19 ,
FORMAT = 'IDEAS',
TYPE_RESU = 'EVOL_NOLI',
NOM_CHAM = ('DEPL'),
INST = 15. ,
)
Contenu de la SD FORMAT_IDEAS (valeur par défaut)
FORMAT_IDEAS |
||||||
.’FID_NOM’ |
DEPL |
|||||
.’FID_NUM’ |
55 |
|||||
.’FID_PAR‘(1) |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
1 |
4 |
3 |
8 |
2 |
6 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
… |
||||||
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
… |
||||||
… |
||||||
‘.FID_LOC’ |
7 |
4 |
8 |
1 |
9999 |
9999 |
‘.FID_CMP’ |
‘DX’ |
‘DY’ |
‘DZ’ |
‘DRX’ |
‘DRY’ |
‘DRZ’ |
Lors de la recherche du dataset, le nombre 9999est un joker permettant d’ignorer la valeur lue dans l’entête.
Exemple B : critères de recherchedéfini par l’utilisateur.
Syntaxe de la commande LIRE_RESU
INIT = LIRE_RESU ( MODELE = mo , UNITE = 19 , FORMAT = “IDEAS”, TYPE_RESU = “EVOL_NOLI”, NOM_CHAM = (“15”) , INST = 15. , FORMAT_IDEAS = _F ( NOM_CHAM = “DEPL”, NUME_DATASET = 55, RECORD_6 = (3,1,9999,4,2,3), POSI_ORDRE = (8,4), POSI_INST = (7,9999), CMP = (“DX”,”DY”,”DZ”), ) )
Contenu de la SD FORMAT_IDEAS (valeurs par défaut)
FORMAT_IDEAS |
||||||
.’FID_NOM’ |
DEPL |
|||||
.’FID_NUM’ |
55 |
|||||
.’FID_PAR‘(1) |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
3 |
1 |
9999 |
4 |
2 |
3 |
|
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
… |
||||||
9999 |
9999 |
9999 |
9999 |
9999 |
9999 |
|
… |
||||||
… |
||||||
‘.FID_LOC’ |
8 |
4 |
7 |
1 |
9999 |
9999 |
‘.FID_CMP’ |
‘DX’ |
‘DY’ |
‘DZ’ |
‘XXX’ |
‘XXX’ |
‘XXX’ |